Learn more about Search Results huggingface.co - Page 13

- You may be interested
- 🤗 APIのお客様のためにTransformerの推論...
- このスペースを見る:AIを使用してリスク...
- 「光子チップ ‘レゴのようにはめ込...
- 「アメリカの機械学習エンジニアの給与」
- 「より良い機械学習システムの構築 –...
- マシンラーニングに取り組むため、プライ...
- 説明可能なAI:ブラックボックスモデルの解明
- 「コンプライアンス自動化標準ソリューシ...
- ExcelのVBAを使用してプロジェクトの更新...
- 『React開発の向上:ChatGPTの力を解き放...
- 「365データサイエンスは、11月20日まで無...
- 「PythonでCuPyを使ってGPUのパワーを最大...
- 「AIプロジェクトが、アルゼンチンの軍事...
- ランダムウォークタスクにおける時差0(Tem...
- 人間だけが解決できるAIの課題
機械学習の時代がコードとして到来しました
2021年版のState of AIレポートが先週発表されました。そして、Kaggle State of Machine Learning and Data Science Surveyも同様です。これらのレポートには学びや議論の余地がたくさんありますが、いくつかのポイントが私の注意を引きました。 「AIはますます国家の電力網やパンデミック中の自動スーパーマーケットの倉庫計算など、ミッションクリティカルなインフラに適用されています。しかし、成熟度が急速に成長する展開の巨大さに追いついているかどうかについては疑問があります。」 機械学習を活用したアプリケーションがITのあらゆる分野に広がっていることは否定できません。しかし、それは企業や組織にとってどういう意味を持つのでしょうか?どのように堅牢な機械学習ワークフローを構築すれば良いのでしょうか?私たちは皆、100人のデータサイエンティストを採用すべきなのでしょうか?それとも100人のDevOpsエンジニアを採用すべきなのでしょうか? 「トランスフォーマーは、自然言語処理だけでなく、音声、コンピュータビジョン、さらにはタンパク質の構造予測など、機械学習の一般的なアーキテクチャとして登場しています。」 古参の人々は、ITには銀の弾丸はないということを痛感してきました。それでも、トランスフォーマーのアーキテクチャは、さまざまな機械学習タスクにおいて非常に効率的です。しかし、機械学習の革新の猛烈なペースにどうやってついていけば良いのでしょうか?これらの最先端モデルを活用するためには、本当に専門的なスキルが必要なのでしょうか?それとももっと短い道でビジネス価値を創出する方法があるのでしょうか? さて、私の考えはこうです。 マス向け機械学習! 機械学習はどこにでもあります、少なくともそうしようとしています。数年前、Forbesは「ソフトウェアが世界を食べた、今度はAIがソフトウェアを食べる」と書きましたが、これは実際にはどういう意味なのでしょうか?もし、それが機械学習モデルが何千行もの化石化した旧式のコードを置き換えるべきだという意味なら、私は全面賛成です。