Learn more about Search Results Pi - Page 13

- You may be interested
- 「戦略的データ分析(パート1)」
- アマゾンの研究者は、深層学習を活用して...
- 音楽作曲のための変分トランスフォーマー...
- ジュネーブ大学の研究者は、多剤耐性(MDR...
- 「科学者たちが他の種とコミュニケーショ...
- 既存のLLMプロジェクトをLangChainを使用...
- 「トップの音声からテキストへのAIツール...
- スタンフォード大学の研究者たちは、安定...
- 「データの視覚化を即座に改善する4つの簡...
- 「MITとハーバードの研究者が提案する(FAn...
- Sentence Transformersモデルのトレーニン...
- この人工知能による調査研究は、医療領域...
- ニューヨーク市の可視化
- 「自律AIエージェントを使用してタスクを...
- 次世代のコンピューティング:NVIDIAとAMD...

「AnthropicがClaude 2を発表:コーディングを革新する次世代AIチャットプログラム」
人工知能スタートアップのAnthropicは、テックジャイアントのGoogleによるバックアップを受けて、人気のあるチャットプログラムであるClaudeを大幅に進化させました。最新のアップグレードである「Claude 2」は、コンピュータのコーディングと算術能力を向上させる最新技術を取り入れています。このブレイクスルーは、Claudeの初期ローンチからわずか数か月後に行われたものであり、OpenAI、Microsoft、Inflection AIなどの業界のリーダー企業がAIの分野で優位を得るために競い合っている激しい競争を浮き彫りにしています。 また読む: ChatGPTのコードインタープリター: 全てを知る 生成AIによる生産性の加速 Anthropicの生成AIは、コードの読み書きのタスクを迅速に進めることを約束しています。この先進技術を活用することで、Claude 2はブログ記事の作成や既存テキストの分析を容易に行い、コンテンツの創造に革命をもたらします。Anthropicを競合他社と差別化する要素は、システムが一度に最大75,000語の処理を行う驚異的な能力であり、AIが長文のビジネスドキュメントに効率的に取り組むことができます。この非凡な能力により、ユーザーは前例のない生産性の向上を実現することができます。 また読む: Google DeepMindがChatGPTを超えるアルゴリズムの開発に取り組む 安全性と規制への対応 AIの規制に関する懸念の増大は、世界中で高まる監視の目を引きました。著作権侵害や誤情報の拡散などの問題が業界内で警戒されています。Anthropicはこれらの課題に対応し、最近のアップグレードでClaudeの安全性評価を大幅に向上させました。同社は誇りを持って報告していますが、Claude 2はこの分野でのパフォーマンスを2倍に向上させ、AIによるコンテンツに関連する潜在的なリスクに対する強化されたセーフガードを提供しています。 また読む: ChatGPTが自己規制のための法律を制定 GPT-4でベンチマークを設定するOpenAI 多くの企業がAIの急速な発展に追いつこうと努力している中、OpenAIは革新の最前線に位置を維持しています。OpenAIの最新モデルであるGPT-4は、「マルチモーダル」の機能を導入することにより、AIを新たな高みに押し上げます。Claudeとは異なり、GPT-4はテキストに対応するだけでなく、人間が提供した画像を解釈して応答することもできます。この画期的な成果により、GPT-4は厳格なマルチステートバー試験で驚異的な75.7%のスコアを獲得し、米国の弁護士の資格を評価するために使用されるテストで高い評価を受けました。さらに、Claude 2はGPT-4よりも優れたコーディングスキルを持っています。 また読む: OpenAIがGPT-4へのアクセスを提供 Claude 2:…

「Raspberry Pi上でのYOLO物体検出」
