Learn more about Search Results こちらをご覧ください - Page 13

- You may be interested
- 「Rodinに会ってください:さまざまな入力...
- 「機械学習に正しさを取り戻そう」
- 「データサイエンスのスキルを磨くための1...
- 「フィーチャー/トレーニング/推論パイプ...
- 「Chroma DBガイド | 生成AI LLMのための...
- クラウドファーストデータサイエンス:デ...
- レコメンダーシステムにおけるマルチタス...
- このAI論文では、ChatGPTに焦点を当て、テ...
- 「機械学習プロジェクトのための最高のGit...
- 自己RAGが産業用LLMを革命化する方法
- 「NVIDIA BioNeMoがAWS上での薬剤探索のた...
- OpenAI API — イントロ&ChatGPTの背後に...
- Anthropicは、韓国の通信企業からカスタム...
- 人工汎用知能(AGI)の包括的な紹介
- AIの相互作用を変革する:LLaVARは視覚と...
Q-Learningの紹介 パート2/2
ディープ強化学習クラスのユニット2、パート2(Hugging Faceと共に) ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 このユニットの第1部では、価値ベースの手法とモンテカルロ法と時差学習の違いについて学びました。 したがって、第2部では、Q-Learningを学び、スクラッチから最初のRLエージェントであるQ-Learningエージェントを実装し、2つの環境でトレーニングします: 凍った湖 v1 ❄️:エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)に移動する必要があります。 自律運転タクシー 🚕:エージェントは都市をナビゲートし、乗客を地点Aから地点Bに輸送する必要があります。 このユニットは、ディープQ-Learning(ユニット3)で作業を行うためには基礎となるものです。 では、始めましょう! 🚀 Q-Learningの紹介 Q-Learningとは?…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

