Learn more about Search Results documentation - Page 13

- You may be interested
- Pythonプロジェクトのセットアップ:パートV
- 「データは言語モデルの基盤です」
- メタAIは、リアルタイムに高品質の再照明...
- 3Dアーティストのヌルハン・イスマイルは...
- 「クロード2の探索:アントロピックの次世...
- 「人工知能(AI)とWeb3:どのように関連...
- 「AIプロジェクトが、アルゼンチンの軍事...
- 探索的データ解析:データセットの中に隠...
- 「ReactPyを使用して、フルスタックAIアプ...
- このAI研究は、高品質なビデオ生成のため...
- 「Databricks、MosaicMLおよびその他の最...
- プロデジーHFをご紹介します:Hugging Fac...
- ウェイモのMotionLMを紹介します:最新型...
- 「ゼロからLLMを構築する方法」
- リアルタイムでデータを理解する

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…

⚔️AI vs. AI⚔️は、深層強化学習マルチエージェント競技システムを紹介します
私たちは新しいツールを紹介するのを楽しみにしています: ⚔️ AI vs. AI ⚔️、深層強化学習マルチエージェント競技システム。 このツールはSpacesでホストされており、マルチエージェント競技を作成することができます。以下の3つの要素で構成されています: マッチメイキングアルゴリズムを使用してモデルの戦いをバックグラウンドタスクで実行するスペース。 結果を含むデータセット。 マッチ履歴の結果を取得し、モデルのELOを表示するリーダーボード。 ユーザーが訓練済みモデルをHubにアップロードすると、他のモデルと評価およびランキング付けされます。これにより、マルチエージェント環境で他のエージェントとの評価が可能です。 マルチエージェント競技をホストする有用なツールであるだけでなく、このツールはマルチエージェント環境での堅牢な評価技術でもあると考えています。多くのポリシーと対戦することで、エージェントは幅広い振る舞いに対して評価されます。これにより、ポリシーの品質を良く把握することができます。 最初の競技ホストであるSoccerTwos Challengeでどのように機能するか見てみましょう。 AI vs. AIはどのように機能しますか? AI vs. AIは、Hugging Faceで開発されたオープンソースのツールで、マルチエージェント環境での強化学習モデルの強さをランク付けするためのものです。 アイデアは、モデルを継続的に互いに対戦させ、その結果を使用して他のすべてのモデルと比較してパフォーマンスを評価し、ポリシーの品質を把握するための相対的なスキルの尺度を得ることです。従来のメトリクスを必要とせずに。 エージェントが特定のタスクや環境に提出される数が増えるほど、ランキングはより代表的になります。 競争環境での試合結果に基づいて評価を生成するために、私たちはELOレーティングシステムを基にランキングを作成することにしました。…

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…
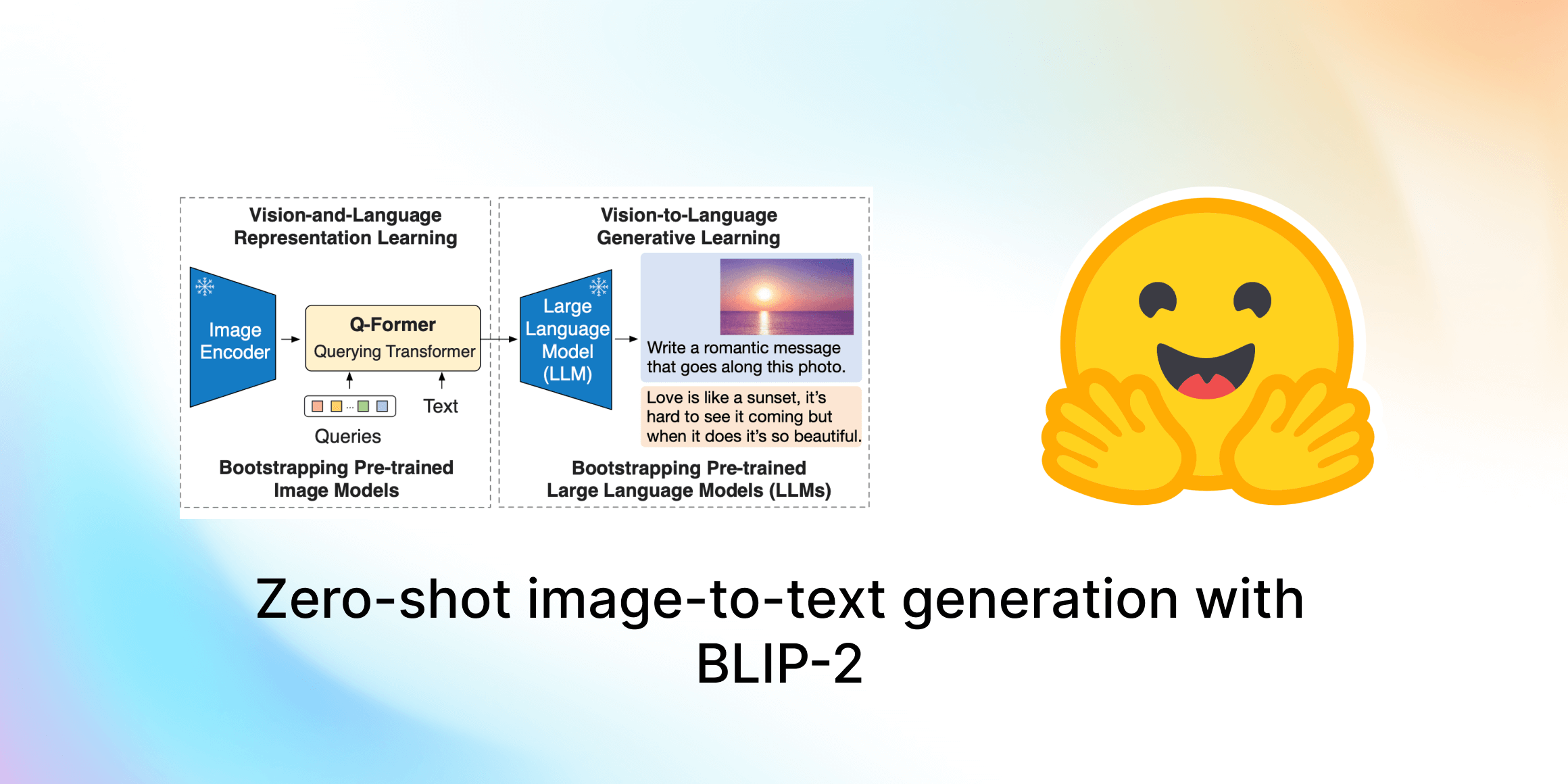
ゼロショット画像からテキスト生成 BLIP-2
