Learn more about Search Results ImageNet - Page 13

- You may be interested
- 「仕事の未来:スキルアップしないと取り...
- 「非常にシンプルな数学が大規模言語モデ...
- 「LLM(法務修士)のプロンプトアーキテク...
- 合成データとは何ですか?
- 「人類はAIの日食の瀬戸際にあるのか?」
- いつでもどんな人にでもメッセージを明確...
- Google AIは、LLMsへの負担を軽減する新し...
- TF Servingを使用してHugging FaceでTenso...
- 「Meetupsからメンタリングまで データサ...
- 量子AI:量子コンピューティングの潜在能...
- 我々はまもなく独自のパーソナルAIムービ...
- ニューヨークは、チップの研究を拡大する...
- このAIニュースレターは、あなたが必要と...
- 「きらめく」星の音はどのようなものですか?
- 最高のAIジョブコース(2023年)
.png)
AIモデルの知覚を測定する
知覚は、感覚を通じて世界を経験するプロセスであり、知能の重要な部分ですそして、人間レベルの知覚的な世界理解能力を持つエージェントを構築することは、ロボット工学、自動運転車、パーソナルアシスタント、医療画像など、ますます重要な課題ですが、それは困難な課題でもありますそこで、本日は、モデルの知覚能力を評価するための、実世界のビデオを使用したマルチモーダルベンチマークである「知覚テスト」を紹介いたします
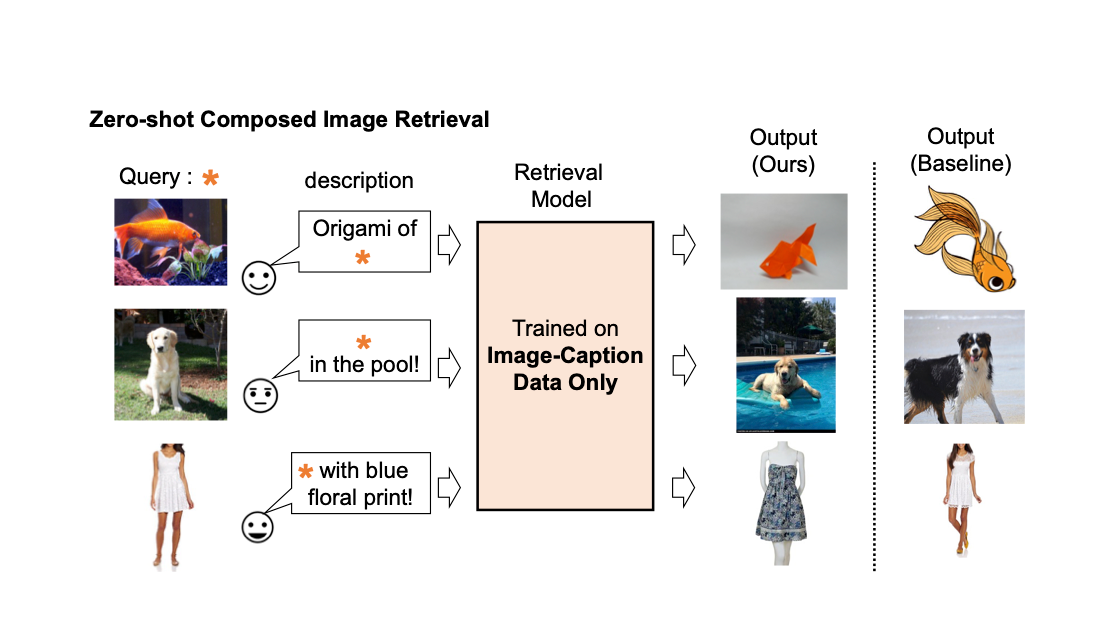
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

