Learn more about Search Results Claude - Page 13

- You may be interested
- 研究者たちは、新しい量子光源を開発しました
- ロボットスキル合成のための言語から報酬...
- 連邦政府、自動車メーカーに対し、マサチ...
- ELT vs ETL 違いと類似点の明らかに
- 人工蜂コロニー-PSOとの違い
- コーネル大学の人工知能(AI)研究者たち...
- 遺伝的アルゴリズム:エンゲージメントを...
- 世界に向けて:非営利団体がGPUパワードの...
- AutoTrainによる画像分類
- 気候変動との戦いをリードする6人の女性
- 「GoogleのAI Red Team:AIを安全にするた...
- 工学部は、Songyee Yoon博士(PhD ’...
- メタがコードラマをリリース:コーディン...
- お客様との関係を革新する:チャットとRea...
- 「あなたのMLアプリケーションを際立たせ...
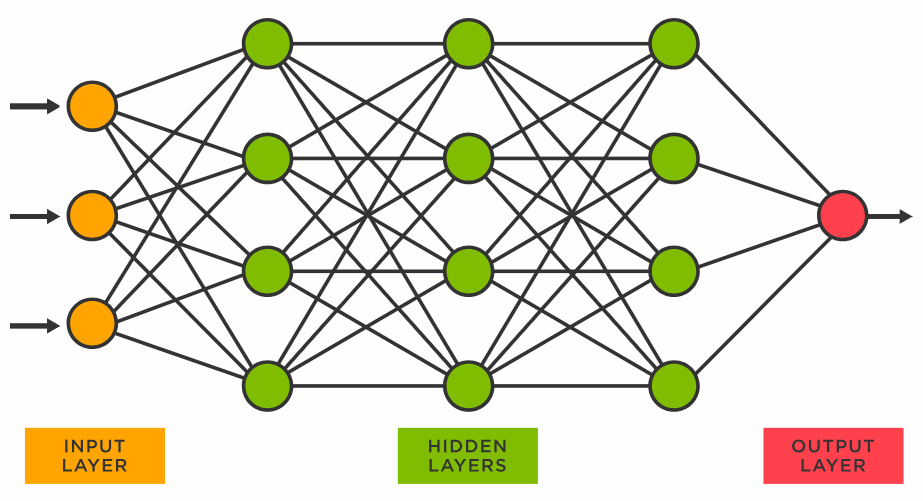
「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
「たぶん私だけじゃないと思いますが、1月のツイートで明らかになっていなかったとしても、私は最初にChatGPTに出会ったときに完全に驚きましたその体験は他のどんなものとも違いました…」

メタがコードラマをリリース:コーディングのための最新のAIツール
メタ社は、驚異的な技術的飛躍を遂げ、最新の作品であるCode Llamaをリリースしました。Code Llamaは、Llama 2言語モデルをベースにしたAIパワードツールです。この革新的なツールは、開発者にとってスーパーヒーローのような存在であり、コーディングをスムーズで高速、かつより利用しやすくしてくれます。経験豊富なプログラマであっても、コーディングの旅を始めたばかりでも、Code Llamaがあなたをサポートします。以下に、Metaの最新AIコード生成ツールについて知っておくべきことをまとめました。 また読む: Anthropicがコーディングを革新する次世代AIチャットプログラムClaude 2を発表 Code Llamaでコードを解読する MetaのCode Llamaは、普通のAIではありません。これは大規模な言語モデル(LLM)であり、テキストのプロンプトを読み取り、コードの解決策を作成することができます。自分専用のコーディングの魔人をイメージしてください-望むものを入力すると、ぱっと出てきます!Code Llamaは、プロジェクトを輝かせることができる超効率的でエキスパートレベルのコードです。 また読む: プログラマを助けるコードを生成する10のAIツール ギャップを埋める: 初心者から忍者へ コーディングを学ぶことは、異星語を解読するようなものかもしれません。しかし、Code Llamaがあなたのそばにいると、賢明なメンターがあなたの言葉とコードの言葉を話すようなものです。AIコード生成ツールは、あなたの説明に基づいてコードの行を作成し、複雑なアイデアを現実に変えることができます。Python、C ++、Java、または他の主要なプログラミング言語であっても、このAIは対応しています! コード生成ツール以上のもの Code Llamaは、コード生成ツールにとどまらず、コーディングのあらゆる段階で役立つ多目的なツールです。デバッグやコードの完成において、あなたの仮想のパートナーとなります。コードを書いていて行き詰まった場合、AIが提案してプロセスを案内し、行き詰まらないようにサポートしてくれます。 また読む:…
「Maxflow Mincut定理の発見:包括的かつ形式的なアプローチ」
ネットワークフロー最適化の領域では、最大流最小カット定理が顕著な数学的なマイルストーンとして際立っていますその優雅さが複雑な最適化問題の解決の鍵を握っています...