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。 目次 はじめに BLIP-2の内部構造は? Hugging Face TransformersでのBLIP-2の使用 画像キャプショニング プロンプト付き画像キャプショニング ビジュアルな質問応答 チャットベースのプロンプト 結論 謝辞 はじめに 近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。 現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。 BLIP-2の内部構造は? BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。 Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています: 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。 テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。…

Swift 🧨ディフューザー – Mac用の高速安定拡散
Diffusers for Macを使用して、最新の拡散モデルによってテキストを美しい画像に簡単に変換できます。このネイティブアプリは、Hugging Face Hubへのコミュニティの貢献によって提供された最先端のテキストから画像へのモデルを活用し、高速なパフォーマンスのためにCore MLに変換されています。最新バージョンの1.1は、Mac App Storeで利用可能であり、パフォーマンスの大幅なアップグレードと使いやすいインターフェースの調整が行われています。これは将来の機能アップデートのための堅牢な基盤となっています。さらに、このアプリは完全にオープンソースであり、許容されるライセンスであるため、あなた自身でも構築することができます!詳細については、https://github.com/huggingface/swift-coreml-diffusers でGitHubリポジトリをご覧ください。 Diffusers for Macとは具体的には何ですか? Diffusersアプリ(App Store、ソースコード)は、Mac版の 🧨 diffusers ライブラリの対応アプリです。このライブラリはPythonとPyTorchで書かれており、モジュラーな設計を使用して拡散モデルのトレーニングと実行を行います。多くの異なるモデルとタスクをサポートし、高度に構成可能で最適化されています。Macでも実行できます。Apple Siliconでは、PyTorchの mps アクセラレータを使用します。 では、なぜネイティブのMacアプリを実行したいのでしょうか?その理由はいくつかあります: オリジナルのPyTorchモデルではなく、Core MLモデルを使用します。これは、Appleハードウェアの特定の最適化に対応する追加の最適化を可能にし、Core MLモデルはシステム内のすべての計算デバイス(CPU、GPU、ニューラルエンジン)で実行できます。PyTorchの…

大規模な言語モデルによるレッドチーミング
警告: この記事はレッドチーミングについてであり、そのためモデル生成の例が不快または不快なものである可能性があります。 大量のテキストデータで訓練された大規模な言語モデル(LLM)は、現実的なテキストを生成するのに非常に優れています。しかし、これらのモデルは、個人情報(社会保障番号など)の公開や誤情報、偏見、憎悪、有害なコンテンツの生成など、望ましくない振る舞いをしばしば示します。たとえば、GPT3の以前のバージョンは、性差別的な振る舞い(以下参照)やムスリムに対する偏見を示すことが知られていました。 LLMを使用する際にこのような望ましくない結果を発見した場合、Generative Discriminator Guided Sequence Generation(GeDi)やPlug and Play Language Models(PPLM)などの戦略を開発してそれらからそれを逸らすことができます。以下は、同じプロンプトを使用してGPT3の生成を制御するためにGeDiを使用した例です。 