この記事の最初の部分では、人気のある物体検出ライブラリであるYOLO (You Only Look Once)の レトロ バージョンをテストしましたOpenCVだけを使用してディープラーニングモデルを実行する可能性がありますが、…

🤗 APIのお客様のためにTransformerの推論を100倍高速化する方法
🤗 トランスフォーマーは、データサイエンティストが世界中で利用するデフォルトのライブラリとなり、最新のNLPモデルを探索し、新しいNLP機能を構築するためのものです。5,000以上の事前学習済みモデルとファインチューニングモデルが250以上の言語で提供されており、どのフレームワークを使用していても簡単にアクセスできる、豊富なプレイグラウンドです。 🤗 トランスフォーマーでモデルを試すことは簡単ですが、これらの大規模なモデルをパフォーマンス最大化で本番環境に展開し、使用状況にスケーリングするアーキテクチャで管理することは、どの機械学習エンジニアにとっても困難なエンジニアリングの課題です。 この100倍のパフォーマンス向上と組み込みのスケーラビリティのために、私たちのホストされたアクセラレーテッドインフェランスAPIのサブスクライバーは、その上にNLP機能を構築することを選択しました。パフォーマンスを最後の10倍向上させるためには、最適化はモデルに特化し、ターゲットのハードウェアに特化して低レベルで行う必要があります。 この記事では、お客様のために計算リソースを最大限に活用するための私たちのアプローチの一部を共有します。🍋 最初の10倍のスピードアップへの取り組み 最初の最適化のステップは最もアクセスしやすく、ターゲットのハードウェアに依存しないHugging Faceライブラリが提供する最適な技術の組み合わせを使用することです。 Hugging Faceモデルパイプラインに組み込まれた最も効率的な方法を使用して、各フォワードパス中の計算量を減らします。これらの方法はモデルのアーキテクチャとターゲットのタスクに固有であり、例えばGPTアーキテクチャのテキスト生成タスクでは、各パスの最後のトークンの新しいアテンションに焦点を当てることでアテンション行列の次元削減を行います。 トークン化は推論中の効率性においてボトルネックとなることが多いです。私たちは🤗 Tokenizersライブラリから最も効率的な方法を使用し、モデルのトークナイザーのRust実装とスマートキャッシングを組み合わせて、全体のレイテンシーを10倍高速化します。 Hugging Faceライブラリの最新機能を活用することで、特定のモデル/ハードウェアのデフォルト展開に比べて確実な10倍のスピードアップを実現します。TransformersとTokenizersの新リリースは通常毎月提供されるため、APIのお客様は常に新しい最適化の機会に合わせる必要はありません。彼らのモデルは単により高速に実行され続けます。 コンパイルFTW: 難しい10倍のスピードアップ ここからが本当に難しくなります。最高のパフォーマンスを得るためには、モデルを変更し、推論の特定のハードウェアをターゲットにしてコンパイルする必要があります。ハードウェアの選択そのものは、モデル(メモリサイズ)と需要プロファイル(リクエストのバッチ処理)に依存します。同じモデルから予測を提供する場合でも、一部のAPIのお客様はアクセラレートされたCPU推論から、他のお客様はアクセラレートされたGPU推論から、それぞれ異なる最適化技術とライブラリを適用することでより大きな恩恵を受けることがあります。 計算プラットフォームがユースケースに選択されたら、作業に取り掛かることができます。ここでは、静的グラフで適用できるいくつかのCPU固有のテクニックを示します: グラフの最適化(未使用のフローの削除) レイヤーのフュージョン(特定のCPU命令との組み合わせ) 演算の量子化 オープンソースライブラリ(例: 🤗…

実践におけるFew-shot学習:GPT-Neoと🤗高速推論API
