Learn more about Search Results 10 - Page 13

- You may be interested
- 『Auto-GPTのデコーディング』 自動生成...
- AI導入の迷宮を進む
- 「オープンソースLLMsの歴史:初期の日々...
- 「水中ロボットが深海採鉱のためのハイテ...
- マルチAIの協力により、大規模な言語モデ...
- 専門AIトレーニングの変革- LMFlowの紹介...
- メタAIは、CM3leonを紹介します:最先端の...
- 「Numexprの探索:Pandasの背後にある強力...
- Pythonアプリケーション | 速度と効率の向...
- 富士通とLinux Foundationは、富士通の自...
- 「ChatGPTを使用してAI幻覚を回避する方法」
- アプリケーションの近代化における生成AI...
- AIに関する最高のコースは、YouTubeのプレ...
- 画像埋め込みのためのトップ10の事前訓練...
- 「大規模言語モデルの品質をどのように向...

「2023年の写真とビデオのための10のAIディープフェイクジェネレーター」
AIのディープフェイク生成器や人工知能を使用したソフトウェアツールを使うと、言ったりしたこともしなかったこともない人々のビデオや音声の録音が作成できます。このために、ターゲットとなる個人の実在するメディアの大量のコレクションを使ってニューラルネットワークがトレーニングされます。ウェブは個人を認識し、その外見、話し方、行動を模倣するようにトレーニングされます。 AIのディープフェイク生成器には、さまざまな良い使い方と悪い使い方があります。コメディ動画や教材を作るために使用することもできます。以下は、写真やビデオのためのいくつかのAIのディープフェイク生成器です。 Zao 私たちのトップピックはZaoで、映画での顔の置き換えにおいて非常に優れた性能を発揮しています。このソフトウェアでは、コンピュータビジョンを使用してビデオから自動的に顔を抽出します。ユーザーはギャラリーやビデオフィードから顔を選び、Zaoを使用して簡単にセルフィービデオに組み込むことができます。Zaoは、洗練されたトラッキングとスムージングの技術によって可能になるリアルな顔の入れ替え能力で注目されています。このソフトウェアは、ユーザーが頭を動かしたり照明が変わったりしても信頼性があります。ユーザーは多くの有名人、架空のキャラクター、ミームテーマのクローンテンプレートにアクセスできます。Zaoは、特にモバイルデバイス上でのディープフェイク体験の専門的な使いやすさによって際立っています。 Reface 顔の交換や変形において、Refaceは最も優れたディープフェイクツールの一つとなっています。シンプルなデザインと高速なレンダリング時間が人気を集めています。Refaceは、ユーザーがターゲットとなる顔を選び、それをビデオにスムーズに挿入することを簡単にします。アラインメントが完璧でなくても、結果の品質は優れています。Refaceのユーザーは、様々な有名人の顔のテンプレート、GIF、バイラルなミームを選ぶことができます。自動的なスムージングにより、効果の変動が抑えられます。また、ユーザーはAIを利用してお気に入りの有名人の姿をセルフィーに重ねることで、風刺画を思わせるような結果を生み出すことができます。Refaceは、精密な手動コントロールが必要な特殊なアプリケーションには欠けているものの、驚くほどの速さとシンプルさにより、人気のある選択肢となっています。