最近のGPT3のバージョンでも、プロンプトインジェクションによる攻撃を受けると同様に不快なテキストが生成され、その結果、下流のアプリケーションのセキュリティ上の懸念となる可能性があります。このブログで説明されています。 レッドチーミングは、望ましくない振る舞いを引き起こす可能性のあるモデルの脆弱性を引き出す評価の形式です。ジェイルブレイキングは、LLMがそのガードレールから逸脱するように操作されるレッドチーミングの別の言葉です。MicrosoftのチャットボットTay(2016年)やより最近のBingのチャットボットシドニーは、レッドチーミングを使用して基礎となるMLモデルの徹底的な評価の欠如がどれほど壊滅的な結果をもたらすかの実際の例です。レッドチームのアイデアの起源は、軍隊によって実施された対抗者シミュレーションやウォーゲームに遡ることができます。 レッドチーミングの目標は、モデルが有害なテキストを生成する可能性が高いテキストを生成するようにするプロンプトを作成することです。レッドチーミングは、MLのより一般的に知られた評価形式である敵対的攻撃といくつかの類似点と相違点を共有しています。その類似点は、レッドチーミングと敵対的攻撃が実際のユースケースで望ましくないコンテンツを生成するためにモデルを「攻撃」または「だます」という共通の目標を持っていることです。ただし、敵対的攻撃は人間には理解しにくい場合があります。たとえば、各プロンプトに「aaabbbcc」という文字列を接頭辞として付けると、モデルのパフォーマンスが低下するためです。Wallace et al.、’19では、さまざまなNLP分類および生成タスクにおけるそのような攻撃の多くの例が議論されています。一方、レッドチーミングのプロンプトは通常、通常の自然言語のプロンプトと似ています。 レッドチーミングは、ユーザーの不快な体験を引き起こしたり、悪意を持つユーザーによる暴力やその他の違法な活動を支援する可能性があるモデルの制限を明らかにすることができます。レッドチーミングからの出力(敵対的攻撃と同様)は、一般にモデルを訓練して、有害な結果を引き起こす可能性を低くするか、またはそれから逸らすために使用されます。 レッドチーミングは、可能なモデルの障害物の創造的な考えを必要とするため、リソースを消費する問題です。回避策として、与えられたプロンプトにオフェンシブな生成を引き起こす可能性のあるトピックやフレーズを予測するために訓練された分類器をLLMに追加することができます。このような戦略は慎重な方向に進むでしょう。しかし、それは非常に制限的であり、モデルを頻繁に回避的にする原因となります。したがって、モデルが役立つこと(指示に従うこと)と無害であること(少なくとも有害な行動を引き起こしにくいこと)の間には緊張があります。 レッドチームは、ハードループ内の人間または有害な出力をテストするために別のLMをテストしているLMです。安全性とアライメントのためにファインチューニングされたモデルに対してレッドチーミングプロンプトを作成するには、Ganguli et al.、’22で説明されているような悪意のあるキャラクターとして振る舞うようにLLMに指示する役割プレイ攻撃の形で創造的な思考が必要です。モデルに自然言語の代わりにコードで応答するように指示することも、モデルの学習バイアスを明らかにすることができます。 さらなる例については、このツイートスレッドをご覧ください。 ChatGPT自体によるLLMのジェイルブレイキングのアイデアのリストは次のとおりです。…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…

時間をかけて生存者を助け、機械学習を利用して競争する