なぜディープラーニングは常に配列データ上で行われるのか?新しいAI研究は、データからファンクタまでを一つとして扱う「スペースファンクタ」を紹介しています
暗黙のニューラル表現(INR)またはニューラルフィールドは、3D座標を3D空間の色と密度の値にマッピングすることによって、3Dシーンなどのフィールドを表現する座標ベースのニューラルネットワークです。最近、ニューラルフィールドは、写真、3D形状/シーン、映画、音楽、医療画像、気象データなどの信号を表現する手段としてコンピュータビジョンで注目されています。 従来のピクセルなどの配列表現を処理する従来のアプローチではなく、最近の研究では、これらのフィールド表現に直接深層学習を行うためのfunctaというフレームワークが提案されています。このフレームワークは、生成、推論、分類など、多くの研究領域で良好なパフォーマンスを発揮します。これらの領域には、画像、ボクセル、気候データ、3Dシーンなどが含まれますが、通常はCelebA-HQ 64 64やShapeNetなどの小さなまたは単純なデータセットでのみ動作します。 以前のfunctaの研究では、比較的小さなデータセットでも多くの異なるモダリティに対してニューラルフィールド上での深層学習が可能であることが示されました。しかし、CIFAR-10の分類および生成タスクでは、この方法はパフォーマンスが低かったです。これは、CIFAR-10のニューラルフィールド表現が非常に正確であり、ダウンストリームのタスクを完了するために必要なすべてのデータを含んでいるはずなので、研究者たちにとって驚きでした。 DeepMindとハイファ大学による新しい研究では、functaの適用範囲をより広範かつ複雑なデータセットに拡張するための戦略を提案しています。まず、彼らは自身の方法を使用して、CelebA-HQ上で報告されたfunctaの結果を再現できることを示しています。次に、それをCIFAR-10のダウンストリームタスクに適用し、分類および生成の結果が驚くほど低いことを報告しています。 空間functaは、functaの拡張として、フラットな潜在ベクトルを空間的に順序付けられた潜在変数の表現で置き換えます。その結果、各空間インデックスの特徴は、すべての可能な場所からデータを収集するのではなく、その場所に固有の情報を収集することができます。この小さな調整により、位置エンコーディングを持つトランスフォーマーやUNetなどのより洗練されたアーキテクチャを使用して、生成、分類などのダウンストリームタスクを解決することができます。これらのアーキテクチャは、空間的に整理されたデータに適した帰納的なバイアスを持っています。 これにより、functaフレームワークは、256×256解像度のImageNet-1kなどの複雑なデータセットに対応できるようになります。調査結果はまた、CIFAR-10の分類および生成における制約が空間functaによって解決されることを示しています。ViTsと同等の分類結果とLatent Diffusionと同等の画像生成結果が得られます。 チームは、ニューラルフィールドがこれらの高次元のモダリティにおいて、配列表現の冗長な情報をより効率的な方法で捉えているため、functaフレームワークが大規模なスケールで輝くと考えています。
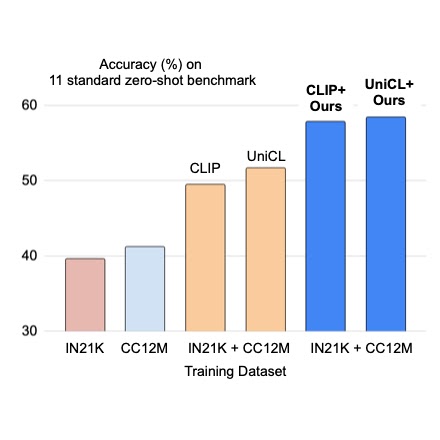
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。 CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。 高レベルのアイデア 分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。 それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 プレフィックス条件付け プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。 トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。 CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。 接頭辞条件付けのイラスト。 実験結果…

MITの研究者が、生成プロセスの改善のために「リスタートサンプリング」を導入
微分方程式ベースの深層生成モデルは、最近、画像合成から生物学までのさまざまな分野で、高次元データのモデリングにおいて有力なツールとして登場しています。これらのモデルは、逆に微分方程式を反復的に解いて、基本的な分布(拡散モデルの場合はガウス分布など)を複雑なデータ分布に変換します。 これらの可逆プロセスをモデリングできる事前サンプラーは、次の2つのタイプに分類されています: 初期のランダム化後は決定論的に進化するODEサンプラー 生成トラジェクトリが確率的であるSDEサンプラー いくつかの研究によると、これらのサンプラーはさまざまな設定で利点を示しています。ODEソルバーによって生成されるより小さい離散化エラーにより、より大きなステップサイズでも使用可能なサンプル品質が得られます。ただし、その子孫の品質はすぐに飽和します。一方、SDEは大きなNFE領域で品質を向上させますが、サンプリングに費やす時間が増えます。 このことに触発されて、MITの研究者は、ODEとSDEの利点を組み合わせた新しいサンプリング手法であるRestartを開発しました。Restartサンプリングアルゴリズムは、固定時間内での2つのサブルーチンのK回の反復から構成されています:大量のノイズを導入するRestartフォワードプロセス(元の逆プロセスを「再開」)と、逆ODEを実行するRestartバックワードプロセス。 Restartアルゴリズムは、ランダム性とドリフトを分離し、Restartのフォワードプロセスで追加されるノイズの量は、以前のSDEのドリフトと交錯する小さな単一ステップのノイズよりもはるかに大きくなっており、蓄積されたエラーに対する収縮効果が増大します。各Restart反復で導入される収縮効果は、K回のフォワードとバックワードのサイクルによって強化されます。Restartは、決定論的な逆プロセスにより、離散化のミスを減らし、ODEのようなステップサイズを実現することができます。実際には、Restart間隔は、蓄積されたエラーが大きいシミュレーションの最後に配置されることが多く、収縮効果を最大限に活用するために使用されます。さらに、より困難な活動では、早期のミスを減らすために複数のRestart期間が使用されます。 実験結果は、さまざまなNFE、データセット、事前トレーニング済みモデルにおいて、Restartが品質と速度において最先端のODEおよびSDEソルバーを上回ることを示しています。特に、VPを使用したCIFAR-10では、Restartは以前の最良のSDEに比べて10倍のスピードアップを実現し、EDMを使用したImageNet 64×64では、ODEソルバーを上回る小さなNFE領域でも2倍のスピードアップを実現しています。 研究者はまた、RestartをLAION 512 x 512画像で事前トレーニングされたStable Diffusionモデルに適用して、テキストから画像への変換を行っています。Restartは、CLIP/Aestheticスコアによるテキスト-画像の整合性/視覚品質と、FIDスコアによる多様性の間で、変動する分類器なしのガイダンス強度を用いて、以前のサンプラーに比べてより良いバランスを実現しています。 Restartフレームワークの潜在的な可能性を十分に活用するために、チームは将来的にはモデルのエラー分析に基づいてRestartの適切なハイパーパラメータを自動的に選択するためのより道徳的な手法を構築する予定です。