多くの機械学習のアプリケーションでは、利用可能なラベル付きデータの量が高性能なモデルの作成の障害となります。NLPの最新の発展では、大きな言語モデルで推論時にわずかな例を提供することで、この制限を克服することができることが示されています。これはFew-Shot Learningとして知られる技術です。このブログ投稿では、Few-Shot Learningとは何かを説明し、GPT-Neoという大きな言語モデルと🤗 Accelerated Inference APIを使用して独自の予測を生成する方法を探ります。 Few-Shot Learningとは何ですか? Few-Shot Learningは、機械学習モデルに非常に少量の訓練データを与えて予測を行うことを指します。つまり、推論時にいくつかの例を与えるということです。これは、標準的なファインチューニング技術とは異なり、事前に訓練されたモデルが所望のタスクに適応するために比較的大量の訓練データが必要とされるものです。 この技術は主にコンピュータビジョンで使用されてきましたが、EleutherAI GPT-NeoやOpenAI GPT-3などの最新の言語モデルを使用することで、自然言語処理(NLP)でも使用することができるようになりました。 NLPでは、Few-Shot Learningは大規模な言語モデルと組み合わせて使用することができます。これらのモデルは、大規模なテキストデータセットでの事前トレーニング中に暗黙的に多くのタスクを実行することを学習しています。これにより、モデルはわずかな例だけで関連するが以前に見たことのないタスクを理解することができます。 Few-Shot NLPの例は主に以下の3つの主要な要素から構成されます: タスクの説明:モデルが行うべきタスクの短い説明、例えば「英語からフランス語への翻訳」 例:モデルに予測してほしいことを示すいくつかの例、例えば「sea otter => loutre de mer」…

Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
最近の投稿では、第4世代のIntel Xeon CPU(コードネーム:Sapphire Rapids)とその新しいAdvanced Matrix Extensions(AMX)命令セットについて紹介しました。Amazon EC2上で動作するSapphire Rapidsサーバーのクラスタと、Intel Extension for PyTorchなどのIntelライブラリを組み合わせることで、スケールでの効率的な分散トレーニングを実現し、前世代のXeon(Ice Lake)に比べて8倍の高速化とほぼ線形スケーリングを達成する方法を紹介しました。 この投稿では、推論に焦点を当てます。PyTorchで実装された人気のあるHuggingFaceトランスフォーマーと共に、Ice Lakeサーバーでの短いおよび長いNLPトークンシーケンスのパフォーマンスを測定します。そして、Sapphire RapidsサーバーとHugging Face Optimum Intelの最新バージョンを使用して同じことを行います。Hugging Face Optimum Intelは、Intelプラットフォームのハードウェアアクセラレーションに特化したオープンソースのライブラリです。 さあ、始めましょう! CPUベースの推論を検討すべき理由 CPUまたはGPUで深層学習の推論を実行するかどうかを決定する際には、いくつかの要素を考慮する必要があります。最も重要な要素は、モデルのサイズです。一般に、より大きなモデルはGPUによって提供される追加の計算能力からより多くの利益を得ることができますが、より小さいモデルはCPU上で効率的に実行することができます。…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…
Hugging Face Unity APIのインストールと使用方法