邪悪なビジネスルールよ、死ね! では、機械学習が実際にソフトウェアエンジニアリングを置き換えるということでしょうか?現在、AIが生成したコードについて幻想が広がっており、バグやパフォーマンスの問題を見つけるなど、いくつかの技術は確かに興味深いものです。しかし、開発者を廃止することは考えるべきではありませんし、むしろ多くの開発者を力強くサポートするために取り組むべきです。そうすれば、機械学習はただの別の退屈なITのワークロードになるでしょう(退屈なテクノロジーは素晴らしいです)。言い換えれば、私たちが本当に必要としているのは、ソフトウェアが機械学習を食べることなのです! 今回も変わらない 私は長年にわたり、ソフトウェアエンジニアリングの10年以上前のベストプラクティスがデータサイエンスや機械学習にも適用されると主張してきました。バージョン管理、再利用性、テスト可能性、自動化、デプロイメント、モニタリング、パフォーマンス、最適化などです。しばらくは孤独だったのですが、予想外にGoogleの連携がありました: 「機械学習は、あなたが偉大な機械学習の専門家ではなく、偉大なエンジニアとして機械学習を行うべきです。」- 『機械学習のルール』、Google また、車輪を再発明する必要はありません。DevOpsの運動はこれらの問題を10年以上前に解決しました。今や、データサイエンスと機械学習コミュニティは、これらの実証済みのツールとプロセスを遅延なく採用し、適応させるべきです。これが唯一の方法であり、本番環境で堅牢でスケーラブルかつ繰り返し可能な機械学習システムを構築することができます。もしMLOpsと呼ぶことが助けになるのなら、それも構いません:別のバズワードについて議論するつもりはありません。…
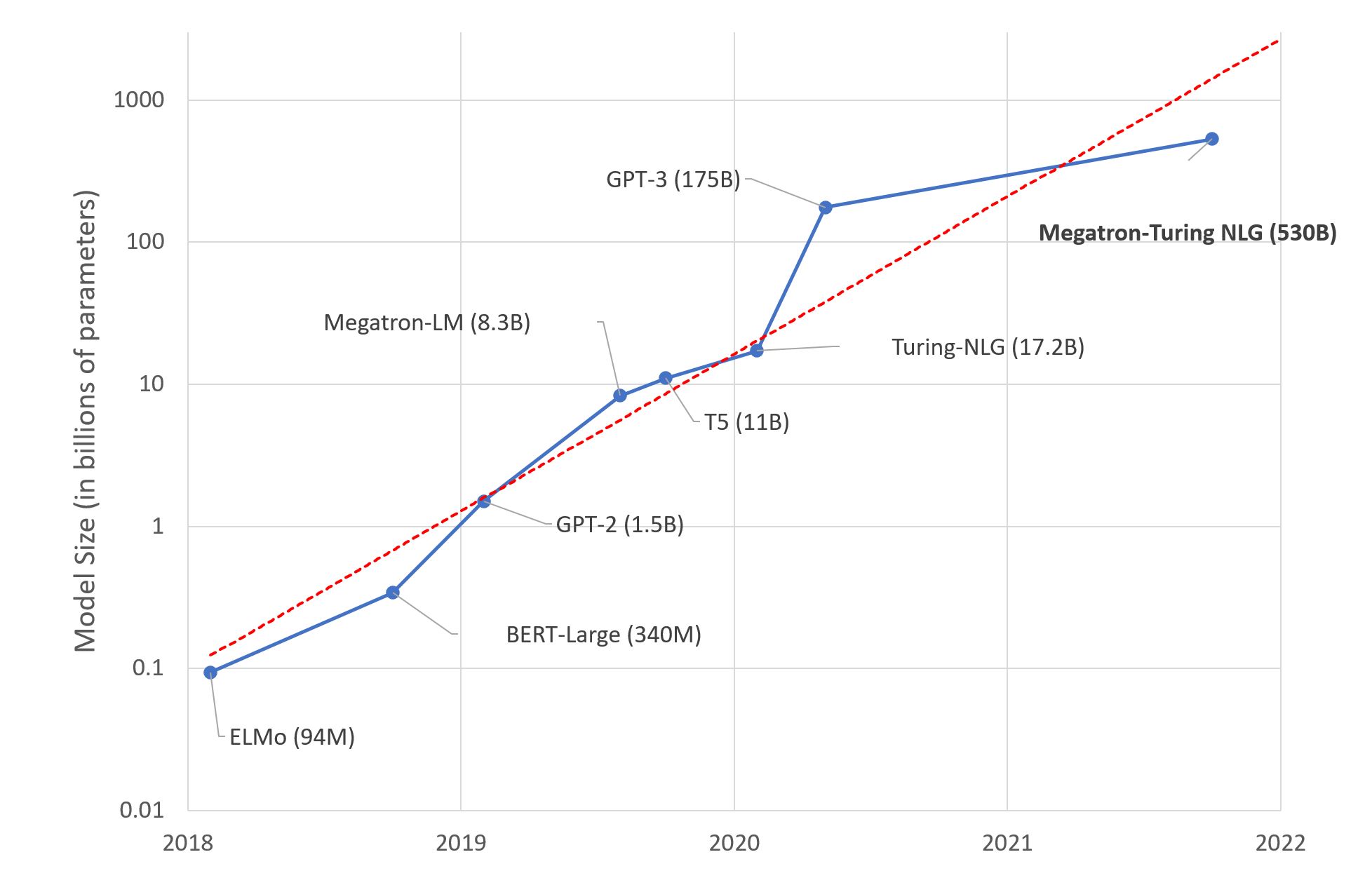
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
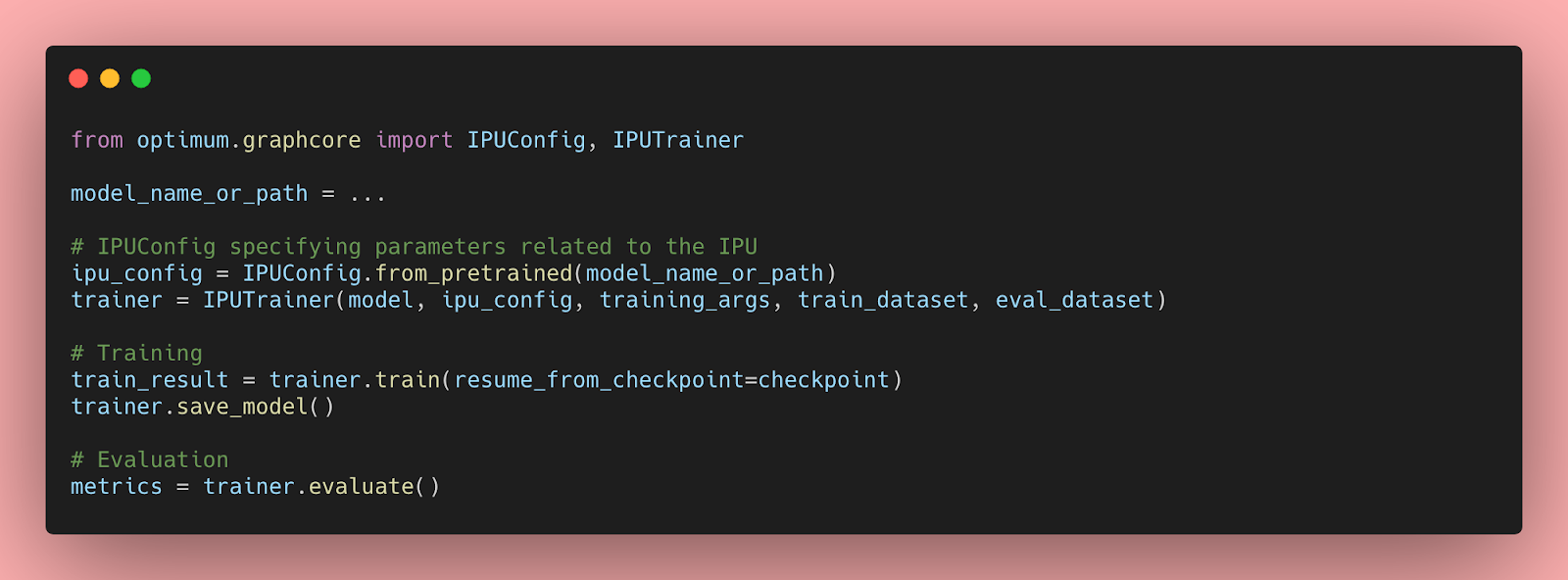
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

事例研究:Hugging Face InfinityとモダンなCPUを使用したミリ秒レイテンシー
はじめに 転移学習は、自然言語処理(NLP)から音声およびコンピュータビジョンのタスクまで、機械学習を新たな精度レベルに変えてきました。Hugging Faceでは、これらの新しい複雑なモデルと大規模なチェックポイントをできるだけ簡単にアクセス可能かつ利用可能にするために、努力して取り組んでいます。しかし、研究者やデータサイエンティストがTransformersの新しい世界に移行している一方で、これらの大規模で複雑なモデルを実稼働環境で大規模に展開することができる企業はほとんどありません。 主なボトルネックは、予測のレイテンシーであり、大規模な展開を実行するために高コストになり、リアルタイムのユースケースが実用的になりません。これを解決するには、どの機械学習エンジニアリングチームにとっても難しいエンジニアリング上の課題であり、ハードウェアまでモデルを最適化するための高度な技術の使用を必要とします。 