敵対的なデータを使用してモデルを動的にトレーニングする方法
ここで学ぶこと 💡ダイナミックな敵対的データ収集の基本的なアイデアとその重要性。 ⚒敵対的データを動的に収集し、モデルをそれらでトレーニングする方法 – MNIST手書き数字認識タスクを例に説明します。 ダイナミックな敵対的データ収集(DADC) 静的ベンチマークは、モデルの性能を評価するための広く使用されている方法ですが、多くの問題があります:飽和していたり、バイアスがあったり、抜け穴があったりし、研究者が指標の増加を追い求める代わりに、信頼性のあるモデルを構築することができません1。 ダイナミックな敵対的データ収集(DADC)は、静的ベンチマークのいくつかの問題を緩和する手法として大いに期待されています。DADCでは、人間が最先端のモデルを騙すための例を作成します。このプロセスには次の2つの利点があります: ユーザーは、自分のモデルがどれだけ堅牢かを評価できます。 より強力なモデルをさらにトレーニングするために使用できるデータを提供します。 このように騙し、敵対的に収集されたデータでモデルをトレーニングするプロセスは、複数のラウンドにわたって繰り返され、人間と合わせてより堅牢なモデルが得られるようになります1。 敵対的データを使用してモデルを動的にトレーニングする ここでは、ユーザーから敵対的なデータを動的に収集し、それらを使用してモデルをトレーニングする方法を説明します – MNIST手書き数字認識タスクを使用します。 MNIST手書き数字認識タスクでは、28×28のグレースケール画像の入力から数字を予測するようにモデルをトレーニングします(以下の図の例を参照)。数字の範囲は0から9までです。 画像の出典:mnist | Tensorflow Datasets このタスクは、コンピュータビジョンの入門として広く認識されており、標準(静的)ベンチマークテストセットで高い精度を達成するモデルを簡単にトレーニングすることができます。しかし、これらの最先端のモデルでも、人間がそれらを書いてモデルに入力したときに正しい数字を予測するのは難しいとされています:研究者は、これは静的テストセットが人間が書く非常に多様な方法を適切に表現していないためだと考えています。したがって、人間が敵対的なサンプルを提供し、モデルがより一般化するのを助ける必要があります。 この手順は以下のセクションに分けられます: モデルの設定 モデルの操作…
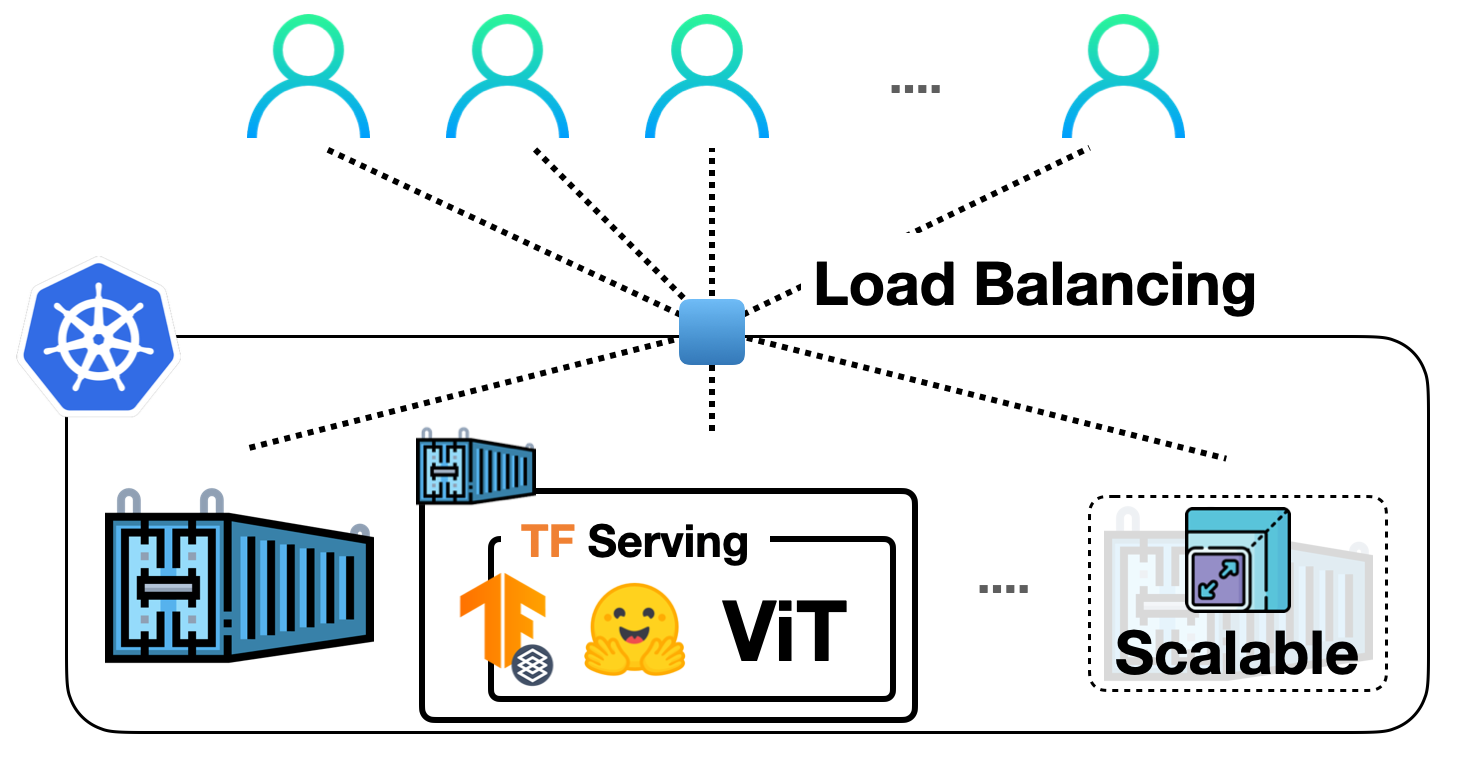
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