Hugging Face Unity APIは、Hugging Face Inference APIの簡単に使用できる統合です。これにより、開発者はUnityプロジェクトでHugging Face AIモデルにアクセスして使用することができます。このブログ投稿では、Hugging Face Unity APIのインストールと使用方法について説明します。 インストール Unityプロジェクトを開きます Window -> Package Managerに移動します +をクリックし、Add Package from git URLを選択します https://github.com/huggingface/unity-api.gitを入力します…

Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
この投稿では、安定拡散を教えるための指示調整について説明します。この方法では、入力画像と「指示」(例:自然画像に漫画フィルタを適用する)を使用して、安定拡散を促すことができます。 ユーザーの指示に従って安定拡散に画像編集を実行させるアイデアは、「InstructPix2Pix: Learning to Follow Image Editing Instructions」で紹介されました。InstructPix2Pixのトレーニング戦略を拡張して、画像変換(漫画化など)や低レベルな画像処理(画像の雨除去など)に関連するより具体的な指示に従う方法について説明します。以下をカバーします: 指示調整の紹介 この研究の動機 データセットの準備 トレーニング実験と結果 潜在的な応用と制約 オープンな問い コード、事前学習済みモデル、データセットはこちらで見つけることができます。 導入と動機 指示調整は、タスクを解決するために言語モデルに指示を従わせる教師ありの方法です。Googleの「Fine-tuned Language Models Are Zero-Shot Learners (FLAN)」で紹介されました。最近では、AlpacaやFLAN V2などの作品が良い例であり、指示調整がさまざまなタスクにどれだけ有益であるかを示しています。…
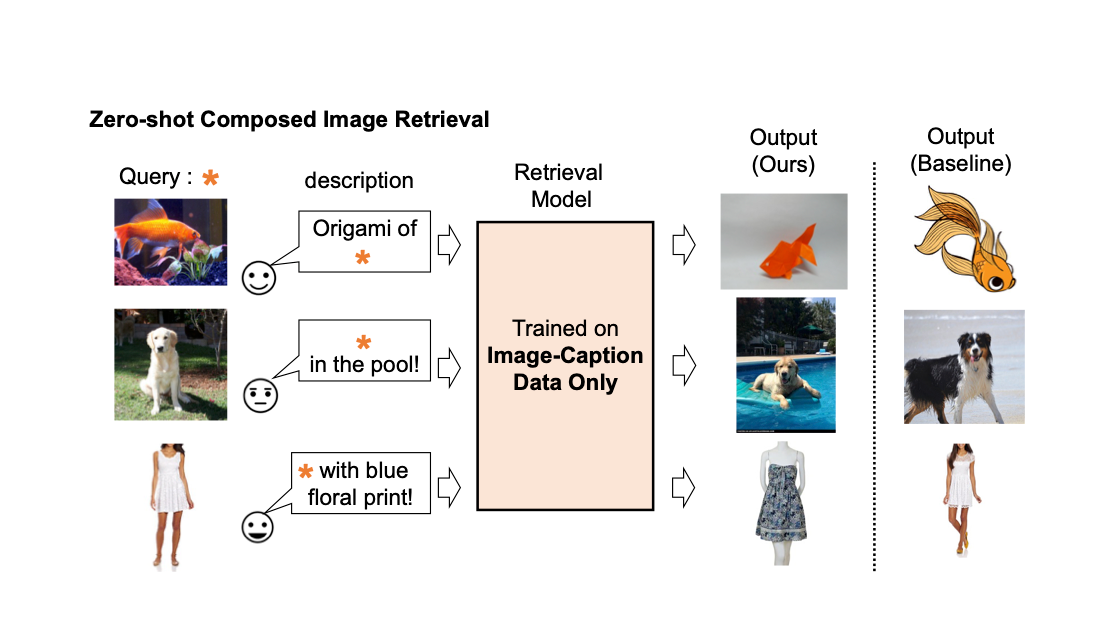
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

Pixis AIとは、コードを書かずにAIソリューションを提供する新興のスタートアップです
AIモデルのトレーニングには膨大な情報が必要です。しかし、すべての情報が同じではありません。モデルをトレーニングするためのデータは、エラーがなく、適切にフォーマットされ、ラベルが付けられ、問題を反映している必要があります。これは難しく、時間のかかるプロセスです。計画どおりに機能しない場合、AIモデルのデバッグが困難になることもあります。これは、モデルが通常複雑であり、さまざまな要因が故障の原因となる可能性があるためです。また、モデルの作成に使用されるトレーニングデータも、ミスの原因となる可能性があります。人工知能の領域では常に新しい進歩があります。そのため、新しい動向についていくことは困難です。さらに、AIシステムのハードウェア要件は常に増え続けており、古いまたは性能の低いマシンでAIモデルを実行することは困難です。AIコンポーネントを使用してプログラムを作成する際には、さまざまな困難が生じる場合があります。 現在、AI構造のコーディングに関連する困難を解消するためのさまざまなソリューション/製品が市場に存在しています。たとえば: ノーコードまたは低コード環境。これらのシステムのユーザーは、コードを一切触れずにAIモデルを構築することができます。一般的に、モデル作成やトレーニングプロセスを簡略化するためのグラフィカルユーザーインターフェースが付属しています。 機械学習およびAIホスティングサービス。これらのプラットフォームを通じてクラウドベースのAIモデルやサービスが提供されます。人員や資金がない企業は、自社のAIモデルを作成および維持するためにこれらを活用することができます。 人工知能の専門家。多くのAI専門家がAIに関連する問題に対処するために企業を支援しています。基礎を学ぶことから実践に移すことまで、AIのニーズに応じてサポートできます。 PixisのAIソリューションは、クロスプラットフォームのパフォーマンスと成長マーケティングにAIを活用した意思決定を可能にします。