Hugging Face Infinityでは、最も人気のあるTransformerモデルに対して、低レイテンシー、高スループット、ハードウェアアクセラレーションされた推論パイプラインを簡単に展開できるコンテナ化されたソリューションを提供しています。企業は、Transformersの精度と大容量展開に必要な効率性を、使いやすいパッケージで手に入れることができます。このブログ投稿では、最新世代のIntel Xeon CPU上で実行されるInfinityの詳細なパフォーマンス結果を共有したいと思います。 Hugging Face Infinityとは Hugging Face Infinityは、お客様が最新のTransformerモデルを最適化したエンドツーエンドの推論パイプラインを任意のインフラストラクチャ上で展開できるコンテナ化されたソリューションです。 Hugging Face Infinityには、2つの主要なサービスがあります: Infinityコンテナは、Dockerコンテナとして提供されるハードウェア最適化された推論ソリューションです。 Infinity Multiverseは、Hugging Face Transformerモデルをターゲットハードウェアに最適化するモデル最適化サービスです。Infinity MultiverseはInfinityコンテナと互換性があります。…

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

🤗 Transformersを使用して、Wav2Vec2を使用して大規模なファイルで自動音声認識を行う方法
Tl;dr: この投稿では、Connectionist Temporal Classification(CTC)アーキテクチャの特性を活用して、任意の長さのファイルやライブ推論中でも非常に良い品質の自動音声認識(ASR)を実現する方法を説明します。 Wav2Vec2は、音声認識のための人気のある事前学習モデルです。Meta AI Researchによって2020年9月にリリースされ、この新しいアーキテクチャは、自己教師あり事前学習における音声認識の進歩を促進しました(例:G. Ng et al.、2021年、Chen et al.、2021年、Hsu et al.、2021年、Babu et al.、2021年)。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは、現在月間25万回以上ダウンロードされています。 Wav2Vec2は、その核としてtransformersモデルを使用しており、transformersの注意点の1つは、通常、扱えるシーケンスの長さに限界があることです。それは位置符号化を使用するためではなく(この場合は違います)、単純にtransformersの注意コストが実際にはO(n²)となり、非常に大きなシーケンス長を使用すると複雑さやメモリの使用量が爆発します。したがって、非常に長いファイルでさえWav2Vec2を実行することはできません(たとえA100のような非常に大きなGPUを使用しても)。プログラムはクラッシュします。試してみましょう! pip install transformers from transformers…

Habana LabsとHugging Faceが提携し、Transformerモデルのトレーニングを加速化する