無料版には広告がありますが、基本的なディープフェイキングの機能を必要とする個人にはリーズナブルな価格で提供されています。 Deep Face Lab データサイエンティストのIPerovがキュレーションするDeep Face Labは、説得力のある顔の入れ替えを実現するために最新のアルゴリズムを使用しています。ユーザーは幅広い手動設定を提供され、ディープフェイクを細かく調整することができます。このツールは、GANのトレーニングに加えて、マルチターゲットフィルムの処理、カラーコレクション、スタビライゼーション、音声クローニングなどを扱う能力が特に印象的です。バッチ処理を可能にする自動化機能により、顔をシームレスに複数のフォルダやビデオコレクション全体に置き換えることができます。豊富なGitHubコミュニティは、DeepFaceLabサービスを改善するために新しいモデルやチュートリアルを絶えず追加しています。ただし、その複雑さやユーザーが追加のライブラリをダウンロードしたり設定を変更する必要があるため、DeepFaceLabは初心者には理想的ではありません。この複雑なプログラムをマスターするために時間と努力を惜しまないビデオ編集者は、説得力のあるディープフェイクを作成することができます。 Avatarify ZoomやSkype、Google Meetなどのサービスで使用するために、Avatarifyはリアルタイムのディープフェイクフェイシャルフィルターを提供します。このソフトウェアは、ブラウザでディープラーニングモデルを実行するための新しいWebGLの実装を使用しています。ユーザーが操作するための顔を選び、アプリにカメラへのアクセスを許可すると、Avatarifyはライブビデオフィード上にカスタマイズされた顔のアニメーションをシームレスに重ねることができます。この楽しいインタラクティブな機能により、ユーザーはライブ通話中にミームの顔や有名人のルックを作成することができます。ブラウザ互換性のおかげで、配布は簡単です。ただし、Avatarifyを使用するにはPythonとNode.jsが必要です。性能はパワフルでないシステムでは不安定になる可能性があります。現在でも、Avatarifyはオンラインビデオチャットや放送で使用するための最も広く利用可能なディープフェイクツールの一つです。これはコミュニティによるオープンソースの取り組みです。 Deep Nostalgia Deep Nostalgiaで使用される深層学習アルゴリズムにより、以前は静止画であった画像に表情の動きが生まれます。ユーザーからの顔の写真を受け取ると、Deep Nostalgiaは自動的にその人がまばたきをしたり笑ったり回ったりするGIFシーケンスを生成します。実用性には限りがありますが、Deep Nostalgiaはビンテージ写真に新たな息吹を与える能力から有名になりました。このアプリの魅力は、歴史的な写真や大切な人々の写真を生き返らせ、鑑賞者に強い感情を引き起こすことができる点にあります。アプリの機能はシンプルです:ユーザーは、自分の顔が見える画像をアップロードする必要があります。MyHeritageの人気は、クラウドベースの処理サービスの利便性と低コストに一部起因しています。結果の品質は比較的基本的であり、同じテンプレートの動きが繰り返し使用されることが多いです。Deep Nostalgiaにはソーシャル機能や手動コントロールの余地、個人化の余地はありません。いずれにせよ、Deep Nostalgiaはユーモアのあるアプローチでヴィンテージの画像にノスタルジアを追加したい人々にとって有益なツールです。 Wombo…

