Learn more about Search Results ランキング - Page 13

- You may be interested
- 「咳の音を分析してCOVID-19患者の重症度...
- ウェブコンテンツの選択肢と制御を進化さ...
- 「ChatGPTを使用してAI幻覚を回避する方法」
- 「GPT-4の高度なデータ分析ツールを使った...
- スターバックスの報酬プログラムの成功を...
- 「機械学習入門:その多様な形式を探索する」
- 2024年に使用するためのトップ5の生成AIラ...
- 「Baichuan-13Bに会いましょう:中国のオ...
- 「線形代数1:線形方程式とシステム」
- 「AI革命:主要産業における応用とユース...
- 「AIの使用を支持する俳優たちと、支持し...
- 感情AIの科学:アルゴリズムとデータ分析...
- 「意思決定の解放:AIが理論的な枠組みと...
- 「Python初心者のための独自のPythonパッ...
- 思っているベイダーではありません 3D VAD...

「Falcon 180Bをご紹介します:1800億のパラメータを持つ、公開されている最大の言語モデル」
強力かつ多目的な言語モデルへの需要は、自然言語処理と人工知能においてますます迫り来るものとなっています。これらのモデルは、チャットボットや仮想アシスタントから機械翻訳や感情分析まで、多数のアプリケーションの基盤となっています。しかし、さまざまな言語のタスクで優れたパフォーマンスを発揮できる言語モデルを構築することは、依然として複雑な課題です。最近のブレークスルーは、この中心的な問題に対処することを目指しています。 先進的な言語モデルの開発を追求するなかで、研究者はしばしばモデルのサイズ、トレーニングデータ、多目的性に関連する制約に直面してきました。これらの制約により、異なるモデルが特定のタスクで優れている一方で、真にワンサイズフィットオールの解決策と言えるのは一部のモデルに限られています。 テクノロジーイノベーション研究所(TII)の研究者は、画期的な言語モデル「Falcon 180B」を紹介しました。Falcon 180Bは、1800億のパラメータを誇る言語モデルの飛躍的な進化を体現しています。しかし、これまでのモデルや競合他社との差別化要因は、そのサイズと多目的性、そして利用のしやすさにあります。Falcon 180Bは最初の大規模な言語モデルではありませんが、オープンアクセスの性質が特徴です。多くのクローズドソースモデルがプロプライエタリなままであるのに対し、Falcon 180Bは研究や商業利用のために利用可能に設計されています。このオープンアクセスへのシフトは、透明性と協力がますます重要視されるAIコミュニティ全体のトレンドと一致しています。 Falcon 180Bの素晴らしい機能は、驚異的な3.5兆のトークンを含む多様なデータセットでのトレーニングによってもたらされています。この膨大なテキストコーパスにより、モデルは言語と文脈の理解において他に類を見ない能力を持ち、幅広い自然言語処理タスクで優れたパフォーマンスを発揮することができます。 このモデルの主な強みの一つは、推論、コーディング、熟練度評価、知識テストなど、多様な言語タスクを処理できる能力です。この多目的性は、ウェブデータ、会話、技術論文、さらにはコードの一部まで含まれる豊富で多様なデータセットに対するトレーニングによるものです。Falcon 180Bは、MetaのLLaMA 2などのクローズドソースの競合モデルに引けを取らないパフォーマンスを発揮します。 Falcon 180Bの重要性を示すものとして、Hugging Face Leaderboardでのランキングが挙げられます。現在、Falcon 180Bは競争力のあるスコア68.74を保持しており、このリーダーボードのランキングは、多くの言語関連の課題に対応できるトップクラスの言語モデルであることを確固たるものにしています。 まとめると、TIIのFalcon 180Bは自然言語処理の分野において大きな進歩を表しています。そのサイズ、トレーニングデータ、オープンアクセスの可用性により、研究者や開発者にとって強力かつ多目的なツールとなっています。Falcon 180Bをオープンアクセスに提供するという決定は、透明性と協力の重要性が増しているAIコミュニティとの一致点として特筆されます。 Falcon 180Bの導入による影響は広範囲に及びます。1800億のパラメータを持つオープンアクセスモデルを提供することで、TIIは研究者や開発者が自然言語処理の新たな領域を探求する力を与えます。クローズドソースの対抗モデルと比較して、このモデルの競争力のあるパフォーマンスは、医療、金融、教育などさまざまな分野でのイノベーションの可能性を広げるものです。 さらに、Falcon 180Bの成功は、AIにおけるオープンソースイニシアチブの価値を示しています。研究者が協力とアクセス可能性を優先すると、AIのブレークスルーはより広範な観衆にとってアクセス可能になります。AIコミュニティが透明性、協力、AIの能力の向上に取り組む原則をますます受け入れていく中で、Falcon…
2v2ゲームのためのデータ駆動型Eloレーティングシステムの作成方法
「2v2のEloベースのスコアリングシステムを探索しましょうフーズボールやマルチプレイヤーゲームに最適です数学、データベースモデリング、およびその応用を発見してください」