T5:テキスト対テキスト変換器(パート1)
転移学習のパラダイムは、2つの主要なステージで構成されていますまず、大量のデータに対してディープニューラルネットワークを事前学習します次に、このモデルを微調整し(つまり、さらにトレーニングを行う)、より...

なぜ無料のランチがあるのか
機械学習の領域における「無料の昼食はない」定理は、数学の世界におけるゲーデルの不完全性定理を思い起こさせますこれらの定理はよく引用されますが、めったに...

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...

AIの汎化ギャップに対処:ロンドン大学の研究者たちは、Spawriousという画像分類ベンチマークスイートを提案しましたこのスイートには、クラスと背景の間に偽の相関が含まれます
人工知能の人気が高まるにつれ、新しいモデルがほぼ毎日リリースされています。これらのモデルには新しい機能や問題解決能力があります。近年、研究者たちは、AIモデルの抵抗力を強化し、スパリアスフィーチャーへの依存度を減らすアプローチを考えることに重点を置いています。自動運転車や自律型キッチンロボットの例を考えると、彼らは彼らが訓練データから学習したものと大きく異なるシナリオで動作する際に生じる課題のためにまだ広く展開されていません。 多くの研究がスパリアス相関の問題を調査し、モデルのパフォーマンスに対するその負の影響を軽減する方法を提案しています。ImageNetなどのよく知られたデータセットで訓練された分類器は、クラスラベルと相関があるが、それらを予測するわけではない背景データに依存していることが示されています。SCの問題に対処する方法の開発に進展はあったものの、既存のベンチマークの制限に対処する必要があります。現在のWaterbirdsやCelebA hair color benchmarksなどのベンチマークには制限があり、そのうちの1つは、現実では多対多(M2M)のスパリアス相関がより一般的であり、クラスと背景のグループを含む単純な1対1(O2O)スパリアス相関に焦点を当てていることです。 最近、ロンドン大学カレッジの研究チームが、クラスと背景の間にスパリアス相関が含まれる画像分類ベンチマークスイートであるSpawriousデータセットを導入しました。それは1対1(O2O)および多対多(M2M)のスパリアス相関の両方を含み、3つの難易度レベル(Easy、VoAGI、Hard)に分類されています。データセットは、テキストから画像を生成するモデルを使用して生成された約152,000の高品質の写真リアルな画像で構成されており、画像キャプションモデルを使用して不適切な画像をフィルタリングし、データセットの品質と関連性を確保しています。 Spawriousデータセットの評価により、現在の最先端のグループ頑健性アプローチに対してHard-splitsなどの課題が課せられ、ImageNetで事前学習されたResNet50モデルを使用してもテストされた方法のいずれも70%以上の正確性を達成できなかったことが示されました。チームは、分類器が間違った分類を行った際に背景に依存していることを見て、モデルのパフォーマンスの短所が引き起こされたと説明しています。これは、スパリアスデータの弱点を成功裏にテストし、分類器の弱点を明らかにすることができたことを示しています。 O2OとM2Mベンチマークの違いを説明するために、チームは、夏に訓練データを収集する例を使用しました。それは、2つの異なる場所から2つの動物種のグループで構成され、各動物グループが特定の背景グループに関連付けられているものです。しかし、季節が変わり、動物が移動すると、グループは場所を交換し、動物グループと背景の間のスパリアス相関が1対1で一致することはできなくなります。これは、M2Mスパリアス相関の複雑な関係と相互依存関係を捉える必要性を強調しています。 Spawriousは、OOD、ドメイン汎化アルゴリズムにおける有望なベンチマークスイートであり、スパリアスフィーチャーの存在下でモデルの評価と改善を行うためにも使用できます。
METAのHiera:複雑さを減らして精度を高める
畳み込みニューラルネットワークは、20年以上にわたってコンピュータビジョンの分野を支配してきましたトランスフォーマーの登場により、それらは放棄されると考えられていましたしかし、多くの実践者は…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.