2023年2月6日、トルコ南東部でマグニチュード7.7と7.6の地震が発生し、10の都市に影響を及ぼし、2月21日現在で4万2000人以上が死亡し、12万人以上が負傷しました。 地震の数時間後、プログラマーのグループが「アフェタリタ」と呼ばれるアプリケーションを展開するためのDiscordサーバーを立ち上げました。このアプリケーションは、捜索救助チームとボランティアが生存者を見つけて支援するために使用されます。このようなアプリの必要性は、生存者が自分の住所や必要なもの(救助を含む)をテキストのスクリーンショットとしてソーシャルメディアに投稿したことから生じました。一部の生存者は、自分が生きていることと救助を必要としていることを、ツイートで伝え、それにより親族が知ることができました。これらのツイートから情報を抽出する必要があり、私たちはこれらを構造化されたデータに変換するためのさまざまなアプリケーションを開発し、展開するために時間との競争をしました。 Discordサーバーに招待されたとき、私たちは(ボランティアとして)どのように運営し、何をするかについてかなりの混乱がありました。私たちは共同でモデルをトレーニングするために、モデルとデータセットのレジストリが必要でした。私たちはHugging Faceの組織アカウントを開設し、MLベースのアプリケーションを受け取り、情報を処理するためのプルリクエストを通じて共同作業しました。 他のチームのボランティアから、スクリーンショットを投稿し、スクリーンショットから情報を抽出し、それを構造化してデータベースに書き込むアプリケーションの需要があることを聞きました。私たちは、与えられた画像を取得し、まずテキストを抽出し、そのテキストから名前、電話番号、住所を抽出し、これらの情報を権限付与された当局に提供するデータベースに書き込むアプリケーションの開発を開始しました。さまざまなオープンソースのOCRツールを試した後、OCR部分には「easyocr」を使用し、このアプリケーションのインターフェースの構築には「Gradio」を使用しました。OCRからのテキスト出力は、トランスフォーマーベースのファインチューニングされたNERモデルを使用して解析されます。 アプリケーションを共同で改善するために、Hugging Face Spacesにホストし、アプリケーションを維持するためのGPUグラントを受け取りました。Hugging Face HubチームはCIボットをセットアップしてくれたので、プルリクエストがSpaceにどのように影響を与えるかを見ることができ、プルリクエストのレビュー中に役立ちました。 その後、さまざまなチャンネル(Twitter、Discordなど)からラベル付けされたコンテンツが提供されました。これには、助けを求める生存者のツイートの生データと、それらから抽出された住所と個人情報が含まれていました。私たちは、まずはHugging Face Hub上のオープンソースのNLIモデルと、クローズドソースの生成モデルエンドポイントを使用したフューショットの実験から始めました。私たちは、xlm-roberta-large-xnliとconvbert-base-turkish-mc4-cased-allnli_trというモデルを試しました。NLIモデルは特に役立ちました。候補ラベルを使用して直接推論でき、データのドリフトが発生した際にラベルを変更できるため、生成モデルはバックエンドへの応答時にラベルを作り上げる可能性があり、不一致を引き起こす可能性がありました。最初はラベル付けされたデータがなかったので、何でも動くでしょう。 最終的に、私たちは独自のモデルを微調整することにしました。1つのGPUでBERTのテキスト分類ヘッドを微調整するのに約3分かかります。このモデルをトレーニングするためのデータセットを開発するためのラベリングの取り組みがありました。モデルカードのメタデータに実験結果を記録し、後でどのモデルを展開するかを追跡するためのリーダーボードを作成しました。