「FLM-101Bをご紹介します:1010億パラメータを持つ、オープンソースのデコーダのみのLLM」
最近、大規模言語モデル(LLM)はNLPとマルチモーダルタスクで優れた成績を収めていますが、高い計算コストと公正な評価の困難さという2つの重要な課題に直面しています。これらのコストはLLMの開発を一部の主要プレーヤーに制限し、研究と応用を制約しています。この問題に対処するため、この論文では成長戦略を紹介し、LLMのトレーニング費用を大幅に削減することを重視しています。 トレーニングコストの課題に対処するため、研究者は成長戦略によって100BのLLMをトレーニングしています。成長とは、パラメータの数がトレーニングプロセスで固定されず、小さいサイズから大きなサイズに拡大することを意味します。大規模言語モデル(LLM)の知能を評価するために、研究者は包括的なIQ評価ベンチマークを開発しました。このベンチマークは、知能の以下の4つの重要な側面を考慮しています: シンボリックマッピング:シンボリックマッピングアプローチを使用して、LLMの新しい文脈への一般化能力がテストされます。これは、カテゴリラベルではなく記号を使用する研究と似ています。 ルール理解:ベンチマークは、LLMが確立されたルールを理解し、適切なアクションを実行できるかどうかを評価し、人間の知能の重要な側面です。 パターンマイニング:LLMは、帰納的および演繹的な推論を通じてパターンを認識する能力を評価されます。これは、さまざまなドメインでのパターンマイニングの重要性を反映しています。 抗干渉能力:この指標は、外部ノイズの存在下でLLMのパフォーマンスを維持する能力を測定し、干渉に対する抵抗力と関連する知能の核心的な側面を強調します。 この研究の主な貢献は次のように要約されます: この研究は、成長戦略を用いて、予算がわずか10万ドルで1000億以上のパラメータを持つ大規模言語モデル(LLM)を成功裏にトレーニングするという先駆的な成果です。 研究者は、FreeLMトレーニング目標の改善、ハイパーパラメータの最適化のための有望な手法、および関数保存型成長の導入により、LLMトレーニングのさまざまな不安定性の問題に取り組んでいます。これらの方法論の改善は、広範な研究コミュニティに有望です。 包括的な実験が行われ、確立された知識指向のベンチマークだけでなく、新しい体系的なIQ評価ベンチマークも含まれています。これらの実験により、モデルは堅固なベースラインモデルと比較され、FLM-101Bの競争力のあるかつ頑強なパフォーマンスが示されます。 研究チームは、モデルのチェックポイント、コード、関連ツール、その他のリソースを公開することで、研究コミュニティに重要な貢献をしました。これらの資産は、1000億以上のパラメータを持つバイリンガルな中国語と英語のLLMのドメインでのさらなる研究を促進することを目的としています。 全体的に、この研究は、費用効果の高いLLMトレーニングの実現可能性を示すだけでなく、これらのモデルの知能を評価するためのより堅牢なフレームワークに貢献し、結果としてAGIの実現に一歩近づけることを目指しています。