バイオメディカルインサイトのための生成AI
OpenBIOMLとBIO GPTを利用したGenerative AIを探求し、Large Language Models (LLMs)を使用して疾患の理解と治療に新たなアプローチを取ることを目指しています

マイクロソフトと香港浸会大学の研究者が、WizardCoder A Code Evol-Instruct Fine-Tuned Code LLMを紹介しました
大規模言語モデル(LLM)は最近注目を集め、驚異的な成功を収めています。特にOpenAIのChatGPTは注目すべき例です。これらのモデルは、インターネットの大量のデータでの重要な事前学習と、精密な指示データでのさらなる微調整を利用することで、様々なタスクにおいて最先端のゼロショットパフォーマンスを達成しています。このパターンはコードの理解と生成でも見られます。コードを使用する活動に固有の難しさに対処するために、多くのコードLLMが提案されています。これらのコードLLMは大量のコードデータを利用して事前学習を行い、コードに関連する様々な活動で優れたパフォーマンスを発揮することができます。 しかし、事前学習フェーズに主眼を置いた従来のコードLLMとは異なり、コード領域における細かい指示の調整についてさらなる研究が必要です。様々な活動におけるLMの汎化能力を向上させるために、指示の微調整が最初に使用されました。例えば、OpenAIのInstructGPTは、人間の注釈者に具体的な指示を提供してユーザーの目標との一致を確認するよう求めました。最近の取り組みであるAlpacaは、自己指導アプローチを使用して指示データを生成するためにChatGPTを利用しました。Vicunaは、ユーザーがShareGPT.comに投稿したチャットを利用しました。WizardLMはEvol-Instructアプローチを確立し、現在の指示データを修正してより複雑で多様なデータセットを生成しました。 ただし、これらの技術は、一般的なドメインに主眼を置くことが多く、コードドメインを特に考慮して設計すべきであることに注意する必要があります。このプロジェクトのMicrosoftと香港浸会大学の研究者は、コード固有のEvol-Instructを使用して詳細なコード指示データを生成することで、オープンソースのCode LLMであるStarCoderの機能を向上させることを目指しています。これを実現するために、コーディングに関わる活動に特化したいくつかの方法で進化的なプロンプトプロセスを変更しました。進化的なプロンプトは簡素化され、進化的な指示が改善され、コードのデバッグや時間・空間の制約が含まれるようになりました。彼らのアプローチは最初に基本的なCode Alpacaの指示データを開発するために使用されます。 次に、新たに開発されたコード指示に従うトレーニングセットを使用してStarCoderを微調整し、WizardCoderを得ます。彼らのWizardCoderは、HumanEval、HumanEval+、MBPP、およびDS-100の4つのコード生成ベンチマークの実験結果によると、他のすべてのオープンソースのCode LLMを凌駕し、最先端のパフォーマンスを達成します。HumanEvalでは、pass@1スコアが著しく向上し、HumanEvalで+22.3(57.3 vs 35.0)の増加、MBPPで+8.2(51.8 vs 43.6)の増加が見られます。驚くべきことに、WizardCoderは、AnthropicのClaudeやGoogleのBardよりも、HumanEvalとHumanEval+における合格率において優れた結果を示しています。それにもかかわらず、WizardCoderはかなり小さいにも関わらず、主要なクローズドソースのLLMであるClaude、Bard、PaLM、PaLM-2、およびLaMDAを超えてコード生成の面で優れています。 以下は、この研究の貢献の要約です: • コードのEvol-Instructを適用したWizardCoderは、オープンソースのCode LLMであるStarCoderの機能を向上させます。 • WizardCoderは、コード生成の面でStarCoder、CodeGen、CodeGee、CodeT5+、InstructCodeT5+、StarCoder-GPTeacher、Instruct-Codegen-16Bを含む他のすべてのオープンソースのCode LLMを大きく凌駕しています。 • サイズがかなり小さいにもかかわらず、WizardCoderはClaude、Bard、PaLM、PaLM-2、およびLaMDAを含む主要なクローズドソースのLLMを超えてコード生成の面で優れています。

