Learn more about Search Results こちらの - Page 13

- You may be interested
- マルチモーダル言語モデルの解説:ビジュ...
- 「LLMモニタリングと観測性 – 責任...
- 「ChatGPT APIのカスタムメモリ」
- UCバークレーとスタンフォード大学の研究...
- 「Streamlit、OpenAI、およびElasticsearc...
- LLaMA 皆のためのLLM!
- 時系列データのフーリエ変換 numpyを使用...
- このAI論文では、大規模なマルチモーダル...
- 『広範な展望:NVIDIAの基調講演がAIの更...
- 大規模データ分析のエンジンとしてのゲー...
- Googleはカナダに「リンク税」を支払わな...
- 新しいNVIDIA GPUベースのAmazon EC2イン...
- 「人工知能のイメージング:GANの複雑さと...
- 「Spotifyのデータサイエンティストによる...
- Eleuther AI Research Groupが、Classifie...
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…

ディフューザを使用してControlNetをトレーニングしてください
イントロダクション ControlNetは、追加の条件を付加することで拡散モデルを細かく制御することができるニューラルネットワーク構造です。この技術は、「Adding Conditional Control to Text-to-Image Diffusion Models」という論文で登場し、すぐにオープンソースの拡散コミュニティで広まりました。著者はStable Diffusion v1-5を制御するための8つの異なる条件をリリースしました。これには、ポーズ推定、深度マップ、キャニーエッジ、スケッチなどが含まれます。 このブログ投稿では、3Dシンセティックフェイスに基づいた顔のポーズモデルであるUncanny Facesモデルのトレーニング手順を詳細に説明します(実際にはUncanny Facesは予期しない結果であり、それがどのように実現されたかについては後ほどご紹介します)。 安定した拡散のためのControlNetのトレーニングの始め方 独自のControlNetをトレーニングするには、3つのステップが必要です: 条件の計画:ControlNetはStable Diffusionをさまざまなタスクに対応できる柔軟性があります。事前にトレーニングされたモデルはさまざまな条件を示しており、コミュニティはピクセル化されたカラーパレットに基づいた他の条件を作成しています。 データセットの構築:条件が決まったら、データセットの構築の時間です。そのためには、データセットをゼロから構築するか、既存のデータセットの一部を使用することができます。モデルをトレーニングするためには、データセットには3つの列が必要です:正解のimage、conditioning_image、およびprompt。 モデルのトレーニング:データセットの準備ができたら、モデルのトレーニングの時間です。これは、ディフューザーのトレーニングスクリプトのおかげで最も簡単な部分です。少なくとも8GBのVRAMを持つGPUが必要です。 1. 条件の計画 条件を計画するために、次の2つの質問を考えると役立ちます: どのような条件を使用したいですか? 既存のモデルで「通常の」画像を私の条件に変換できるものはありますか?…
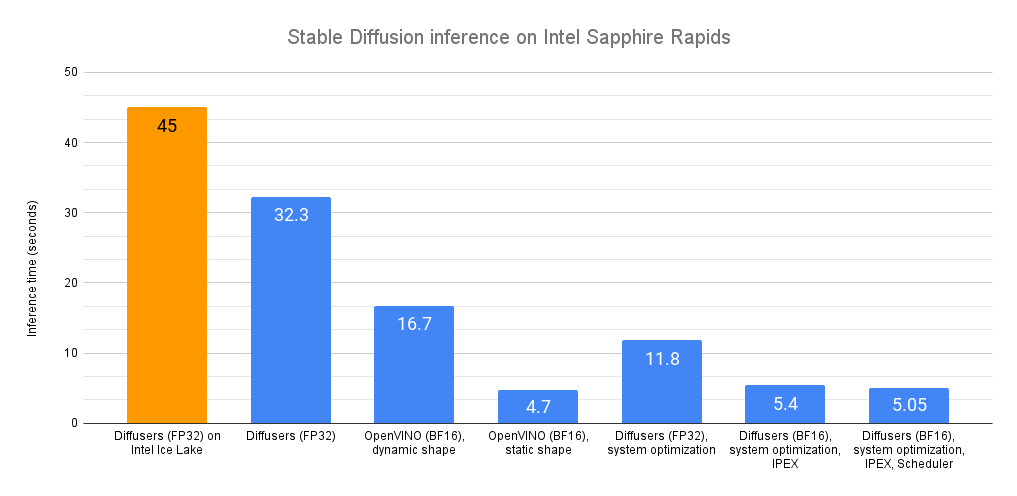
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…

