Learn more about Search Results arXiv - Page 13

- You may be interested
- 「今日、何を見たと思う?このAIモデルは...
- LayoutLMv3を使用してビジネス文書から主...
- 「AIディープフェイクがスロバキアの選挙...
- 「ChatGPTを使用してテキストをPowerPoint...
- 役に立つセンサーがAI in a Boxを立ち上げる
- ナノタトゥーは、電池やワイヤーが必要あ...
- 『Retrieval-Augmented GenerationとSelf-...
- 2024年、データサイエンティストとして、...
- 「Hugging Face AutoTrainを使用して、LLM...
- ケシャヴ・ピンガリ氏がACM-IEEE CSケン・...
- 「GeoPandasを使ったPythonにおける地理空...
- 「Gradio-liteと出会う:Pyodideを使用し...
- 神経協調フィルタリングでレコメンデーシ...
- 「Matplotlibの謎を解き明かす」
- 「VRは私たちを健康にするために自然の力...

ChatGPTのためのエニグマ:PUMAは、LLM推論のための高速かつ安全なAIアプローチを提案するものです
大規模言語モデル(LLM)は人工知能の領域で革命を起こしています。ChatGPTのリリースはLLMの時代の火付け役となり、それ以来、これらのモデルはますます改善されてきました。これらのモデルは膨大な量のデータによって可能にされ、言語理解のマスタリングから複雑なタスクの簡素化まで、その能力に感動させられました。 ChatGPTにはさまざまな代替案が提案されており、日々改善されています。特定のタスクではChatGPTを凌駕することさえあります。LLaMa、Claudia、Falconなど、新しいLLMモデルがChatGPTの座を狙っています。 しかし、ChatGPTが今でも圧倒的に最も人気のあるLLMであることは疑いありません。お気に入りのAIアプリがおそらくChatGPTのラッパーである可能性は非常に高いです。ただし、セキュリティの観点から考えると、それは本当にプライベートで安全なのでしょうか? OpenAIはAPIデータのプライバシー保護を深く考えていることを保証していますが、同時に多くの訴訟に直面しています。彼らはモデルの使用のプライバシーとセキュリティを守るために非常に努力しているにもかかわらず、これらのモデルは制御するには強力すぎる場合があります。 したがって、プライバシーやセキュリティに関する懸念なしにLLMのパワーを利用するにはどうすればよいでしょうか?機密データを損なうことなく、これらのモデルの能力を利用するにはどうすればよいでしょうか?それでは、PUMAにお会いしましょう。 PUMAは、データの機密性を保ちながら、Transformerモデルのセキュアで効率的な評価を可能にするために設計されたフレームワークです。これはセキュアなマルチパーティ計算(MPC)を効率的なTransformer推論と統合しています。 根本的には、PUMAはGeLUやSoftmaxなどのTransformerモデル内の複雑な非線形関数を近似する新しい技術を導入しています。これらの近似は、精度を保ちつつ効率を大幅に向上させるようにカスタマイズされています。以前の方法とは異なり、パフォーマンスを犠牲にしたり、複雑な展開戦略につながったりすることなく、PUMAのアプローチは両方の世界をバランスさせ、実世界のアプリケーションに必要な正確な結果と効率を維持します。 