顧客は、目標を満たし超えるために、目的に特化した自己進化型ニューラルネットワークを使用したコードレスのAIインフラストラクチャを活用しています。この若い企業は、堅牢なコードレスのAIインフラストラクチャを実現するために、2022年に1億ドルのシリーズCの資金調達を成功裏に終えました。これにより、ブランドはマーケティングのあらゆる側面の拡大および意思決定の効率的な補完を実現することを目指しています。最後の資金調達以来、Pixisはインフラストラクチャに約120以上の新しいAIモデルを導入し、200の独自のAIモデルのベンチマーク達成に一歩近づいています。これらのAIモデルは、マーケターに対してコードを1行も書かずに堅牢なプラグアンドプレイのAI製品を提供します。また、Pixisの300人以上の分散チームは、顧客のマーケティングおよび需要創出の取り組みを最大限に活用するための非常に変革的なAI製品の開発に注力しています。 100を超えるPixisのグローバル顧客がそのAIサービスを利用しています。Pixis AIインフラストラクチャのユーザーは、少なくとも300時間の手作業の月間節約と、少なくとも10-15%の顧客獲得コストの削減を報告しています。このブランドは、1行のコードを書く必要なしに即座にAIを活性化することを顧客に約束しています。 PixisのパフォーマンスマーケティングのためのコードレスAIインフラストラクチャ:概要 ターゲットAI PixisのターゲティングAIは、数十億のデータポイントでトレーニングされた最先端のニューラルネットワークを使用して、ブランドに最も関連性のあるコホートを提供し、時間の経過とともにさらに向上させます。 ブランドは、コンバージョンのトレンド、行動パターン、エンゲージメントレベル、およびその他のコンテキストの洞察に基づいて導き出されたユーザーペルソナを活用して、ターゲティングパラメータと技法を微調整することができます。インフラストラクチャは、顧客関係管理(CRM)プラットフォーム、アトリビューションプラットフォーム、デザインツール、およびウェブ分析を簡単にサポートします。 ターゲティングAIは、ユニークなクラスタリングアルゴリズムを使用して、非常に関連性の高いクロスプラットフォームのオーディエンスコホートを構築し、ターゲットオーディエンスの知識を活用して、マーケティング活動を創造性と最適化の両面で導きます。 クリエイティブAI PixisのクリエイティブAIは、特許取得済みの生成AIモデルを使用して、関連性の高い視覚的および静的なアセットを作成することで、プラットフォーム全体でのエンゲージメントとコンバージョン率を向上させます。 クリエイティブ努力の効果をフィードバックしやすくすることで、将来のキャンペーンの改善に向けて微調整することが容易になります。すべてのチャネルでのペルソナベースのクリエイティブアドバイスにより、エンゲージメントと売上を増加させます。フィードバックに基づいたクリエイティブの最適化を通じて、クリエイティブAIはコミュニケーションのコンテキストを常に向上させます。 パフォーマンスAI 過去のキャンペーンデータ、季節パターン、アトリビューション、分析、およびリアルタイムのパフォーマンスデータからのコンテキスト学習を統合し、すべてのチャネルにわたるスマートな意思決定を実現するAIパワードマーケティングインフラストラクチャを構築します。 ブランドは、入札とリソースを自動的に割り当てなおすことができ、また、すべてのチャネルでのマイクロトレンドを検出する多目的収束型AIモデルも含まれているインフラストラクチャを使用して、広告支出のリターンを最大化することを目指しています。 ピーク時のトラフィックでAIトラックを実行し、広告費の支出と収益(ROAS)を分析し、将来のキャンペーンに最適な予算配分技術を予測します。予算編成と主要パフォーマンス指標の最適化の間のベストなバランスを見つけるために、ハイパーコンテクストUAL AIモデルを使用します。 Pixis AIの特長機能 ●…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.