4/9から10/9までの週のためのトップ重要なコンピュータビジョンの論文
「コンピュータビジョンは、機械に視覚世界を解釈し理解させる人工知能の分野であり、画期的な研究と技術の進展により急速に進化しています…」

「プログラマーのための10の数学の概念」
「プロのプログラマになるための秘密 - 数学とそのトップ10の概念」

「2023年9月のベストデータ抽出ツール10選」
現代のデジタル時代では、データはしばしば石油に喩えられますそれは、精製されることでイノベーションを推進し、業務を効率化し、意思決定プロセスを支える貴重な資源ですしかし、データを分析して実践的な洞察に変換する前に、まず多種多様なプラットフォーム、アプリケーション、システムから効果的にデータを入手し抽出する必要があります

タイム100 AI:最も影響力のあるもの?
『タイム誌が、Time 100 AIリストを発表しましたこのリストは、リーダーやイノベーターなどのカテゴリーで、AIの100人の重要な人物を紹介していますこのリストは、AIの進歩の背後にある人間の努力を強調することを目的としていますこのリストは、メインストリームメディアがAIの風景をどのように見ているかを示すスナップショットとして機能し、様々な要素を提供します...』

「YaRNに会ってください:トランスフォーマーベースの言語モデルのコンテキストウィンドウを拡張するための計算効率の高い方法で、以前の方法よりもトークンが10倍少なく、トレーニングステップが2.5倍少なくて済みます」
Chat GPTのような大規模言語モデルは、テキストのより広範な文脈を考慮することができ、より一貫性のある文脈に即した応答を理解し生成することができます。これは、テキスト補完などのタスクにおいて、ドキュメント全体の文脈を理解することが重要な場合に特に役立ちます。 これらのモデルは、トークンが多くなる場合であっても、ドキュメント内の複雑な関係や依存関係を捉えることができます。GPT-3やGPT-4のような大規模言語モデルにおける文脈ウィンドウの拡張とは、モデルが言語を生成または理解する際に考慮するテキストまたはトークンの範囲を指します。これは、要約文書のようなタスクにおいて、ドキュメントを包括的に理解した上で要約を行う必要がある場合に価値があります。 Rotary position embedding(RoPE)は、モデルが順序データを処理し、シーケンス内の位置情報を捉える能力を向上させます。ただし、これらのモデルは、彼らが訓練されたシーケンスの長さを超えて一般化する必要があります。Nous Research、Eleuther AI、およびジュネーブ大学の研究者は、このようなモデルの文脈ウィンドウを効率的に拡張する方法であるYaRN(Yet another RoPE extension method)を提案しています。 RoPEは、複素数の回転を使用する回転位置埋め込みであり、モデルが固定された位置埋め込みだけに頼らずに位置情報を効果的にエンコードすることを可能にします。これにより、モデルは長距離の依存関係をより正確に捉えることができます。回転を制御するパラメータは、モデルの訓練プロセス中に学習されます。モデルは適応的に回転を調整して、トークン間の位置関係を最もよく捉えることができます。 彼らが行った手法は、文脈ウィンドウを拡張するために外部メモリメカニズムを使用する圧縮トランスフォーマです。彼らは外部メモリバンクから情報を保存し、取得することで、通常のウィンドウサイズを超えた文脈にアクセスすることができます。トランスフォーマのアーキテクチャの拡張により、メモリコンポーネントが開発され、モデルは過去のトークンや例から情報を保持し利用することができます。 彼らの実験では、YaRNはわずか400ステップのトレーニングでLLMの文脈ウィンドウの拡張を成功させました。これは、モデルの元の事前トレーニングコーパスの0.1%に相当し、25からの10倍の削減、および7からの2.5倍のトレーニングステップの削減です。これにより、追加の推論コストなしで非常に計算効率が高くなります。 全体的に、YaRNはすべての既存のRoPE補間手法を改善し、PIを置き換えるだけであり、実装努力も最小限です。微調整モデルは複数のベンチマークで元の機能を保持しながら、非常に大きなコンテキストサイズに対応することができます。将来の研究では、伝統的なNLPモデルと組み合わせることができるメモリ拡張が関与することができます。トランスフォーマベースのモデルは、外部メモリバンクを組み込むことで、質問応答や機械翻訳などの下流タスクに関連する情報をコンテキストに保存して利用することができます。