PUMAは、モデル所有者、クライアント、計算パーティの3つの重要なエンティティを導入しています。各エンティティはセキュアな推論プロセスで重要な役割を果たします。 モデル所有者は訓練されたTransformerモデルを提供し、クライアントは入力データを提供し、推論結果を受け取ります。計算パーティは安全な計算プロトコルを共同で実行し、データとモデルの重みがプロセス全体で安全に保護されることを確保します。 PUMAの推論プロセスの基本的な原則は、関与するエンティティのプライバシーを保護するために、入力データと重みの機密性を維持することです。 セキュア埋め込みは、セキュアな推論プロセスの基本的な側面であり、トークン識別子を使用してワンホットベクトルを生成することが伝統的に行われてきました。しかし、PUMAは、Transformerモデルの標準的なワークフローに密接に従うセキュアな埋め込みデザインを提案しています。この簡略化されたアプローチにより、セキュリティ対策がモデルの固有のアーキテクチャと干渉せず、実践的なアプリケーションでのセキュアモデルの展開が容易になります。 PUMAで使用されるセキュアなGeLUとLayerNormプロトコルの概要。出典: https://arxiv.org/pdf/2307.12533.pdf さらに、セキュアな推論における大きな課題は、GeLUやSoftmaxなどの複雑な関数を、計算効率と精度のバランスを取りながら近似することです。 PUMAは、これらの関数の特性を活用して、より正確な近似を設計することで、近似の精度を大幅に向上させると同時に、ランタイムと通信コストを最適化しています。 最後に、Transformerモデル内で重要な操作であるLayerNormは、分割-平方根の計算式による一意の課題を抱えています。PUMAは、セキュアなプロトコルを使用して操作をスマートに再定義することで、LayerNormの計算が安全かつ効率的に行われるようにしています。 PUMAの最も重要な特徴の一つは、シームレスな統合です。このフレームワークは、大規模なモデルアーキテクチャの変更を必要とせず、Transformerモデルのエンドツーエンドの安全な推論を容易にします。これは、最小限の努力で事前学習済みのTransformerモデルを活用できることを意味します。Hugging Faceや他のソースからダウンロードした言語モデルであっても、PUMAはシンプルな方法で処理します。元のワークフローに合わせており、複雑な再トレーニングや変更を要求しません。
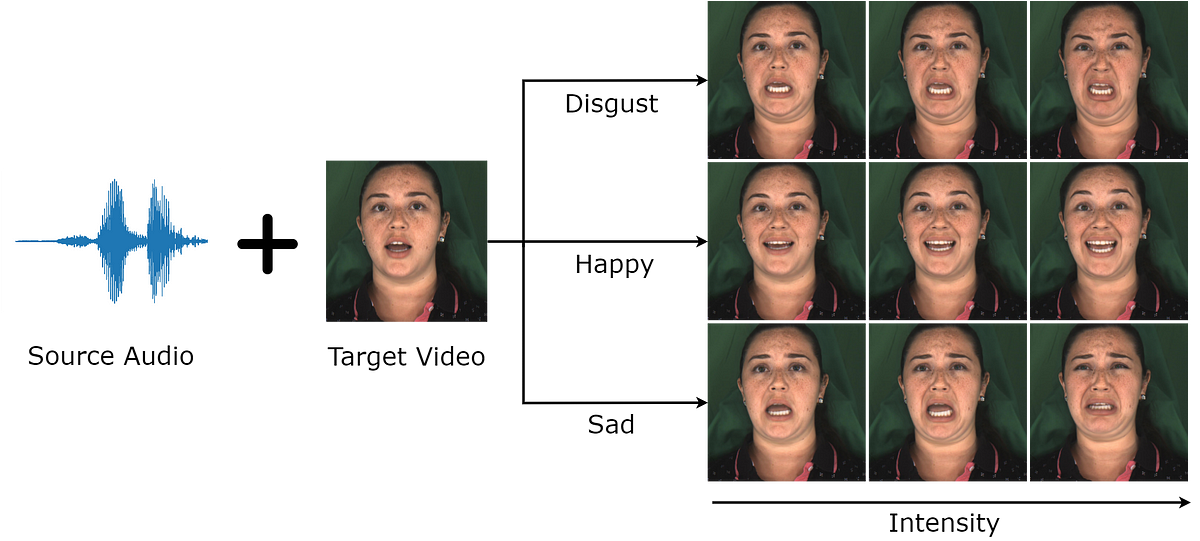
「読むアバター:リアルな感情制御可能な音声駆動のアバター」
「既存の音声駆動型のディープフェイクの重要な制約の1つは、スタイル属性をより制御できる能力の必要性です理想的には、これらの側面を変えたいと思います例えば、…」

感情の解読:EmoTXによる感情と心の状態の明らかにする、新しいTransformer-Powered AIフレームワーク
映画は物語や感情の中でも最も芸術的な表現の一つです。たとえば、「ハッピネスの追求」では、主人公が別れやホームレスなどの低い状況から、一流の仕事を達成するなどの高い状況まで、様々な感情を経験します。これらの強烈な感情は、観客を引き込み、キャラクターの旅に共感することができます。人工知能(AI)の領域でこのような物語を理解するためには、キャラクターの感情や心理状態の変化を監視することが重要です。この目標は、MovieGraphsからの注釈を活用し、シーンを観察し、対話を分析し、キャラクターの感情や心理状態に関する予測を行うことで追求されます。 