「Appleの研究者たちは、暗黙的なフィードバックを持つ協調フィルタリングのための新しいテンソル分解モデルを提案する」
過去の行動からユーザーの好みを推測する能力は、効果的な個別の提案にとって重要です。多くの製品には星の評価がないため、このタスクは指数関数的に困難になります。過去の行動は一般的にバイナリ形式で解釈され、ユーザーが過去に特定のオブジェクトと対話したかどうかを示します。このバイナリデータに基づいて、そのような秘匿的な入力からユーザーの好みを推測するために、追加の仮定をする必要があります。 視聴者は、関与したコンテンツを楽しんでおり、注意を引かなかったコンテンツは無視しているという仮定は、実際の使用ではめったに正確ではありません。消費者が製品と関わっていないのは、それが存在すら知らないためかもしれません。したがって、ユーザーが単に対話できない要素については無視または関心を持っていないと仮定するのがより妥当です。 研究では、既に馴染みのある製品を未知の製品よりも好む傾向があると仮定しました。この考えは、個別の推奨を行うための技術であるベイジアン個別ランキング(BPR)の基礎となりました。BPRでは、データはユーザーを表す最初の次元を持つ3次元のバイナリテンソルDに変換されます。 新しいAppleの研究では、推移性に依存しない人気のある基本的な製品の評価(BPR)モデルの変種を作成しました。一般化のために、彼らは代替テンソル分解を提案しています。彼らはスライス反対称分解(SAD)という新しい暗黙のフィードバックベースの協調フィルタリングモデルを導入します。ユーザーとアイテムの相互作用の新しい三次元テンソルの視点を使用して、SADは通常の方法とは異なり、各アイテムに1つの潜在ベクトルを追加します(アイテムベクトルとしての潜在表現を推定する従来の方法とは異なります)。相対的な優先順位を評価する際にアイテム間の相互作用を生成するため、この新しいベクトルは通常の内積によって導かれる好みを一般化します。ベクトルが1に収束すると、SADは最新の協調フィルタリングモデル(SOTA)となります。この研究では、その値をデータから決定することを許可しています。新しいアイテムベクトルの値が1を超えることを許可すると、非常に重要な結果が生じます。対比の中にサイクルが存在することは、ユーザーのメンタルモデルが線形ではないことを示す証拠と解釈されます。 チームはSADパラメータ推定のためのクイックなグループ座標降下法を提案しています。シンプルな確率的勾配降下法(SGD)を使用して、正確なパラメータ推定を迅速に行います。シミュレーション研究を使用して、まずSGDの効果とSADの表現力を実証します。そして、利用可能なリソースのトリオを使用して、SADを他の7つの代替の最新の推奨モデルと比較します。この研究では、以前無視されていたデータとエンティティ間の関係を組み込むことで、更新されたモデルがより信頼性の高い正確な結果を提供することも示しています。 この研究では、研究者は協調フィルタリングを暗黙のフィードバックとして参照しています。ただし、SADの応用範囲は前述のデータタイプに限定されません。たとえば、明示的な評価が含まれるデータセットは、現在のモデルの一貫性を事後評価するのではなく、モデルの適合中に直ちに使用できる部分順序を含んでいます。
「GenAIソリューションがビジネス自動化を革新する方法:エグゼクティブ向けLLMアプリケーションの解説」
最近、バイオファーマ企業の製造エグゼクティブとの協力により、私たちは生成型AI、具体的には大規模な言語モデル(LLM)の世界に深く入り込み、それらがどのように利用できるかを探求しました...