「クロード2 AIチャットボットの使い方 – 新しいChatGPTの競合者」
イントロダクション 複数のAIチャットボットの中でも新たな競争相手、Claude 2に会いましょう。Anthropicによって開発されたChatGPTの新しい競合製品で、まだオープンベータ版ですが、非常にインタラクティブです。メールアドレスを通じた簡単なアクセスを通じて、異なる使いやすいユーザーインターフェースを提供します。この記事では、Anthropicの新しいClaude 2 AIチャットボットに詳しく触れ、異なるトピックでの対話能力と視点を明らかにします。AIを判断し、自分自身の内省を始めることも自由です。 Claude 2 AIチャットボットとは? Claude 2 AIチャットボットは、米国のAIスタートアップAnthropicによって開発されたAIのデビュー作品です。OpenAIの優れたエキスパートたちが設計した、自然言語処理を通じて人間と対話することができるLarge Language Model(LLM)を搭載した生成型AIチャットボットです。このAIは、ChatGPTやBardなどの他の一般公開されているチャットボットと同様に効率的な機能を発揮することができます。AIの安全性とセキュリティは、人権の普遍的宣言に基づいています。 Claude 1はビジネス専用でしたが、Claude 2は一般の利用に向けて使用されています。Claude 2は、バーエグザムの多肢選択問題で76.5%、GREの読解・文章作成の部分で90パーセンタイルのスコアを獲得しました。また、以前のバージョンと比べてより優れたコーディングを誇り、Pythonのコーディングテストで71.2%のスコアを獲得しました。このAIチャットボットは現在オープンベータ版であり、無償ユーザー向けの利用は制限されています。 Claude 2 vs. ChatGPT Claude 2の使い方 Claude…

「機械に学習させ、そして彼らが私たちに再学習をさせる:AIの構築の再帰的性質」
「建築デザインの選択が集団の規範にどのように影響を与えるかを探索し、トレーニング技術がAIシステムを形作り、それが再帰的に人間の行動に影響を与える様子を見てください」

コンテンツクリエイター向けの20のクロードのプロンプト
「ここには、Claudeにコピー&ペーストできる20のプロンプトがありますこれを使用して、オーディエンスを10倍速く成長させて収益化することができます」

メタAIのハンプバック!LLMの自己整列と指示逆翻訳による大きな波を起こしています
大規模言語モデル(LLM)は、コンテキスト学習や思考の連鎖など、優れた一般化能力を示しています。LLMが自然言語の指示に従い、現実世界のタスクを完了するために、研究者はLLMの指示調整方法を探求しています。これは、人間の注釈付きプロンプトやフィードバック、または公開ベンチマークとデータセットを使用した監督微調整など、さまざまな関数でモデルを微調整することで実現されます。最近の研究では、人間の注釈データの品質の重要性が強調されています。しかし、そのような品質のデータセットに従って指示を注釈付けすることは、スケールするのが難しいことがわかっています。 この解決策は、LLMとの自己整列を扱います。つまり、モデルを利用して自身を改善し、モデルが書かれたフィードバック、批判、説明などの望ましい振る舞いに応じて応答を整列させることです。Meta AIの研究者は、自己整列による指示付きバックトランスレーションを紹介しました。基本的なアイデアは、大規模言語モデルを使用してWebテキストに対応する指示を自動的にラベル付けすることです。 セルフトレーニングのアプローチでは、ベースとなる言語モデル、ラベルのない例のコレクション(例えば、Webコーパス)、および少量のシードデータにアクセスできることが前提とされます。この方法の第一の前提は、この大量の人間によって書かれたテキストの一部は、いくつかのユーザー指示のための良い生成物として有用であるということです。第二の前提は、これらの応答に対して指示を予測できるということであり、これを使用して高品質の例のペアを使用して指示に従うモデルをトレーニングすることができます。 指示付きバックトランスレーション全体は、以下の手順に分割できます: セルフオーグメント:ラージ言語モデルMeta AI(LLaMA)を使用して、ラベルの付いていないデータ(Webコーパスなど)のための「良い指示」を生成し、指示の調整のためのトレーニングデータ(指示、出力のペア)を生成します。 セルフクリエイト:LLaMAを使用して生成されたデータを評価します。 そして、このデータを使用してLLaMAを微調整し、手順を繰り返して改良されたモデルを使用します。その結果、トレーニングされたLlamaベースの指示バックトランスレーションモデルは、「ハンプバック」と呼ばれました(クジラの大規模性にちなんでいます)。 「ハンプバック」は、アルパカリーダーボードのClaude、Guanaco、Falcon-Instruct、LIMAなどに関して、すべての既存の非蒸留モデルを上回りました。 現在の手順の欠点は、高度なデータがWebコーパスから派生しているため、微調整モデルはウェブデータのバイアスを強調する可能性があるということです。結論として、この方法はトレーニングデータがなくなることは絶対にありませんし、大規模言語モデルに指示に従うための堅牢なスケーラブルなアプローチを提供します。今後の課題は、より大きな未ラベルのコーパスを考慮することで、さらなる利益が得られる可能性があることです。

「大規模言語モデル(LLM)を実世界のビジネスアプリケーションに移す」
大規模な言語モデルはどこにでも存在します顧客との会話やVCの提案において、LLM技術の準備がどの程度進んでいるか、そして将来の応用にどのように貢献するかについての質問が含まれます私は以前の投稿でそれについていくつかのパターンを取り上げましたここでは、Persistent Systemsが製薬業界向けのアプリケーションについて実際のパターンについて話します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.