感情の対象は歴史を通じて幅広く探求されてきました。古代ローマのキケロの四分類から現代の脳研究まで、感情の概念は常に人類の関心を引きつけてきました。心理学者たちは、プルチキの車輪やエクマンの普遍的な顔の表情などの構造を導入することで、さまざまな理論的な枠組みを提供しました。感情は、感情、行動、認知の側面と身体的な状態を包括する心理状態にさらに分類されます。 最近の研究では、Emoticとして知られるプロジェクトが視覚コンテンツの処理時に26の異なる感情ラベルクラスターを導入しました。このプロジェクトは、画像が平和や関与など、同時にさまざまな感情を伝える可能性があることを許容するマルチラベルのフレームワークを提案しました。従来のカテゴリーのアプローチに代わり、この研究では連続的な3つの次元(快感、興奮、支配)も組み込まれています。 正確な感情の予測には、さまざまなコンテキストモダリティを網羅する必要があります。マルチモーダルな感情認識の主要なアプローチには、対話の中での感情認識(ERC)が含まれます。これにより、対話の交換ごとに感情を分類することができます。また、映画クリップの短いセグメントに対して単一の快感-活動スコアを予測するアプローチもあります。 映画のシーンレベルでの操作は、特定の場所で発生し、特定のキャストを含む、30から60秒の短い時間枠内で物語を伝える一連のショットと一緒に作業することを意味します。これらのシーンは個々の対話や映画クリップよりも長い時間を提供します。この目標は、シーン内のすべてのキャラクターの感情と心理状態、およびシーンレベルでのラベルの蓄積を予測することです。時間の長いウィンドウが与えられるため、この推定は自然にマルチラベル分類アプローチにつながります。キャラクターは同時に複数の感情(好奇心と混乱など)を伝える場合がありますし、他者との相互作用による遷移(たとえば、心配から穏やかに変化する)も起こる可能性があるためです。 さらに、感情は心理状態の一部として広く分類されることができますが、この研究では、キャラクターの態度(驚き、悲しみ、怒りなど)から明確に認識できる外部の感情と、相互作用や対話を通じてのみ識別可能な潜在的な心理状態(礼儀、決意、自信、助け)とを区別しています。著者たちは、広範な感情ラベル空間で効果的に分類するためには、マルチモーダルなコンテキストを考慮する必要があると主張しています。そのため、彼らはビデオフレーム、対話の発話、キャラクターの外観を同時に組み込むモデルであるEmoTxを提案しています。 このアプローチの概要は、以下の図に示されています。 https://arxiv.org/abs/2304.05634 EmoTxは、キャラクターごとおよび映画シーンごとに感情を特定するためにTransformerベースのアプローチを使用しています。プロセスは、初期のビデオの前処理と特徴抽出パイプラインから始まり、データから関連する表現を抽出します。これらの特徴には、ビデオデータ、キャラクターの顔、テキストの特徴が含まれます。この文脈では、モダリティ、キャラクターの列挙、および時間的なコンテキストに基づいて区別するための適切な埋め込みがトークンに導入されます。さらに、個々の感情の分類器として機能するトークンが生成され、シーンまたは特定のキャラクターにリンクされます。これらの埋め込まれたトークンは、線形層を使用して組み合わされ、Transformerエンコーダに供給されます。これにより、さまざまなモダリティ間での情報の統合が可能になります。この方法の分類コンポーネントは、以前のTransformerを用いたマルチラベル分類に関する研究から着想を得ています。 「EmoTx」の振る舞いの例は、著者によって公開され、「フォレスト・ガンプ」のシーンに関連しています。以下の図に報告されています。 https://arxiv.org/abs/2304.05634 これは、適切なマルチモーダルデータからビデオクリップに登場する被験者の感情を予測する、新しいAIベースのアーキテクチャ「EmoTx」の概要でした。興味がある場合は、以下に引用されたリンクを参照して詳細をご覧ください。