OpenAIとLangChainによるMLエンジニアリングとLLMOpsへの導入
「OpenAI LLMsの操作方法とPythonでの人気のあるLangChainツールキットの使用方法を理解する書籍『Machine Learning Engineering with Python』からの抜粋、Packt、2023年」

ContentStudio レビュー:ソーシャルメディアにおける最高のAIツール?(2023年9月)
「ContentStudioがあなたのビジネスに最適なソーシャルメディア管理プラットフォームかどうか疑問に思っていますか?詳細なContentStudioレビューを読んで、それを知ることができます!」

「OpenAI WhisperとHugging Chat APIを使用したビデオの要約」
イントロダクション 建築家ルートヴィヒ・ミース・ファン・デル・ローエが有名になったように、「少ないことがより多い」ということは、要約の意味です。要約は、膨大なテキストコンテンツを簡潔で関連性のある要素にまとめるための重要なツールであり、現代の情報消費スピードに適したものです。テキストアプリケーションでは、要約は情報の検索を支援し、意思決定をサポートします。Generative AI(OpenAI GPT-3ベースのモデルなど)の統合により、テキストから重要な要素を抽出し、ソースの本質を保持したまま意味のある要約を生成するというプロセスが革新されました。興味深いことに、Generative AIの機能は、テキストにとどまらず、ビデオ要約にも広がっています。これには、ビデオから重要なシーン、対話、概念を抽出し、コンテンツの要約を作成することが含まれます。ビデオ要約は、短い要約ビデオを生成したり、ビデオコンテンツの分析を行ったり、ビデオのキーセクションを強調表示したり、ビデオのテキスト要約を作成するなど、さまざまな方法で実現できます。 Open AI Whisper APIは、自動音声認識技術を活用して話された言語を書かれたテキストに変換することで、テキストの要約の正確さと効率性を向上させます。一方、Hugging Face Chat APIは、GPT-3などの最先端の言語モデルを提供します。 学習目標 この記事では、以下のことを学びます: ビデオ要約の技術について学ぶ ビデオ要約の応用について理解する Open AI Whisperモデルのアーキテクチャを探索する Open AI WhisperとHugging Chat APIを使用してビデオテキスト要約を実装する方法を学ぶ…

2023年のトップ5の建築学校
「新しい人生の章として学生としての生活を始める準備をする際、人々は申し込む学校を探します個人の基準があり、それぞれの視点から各学校を評価しますどの学校を選ぶか迷っている人は、トップの大学や学校のリストを参考にします今日は、2023年のトップ5の建築学校について話します... 詳細を読む »」
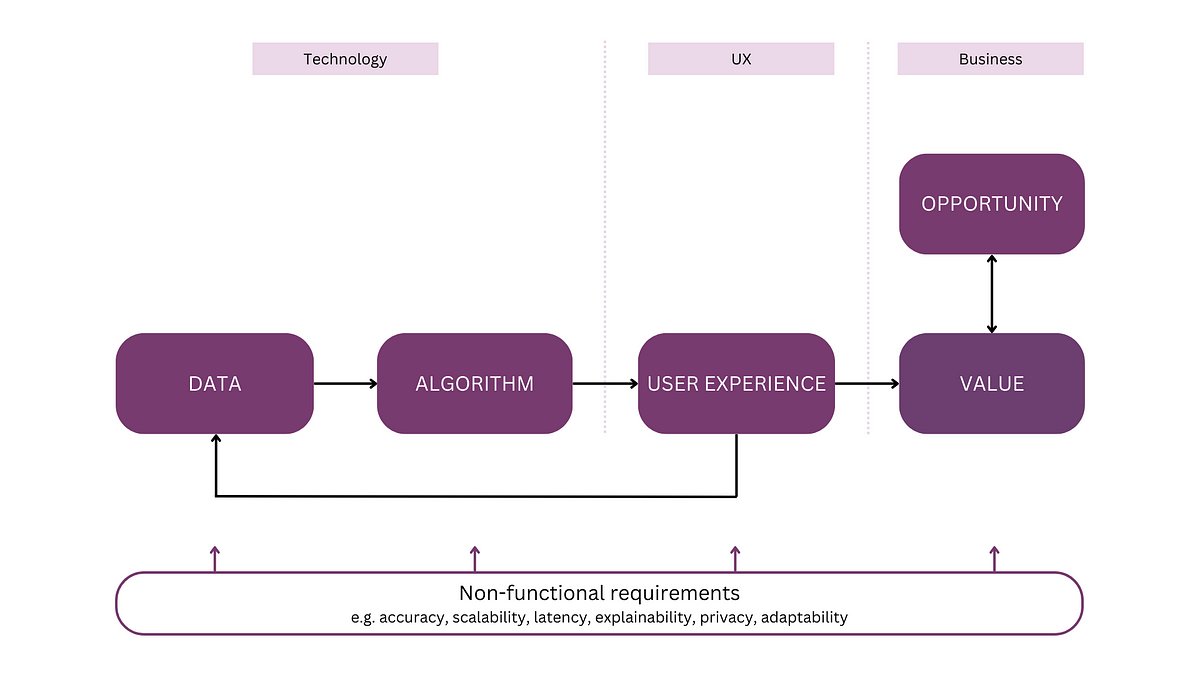
「全体的なメンタルモデルを持つAI製品の開発」
注:この記事は「AIアプリケーションの解析」というシリーズの最初の記事ですこのシリーズでは、AIシステムのためのメンタルモデルを紹介しますこのモデルは、議論や計画、そして...のためのツールとして機能します

このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
最近、機械学習の検索分野において、深層ニューラルネットワークを応用することで大きな進歩がありました。特に、バイエンコーダーアーキテクチャ内の表現学習に重点を置いています。このフレームワークでは、クエリ、パッセージ、さらには画像などのマルチメディアなど、さまざまな種類のコンテンツが、密なベクトルとして表されるコンパクトで意味のある「埋め込み」として変換されます。このアーキテクチャに基づいて構築されたこれらの密な検索モデルは、大規模な言語モデル(LLM)内の検索プロセスの強化の基盤として機能します。このアプローチは人気があり、現在の生成的AIの広い範囲でLLMの全体的な能力を高めるのに非常に効果的であることが証明されています。 この論文では、多くの密なベクトルを処理する必要があるため、企業は「AIスタック」に専用の「ベクトルストア」または「ベクトルデータベース」を組み込むべきだと示唆しています。一部のスタートアップ企業は、これらのベクトルストアを革新的で不可欠な現代の企業アーキテクチャの要素として積極的に推進しています。有名な例には、Pinecone、Weaviate、Chroma、Milvus、Qdrantなどがあります。一部の支持者は、これらのベクトルデータベースが従来のリレーショナルデータベースをいずれ置き換える可能性さえ示しています。 この論文では、この説に対して反論を示しています。その議論は、既存の多くの組織で存在し、これらの機能に大きな投資がなされているという点を考慮した、簡単なコスト対効果分析を中心に展開されています。生産インフラストラクチャは、Elasticsearch、OpenSearch、Solrなどのプラットフォームによって主導されている、オープンソースのLucene検索ライブラリを中心とした広範なエコシステムによって支配されています。 https://arxiv.org/abs/2308.14963 上記の画像は、標準的なバイエンコーダーアーキテクチャを示しており、エンコーダーがクエリとドキュメント(パッセージ)から密なベクトル表現(埋め込み)を生成します。検索はベクトル空間内のk最近傍探索としてフレーム化されています。実験は、ウェブから抽出された約880万のパッセージから構成されるMS MARCOパッセージランキングテストコレクションに焦点を当てて行われました。評価には、標準の開発クエリとTREC 2019およびTREC 2020 Deep Learning Tracksのクエリが使用されました。 調査結果は、今日ではLuceneを直接使用してOpenAIの埋め込みを使用したベクトル検索のプロトタイプを構築することが可能であることを示唆しています。埋め込みAPIの人気の増加は、私たちの主張を支持しています。これらのAPIは、コンテンツから密なベクトルを生成する複雑なプロセスを簡素化し、実践者にとってよりアクセスしやすくしています。実際には、今日の検索エコシステムを構築する際に必要なのはLuceneだけです。しかし、時間が経って初めて正しいかどうかがわかります。最後に、これはコストと利益を比較することが主要な考え方であり続けることを思い起こさせてくれるものです。急速に進化するAIの世界でも同様です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.