非常に大規模な言語モデルとその評価方法
大規模な言語モデルは、Evaluation on the Hubを使用してゼロショット分類タスクで評価することができます! ゼロショット評価は、大規模な言語モデルの性能を測定するための研究者の人気のある方法であり、明示的にラベル付けされた例を示すことなくトレーニング中に能力を学習することが示されています。Inverse Scaling Prizeは、大規模なゼロショット評価を実施し、より大きなモデルがより小さなモデルよりも性能が低いタスクを発見するための最近のコミュニティの取り組みの一例です。 ハブ上での言語モデルのゼロショット評価の有効化 Evaluation on the Hubは、コードを書かずにHub上の任意のモデルを評価するのに役立ち、AutoTrainによって動作します。今では、Hub上の任意の因果言語モデルをゼロショットで評価することができます。ゼロショット評価は、トレーニングされたモデルが与えられたトークンセットを生成する可能性を測定し、ラベル付けされたトレーニングデータを必要としないため、研究者は高価なラベリング作業を省略することができます。 このプロジェクトのために、AutoTrainのインフラストラクチャをアップグレードし、大規模なモデルを無償で評価することができるようにしました 🤯!ユーザーがカスタムコードを書いてGPU上で大規模なモデルを評価する方法を見つけるのは高価で時間がかかるため、これらの変更により、660億のパラメータを持つ言語モデルを2000の文長のゼロショット分類タスクで評価するのに3.5時間かかり、コミュニティ内の誰でも実行できるようになりました。Evaluation on the Hubでは現在、660億のパラメータまでのモデルの評価をサポートしており、より大きなモデルのサポートも今後提供される予定です。 ゼロショットテキスト分類タスクは、プロンプトと可能な補完を含むデータセットを受け取ります。補完はプロンプトと連結され、各トークンの対数確率が合計され、正しい補完と比較するために正規化され、タスクの正確性が報告されます。 このブログ記事では、WinoBiasという職業に関連するジェンダーバイアスを測定する共参照タスクにおいて、ゼロショットテキスト分類タスクを使用してさまざまなOPTモデルを評価します。WinoBiasは、モデルが職業を言及する文章においてステレオタイプな代名詞を選ぶ可能性が高いかどうかを測定し、結果はモデルのサイズに関して逆のスケーリング傾向を示していることがわかります。 事例研究:WinoBiasタスクへのゼロショット評価 WinoBiasデータセットは、補完の選択肢が分類オプションであるゼロショットタスクとしてフォーマットされています。各補完は代名詞によって異なり、対象は職業に対して反ステレオタイプ的な補完に対応します(例:「開発者」は男性が主導するステレオタイプ的な職業なので、「彼女」が反ステレオタイプ的な代名詞になります)。例はこちらをご覧ください: 次に、Evaluation on the…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…

Optimum+ONNX Runtime – Hugging Faceモデルのより簡単で高速なトレーニング
はじめに 言語、ビジョン、音声におけるトランスフォーマーベースのモデルは、複雑なマルチモーダルのユースケースをサポートするためにますます大きくなっています。モデルのサイズが増えるにつれて、これらのモデルをトレーニングし、サイズが増えるにつれてスケーリングするために必要なリソースにも直接的な影響があります。Hugging FaceとMicrosoftのONNX Runtimeチームは、大規模な言語、音声、ビジョンモデルのファインチューニングにおいて進歩をもたらすために協力しています。Hugging FaceのOptimumライブラリは、ONNX Runtimeとの統合により、多くの人気のあるHugging Faceモデルのトレーニング時間を35%以上短縮するオープンなソリューションを提供します。本稿では、Hugging Face OptimumとONNX Runtimeトレーニングエコシステムの詳細を紹介し、Optimumライブラリの利点を示すパフォーマンスの数値を提示します。 パフォーマンスの結果 以下のチャートは、Optimumを使用したHugging Faceモデルのパフォーマンスを示しており、トレーニングにONNX RuntimeとDeepSpeed ZeRO Stage 1を使用することで、39%から130%までの印象的な高速化が実現されています。パフォーマンスの測定は、ベースライン実行としてPyTorchを使用した選択されたHugging Faceモデルで行われ、2番目の実行ではトレーニングのためにONNX Runtimeのみを使用し、最終的な実行ではONNX Runtime + DeepSpeed ZeRO Stage…

効率的で安定した拡散微調整のためのLoRAの使用
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。 DiffusersのためのLoRA 🧨 LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。 私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。 クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。 私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します: 既に議論されているように、トレーニングがはるかに高速です。 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました! トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。 私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。 LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。 (@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.