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキュメントを迅速に処理するための方法を提供しますか?この記事では、トランスフォーマーを使用して、テーブルの存在だけでなく、テーブルの構造を画像から認識する方法を見ていきます。これは、2つの異なるモデルによって実現されます。1つはドキュメント内のテーブルの検出のためのもので、もう1つはテーブル内の個々の行と列を認識するためのものです。 学習目標 画像上のテーブルの行と列を検出する方法 Table TransformersとDetection Transformer(DETR)の概要 PubTables-1Mデータセットについて Table Transformerでの推論の実行方法 ドキュメント、記事、PDFファイルは、しばしば重要なデータを伝えるテーブルを含む貴重な情報源です。これらのテーブルから情報を効率的に抽出することは、異なるフォーマットや表現の間の課題により複雑になる場合があります。これらのテーブルを手動でコピーまたは再作成するのは時間がかかり、ストレスがかかることがあります。PubTables-1Mデータセットでトレーニングされたテーブルトランスフォーマーは、テーブルの検出、構造の認識、および機能分析の問題に対処します。 この記事はData Science Blogathonの一環として公開されました。 この方法はどのように実現されたのですか? これは、PubTables-1Mという名前の大規模な注釈付きデータセットを使用して、記事などのドキュメントや画像を検出するためのトランスフォーマーモデルであるTable Transformerによって実現されました。このデータセットには約100万のパラメータが含まれており、いくつかの手法を用いて実装されており、モデルに最先端の感触を与えています。効率性は、不完全な注釈、空間的な整列の問題、およびテーブルの構造の一貫性の課題に取り組むことで達成されました。モデルとともに公開された研究論文では、テーブルの構造認識(TSR)と機能分析(FA)のジョイントモデリングにDetection Transformer(DETR)モデルを活用しています。したがって、DETRモデルは、Microsoft Researchが開発したTable Transformerが実行されるバックボーンです。DETRについてもう少し詳しく見てみましょう。 DEtection TRansformer(DETR) 前述のように、DETRはDEtection TRansformerの略であり、エンコーダーデコーダートランスフォーマーを使用したResNetアーキテクチャなどの畳み込みバックボーンから構成されています。これにより、オブジェクト検出のタスクを実行する潜在能力を持っています。DETRは、領域提案、非最大値抑制、アンカー生成などの複雑なモデル(Faster…

AIが私たちのコーディング方法を変えていく方法
簡単に言うと、この記事では、AIと仕事に関する私の最新の研究の要約(AIが生産性に与える影響を探りながら、長期的な影響についての議論を展開する)を見つけることができます...