2022年4月12日、カリフォルニア州サンタクララとサンフランシスコ 深層学習によって駆動されるトランスフォーマーモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習タスクで最先端のパフォーマンスを発揮します。しかし、大規模なトレーニングは多くの計算能力を必要とするため、全体のプロセスが不必要に長く、複雑で、高コストになることがあります。 今日、高効率な専用のディープラーニングプロセッサを提供するパイオニアであるHabana® Labsと、トランスフォーマーモデルの開発元であるHugging Faceは、優れた品質のトランスフォーマーモデルのトレーニングをより簡単かつ迅速にするために協力しています。HabanaのSynapseAIソフトウェアスイートとHugging Face Optimumオープンソースライブラリの統合により、データサイエンティストや機械学習エンジニアはわずか数行のコードでHabanaプロセッサ上でトランスフォーマーモデルのトレーニングジョブを加速し、生産性を向上させながらトレーニングコストを削減することができます。 AmazonのEC2 DL1インスタンスとSupermicroのX12 Gaudi AI Training Serverを駆動するHabana Gaudiトレーニングソリューションは、同等のトレーニングソリューションに比べて最大40%低い価格/パフォーマンスを提供し、より少ない費用でより多くのトレーニングを実現します。Gaudiプロセッサごとに10の100ギガビットイーサネットポートを統合することにより、システムのスケーリングを容易かつ費用効果的に1から数千のGaudiに拡張することができます。HabanaのSynapseAI®は、Gaudiのパフォーマンスと使いやすさに最適化され、TensorFlowとPyTorchのフレームワークをサポートし、コンピュータビジョンと自然言語処理のアプリケーションに特化しています。 GitHubで60,000以上のスター、30,000以上のモデル、毎月数百万の訪問数を誇るHugging Faceは、オープンソースソフトウェアの歴史で最も急成長しているプロジェクトの一つであり、機械学習コミュニティの頼れる場所です。 Hugging Faceのハードウェアパートナープログラムにより、Gaudiの高度なディープラーニングハードウェアと究極のトランスフォーマーツールセットが提供されます。このパートナーシップにより、Habana Gaudiトレーニングトランスフォーマーモデルライブラリの急速な拡大が可能となり、自然言語処理、コンピュータビジョン、音声など、さまざまな顧客のユースケースにGaudiの効率性と使いやすさをもたらします。 「Gaudiトレーニングプラットフォームの効率性、使いやすさ、スケーラビリティの恩恵を受けるトランスフォーマーモデルの需要の増大に対応するために、Hugging Faceとその多くのオープンソース開発者とパートナーシップを結ぶことを楽しみにしています」とHabana Labsのソフトウェア製品マネージメント責任者であるSree Ganesanは述べています。 「Habana…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.