ベースモデルとして、bert-base-turkish-uncasedとbert-base-turkish-128k-casedを試しましたが、bert-base-turkish-casedよりも優れたパフォーマンスを発揮することがわかりました。リーダーボードはこちらでご覧いただけます。 課題とデータクラスの不均衡を考慮し、偽陰性を排除することに焦点を当て、すべてのモデルの再現率とF1スコアをベンチマークするためのスペースを作成しました。これには、関連するモデルリポジトリにメタデータタグdeprem-clf-v1を追加し、このタグを使用して記録されたF1スコアと再現率を自動的に取得し、モデルをランク付けしました。漏れを防ぐために別のベンチマークセットを用意し、モデルを一貫してベンチマークしました。また、各モデルをベンチマークし、展開用の各ラベルに対して最適な閾値を特定しました。 NERモデルを評価するために、データラベラーが改善された意図データセットを提供するために取り組んでいるため、クラウドソーシングの取り組みとしてNERモデルを評価するためのラベリングインターフェースを設定しました。このインターフェースでは、ArgillaとGradioを使用して、ツイートを入力し、出力を正しい/正しくない/曖昧などのフラグで示すことができます。 後で、データセットは重複を排除してさらなる実験のベンチマークに使用されました。 機械学習の別のチームは、特定のニーズを得るために生成モデル(ゲート付きAPIの背後)と連携し、テキストとして自由なテキストを使用し、各投稿に追加のコンテキストとしてテキストを渡すためにAPIエンドポイントを別のAPIとしてラップし、クラウドに展開しました。少数のショットのプロンプティングをLLMsと組み合わせて使用することで、急速に変化するデータのドリフトの存在下で細かいニーズに対応するのに役立ちます。調整する必要があるのはプロンプトだけであり、ラベル付けされたデータは必要ありません。 これらのモデルは現在、生存者にニーズを伝えるためにボランティアや救助チームがヒートマップ上のポイントを作成するために本番環境で使用されています。 Hugging Face Hubとエコシステムがなかったら、私たちはこのように迅速に協力し、プロトタイプを作成し、展開することはできませんでした。以下は住所認識および意図分類モデルのためのMLOpsパイプラインです。 このアプリケーションとその個々のコンポーネントには何十人ものボランティアがおり、短期間でこれらを提供するために寝ずに働きました。 リモートセンシングアプリケーション…

UnityゲームをSpaceにホストする方法
UnityゲームをHugging Face Spaceでホストできることを知っていますか?いいえ?そうです、できます! Hugging Face Spacesは、デモを構築、ホスト、共有するための簡単な方法です。通常は機械学習のデモに使用されますが、プレイ可能なUnityゲームもホストできます。以下にいくつかの例を示します。 Huggy Farming Game Unity APIデモ 次に、Spaceで独自のUnityゲームをホストする方法を説明します。 ステップ1:静的HTMLテンプレートを使用してSpaceを作成する まず、Hugging Face Spacesに移動してスペースを作成します。 “Static HTML”テンプレートを選択し、スペースに名前を付けて作成します。 ステップ2:Gitを使用してスペースをクローンする Gitを使用して、新しく作成したスペースをローカルマシンにクローンします。ターミナルまたはコマンドプロンプトで次のコマンドを実行することでこれを行うことができます。 git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ステップ3:Unityプロジェクトを開く…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.