『見て学ぶ小さなロボット:このAIアプローチは、人間のビデオデモンストレーションを使用して、ロボットに汎用的な操作方法を教える』
ロボットは常にテックの世界で注目の的となってきました。彼らは常にSF映画、子供向け番組、書籍、ディストピアの小説などで場所を見つけました。それほど昔ではなく、彼らはただのSFの夢でしたが、今ではどこにでもいて、産業を再構築し、未来の一端を見せてくれています。工場から宇宙空間まで、ロボットが主役になり、今までにない精度と適応性を披露しています。 ロボティクスの風景では、常に同じ目標がありました:人間の器用さを反映することです。人間の操作能力を反映するための改善の探求は、興奮するような進展をもたらしました。アイインハンドカメラの統合により、従来の静止型の第三者カメラの補完または代替として、大きな進歩がなされています。 アイインハンドカメラは大きな可能性を秘めていますが、エラーフリーな結果を保証するわけではありません。ビジョンベースのモデルは、変動する背景、可変光、物体の外観の変化など、現実世界の変動に苦労することがよくあり、脆弱性を引き起こします。 この課題に取り組むために、最近新しい一連の一般化技術が登場しました。ビジョンデータに頼る代わりに、多様なロボットデモデータセットを使用してロボットに特定のアクションポリシーを教えるという方法です。ある程度は機能しますが、大きな問題があります。それは高価です、本当に高価です。実際のロボットセットアップでこのようなデータを収集することは、キネステティックな教育やVRヘッドセットやジョイスティックを介したロボットのテレオペレーションなど、時間のかかる作業を意味します。 この高価なデータセットに頼る必要があるのでしょうか?ロボットの主な目標は人間を模倣することですから、なぜ人間のデモンストレーションビデオを使わないのでしょうか?これらのタスクを行う人間のビデオは、人間の機敏さのため、より費用対効果の高い解決策を提供します。これにより、ロボットをリセットしたり、ハードウェアのデバッグを行ったり、困難な再配置を行ったりする必要がなくなります。これにより、ビジョン中心のロボットマニピュレーターの一般化能力を大幅に向上させるための人間のビデオデモンストレーションを活用するという興味深い可能性が生まれます。 ただし、人間とロボットの領域間のギャップを埋めることは容易なことではありません。人間とロボットの外観の相違は、慎重な考慮が必要な分布シフトを導入します。このギャップを埋める新しい研究、「Giving Robots a Hand」について見てみましょう。 既存の方法では、第三者のカメラ視点を使用して、画像の変換、ドメイン間の不変な視覚表現、および人間とロボットの状態に関するキーポイント情報を活用するドメイン適応戦略を使用して、この課題に取り組んできました。 Giving Robots a Handの概要。出典: https://arxiv.org/pdf/2307.05959.pdf それに対して、「Giving Robots a Hand」は、確固たるルートを取ります。各画像の一貫した部分をマスキングし、人間の手やロボットのエンドエフェクターを効果的に隠すことです。このシンプルな方法は、緻密なドメイン適応技術の必要性を回避し、ロボットが直接人間のビデオから操作ポリシーを学ぶことを可能にします。その結果、人間からロボットへの画像変換に伴う顕著な視覚的な不整合から生じる問題を解決します。 提案された手法は、さまざまなタスクを実行するためにロボットを訓練することができます。出典: https://giving-robots-a-hand.github.io/ 「Giving Robots a…

「歴史的なアルゴリズムが最短経路問題の突破口を開くのに役立つ」
コンピューティングからの主要なアルゴリズムを再考することで、チームは長年のコンピュータ科学の問題に隠された効率性を解き放ちました

あなたのGen AIプロジェクトで活用するための10のヒントとトリック
現在、実際に利用されている生成型AIアプリケーションはあまり多くはありませんここで言っているのは、それらがエンドユーザーによって展開され、活発に使用されていることを意味します(デモ、POC、および抽出型AIは含まれません)生成型AIは…
データサイエンスプロジェクトを効果的に構造化する方法
「以前は、顧客がさまざまな回帰および分類タスクに取り組むために、類似モデルや推薦システム、NLP問題、予測など様々なデータサイエンスプロジェクトに従事していました」

『Amazon SageMaker Clarifyを使用して、臨床設定で医療上の決定を説明する』
この投稿では、Amazon SageMaker Clarifyを使用して、臨床設定でモデルの説明可能性を向上させる方法を示します医療領域で使用される機械学習(ML)モデルの説明可能性は、採用を得るためにさまざまな観点から説明する必要がありますこれらの観点には、医学的、技術的、法的な観点、そして最も重要な観点である患者の観点が含まれます医療領域のテキストで開発されたモデルは統計的に正確になっていますが、個々の患者に最適なケアを提供するために、臨床医はこれらの予測に関連する弱点を倫理的に評価する必要があります臨床医が患者ごとに正しい選択をするためには、これらの予測の説明可能性が必要です
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.