「新しいコードが量子コンピューティングを10倍効率化する可能性」
量子コンピューティングはまだ非常に難しいですしかし、強力な誤り訂正コードの出現は、この課題が多くの人々が恐れていたよりもわずかに実現可能である可能性を示唆しています
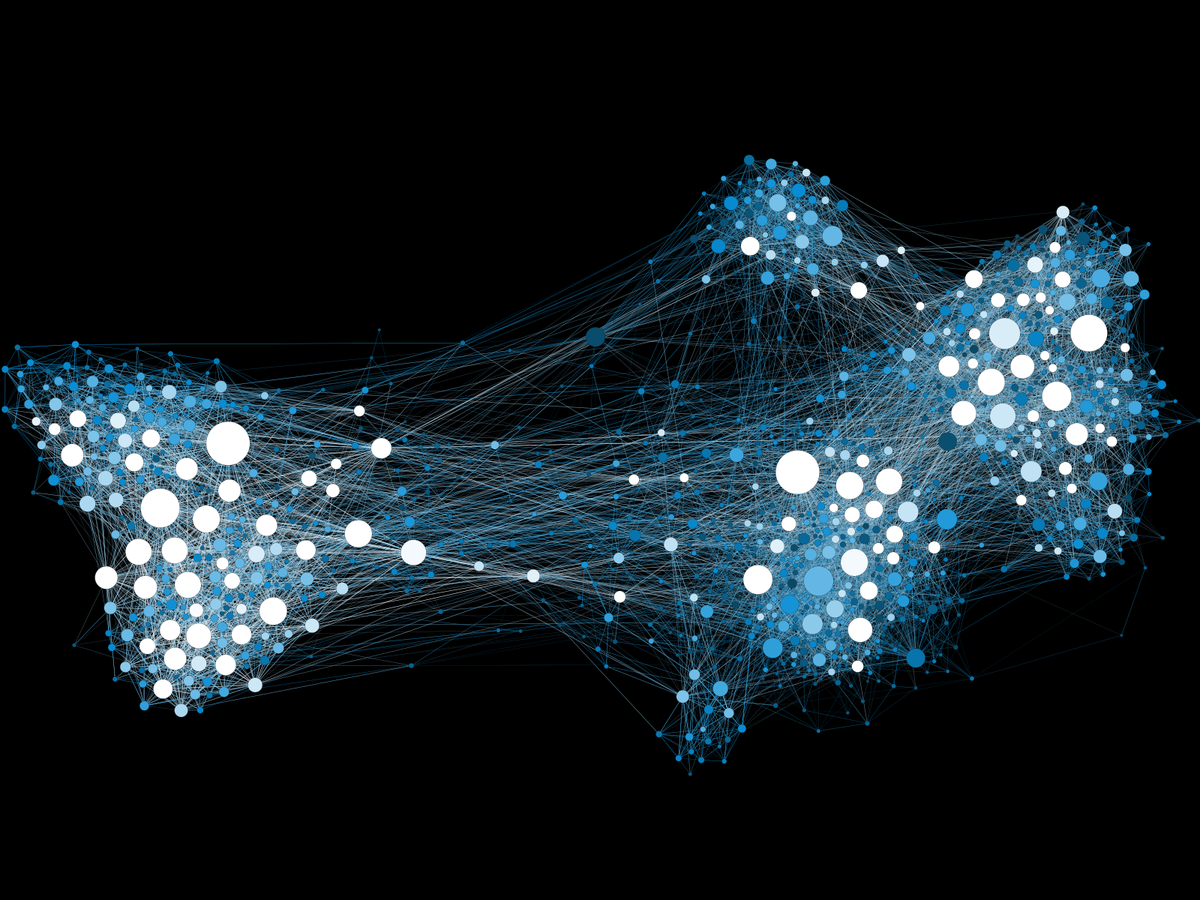
シミュレーション106:ネットワークを用いた情報拡散と社会伝染のモデリング
「ソーシャルメディアは情報の風景を完全に変革しました人類史上でこれほどお互いにつながっていることはありませんニュース記事は瞬時に私たちに届き、アイデア...」

「AIとMLが高い需要になる10の理由」 1. ビッグデータの増加による需要の増加:ビッグデータの処理と分析にはAIとMLが必要です 2. 自動化の需要の増加:AIとMLは、自動化されたプロセスとタスクの実行に不可欠です 3. 予測能力の向上:AIとMLは、予測分析において非常に効果的です 4. パーソナライズされたエクスペリエンスの需要:AIとMLは、ユーザーの行動と嗜好を理解し、パーソナライズされたエクスペリエンスを提供するのに役立ちます 5. 自動運転技術の需要の増加:自動運転技術の発展にはAIとMLが不可欠です 6. セキュリティの需要の増加:AIとMLは、セキュリティ分野で新たな挑戦に対処するために使用されます 7. ヘルスケアの需要の増加:AIとMLは、病気の早期検出や治療計画の最適化など、医療分野で重要な役割を果たします 8. クラウドコンピューティングの需要の増加:AIとMLは、クラウドコンピューティングのパフォーマンスと効率を向上させるのに役立ちます 9. ロボティクスの需要の増加:AIとMLは、ロボットの自律性と学習能力を高めるのに使用されます 10. インターネットオブシングス(IoT)の需要の増加:AIとMLは、IoTデバイスのデータ分析と制御に重要な役割を果たします
「2024年におけるAIとMLの需要急増を促している10の主要な要因を発見し、さまざまな産業で探求しましょう技術の未来を探索しましょう」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.