Substraを使用してプライバシーを保護するAIの作成
最近、生成技術の台頭により、機械学習はその歴史の中でも非常に興奮する時期にあります。この台頭を支えるモデルは、効果的な結果を生み出すためにさらに多くのデータを必要とします。そのため、データの倫理的な収集方法を探求することがますます重要になってきています。また、データのプライバシーとセキュリティを最優先にすることも重要です。 医療などの機密情報を扱う多くの領域では、データハングリーなモデルを訓練するために十分な高品質なデータにアクセスできることがしばしばありません。データセットは異なる学術センターや医療機関に分断され、患者情報や独自の情報のプライバシー上の懸念から、公開共有することが難しい状況にあります。HIPAAなどの患者データを保護する規制は、個人の健康情報を保護するために不可欠ですが、データサイエンティストがモデルを効果的に訓練するために必要なデータのボリュームにアクセスできないため、機械学習の研究の進展を制限することがあります。既存の規制と協調して患者データを積極的に保護する技術は、これらの分断を解除し、これらの領域での機械学習の研究と展開のスピードを加速するために重要となります。 ここでフェデレーテッドラーニングが登場します。Substraと共に作成したこのスペースをチェックして、詳細をご覧ください! フェデレーテッドラーニングとは何ですか? フェデレーテッドラーニング(FL)は、複数のデータプロバイダを使用してモデルを訓練できる分散型の機械学習技術です。すべてのソースからデータを単一のサーバーに収集するのではなく、データはローカルサーバーに残り、結果のモデルの重みのみがサーバー間を移動します。 データが元のソースから出ないため、フェデレーテッドラーニングは自然にプライバシーを最優先とするアプローチです。この技術はデータのセキュリティとプライバシーを向上させるだけでなく、データ科学者が異なるソースのデータを使用してより良いモデルを構築することも可能にします。これにより、データの量の増加だけでなく、データキャプチャ技術や装置によるわずかな違い、または患者集団の人口統計の違いなど、基になるデータセットのバリエーションによるバイアスのリスクを軽減することができます。複数のデータソースを持つことで、現実の世界でより優れた性能を発揮するより汎用性のあるモデルを構築することができます。フェデレーテッドラーニングについての詳細については、Googleの説明漫画をチェックすることをお勧めします。 Substraは、現実のプロダクション環境向けに構築されたオープンソースのフェデレーテッドラーニングフレームワークです。フェデレーテッドラーニングは比較的新しい分野であり、過去10年間にのみ確立されてきましたが、既に医学研究の進展を以前にも増して可能にしています。たとえば、10の競合するバイオファーマ企業が、通常は互いにデータを共有しないような状況で、MELLODDYプロジェクトで協力し、世界最大の既知の生化学的または細胞活性を持つ小分子のコレクションを共有しました。これにより、関係するすべての企業が薬剤探索のためのより正確な予測モデルを構築することができました。これは医学研究における重要なマイルストーンです。 Substra x HF フェデレーテッドラーニングの能力に関する研究は急速に進んでいますが、最近の作業の大部分はシミュレートされた環境に限定されています。実世界の例や実装は、フェデレーテッドネットワークの展開と設計の難しさのためにまだ限られています。フェデレーテッドラーニング展開のためのリーディングオープンソースプラットフォームとして、Substraは多くの複雑なセキュリティ環境とITインフラストラクチャで戦闘テストされ、乳がん研究での医学的なブレークスルーを実現しています。 Hugging Faceは、Substraを管理しているチームと協力して、このスペースを作成しました。これは、研究者や科学者が直面する現実の課題、つまり「AIに適した」集中化された高品質データの不足を理解するためのものです。これらのサンプルの分布を制御できるため、単純なモデルがデータの変化にどのように反応するかを確認することができます。その後、フェデレーテッドラーニングで訓練されたモデルが、単一のソースのデータから訓練されたモデルと比較して、ほとんど常に検証データで優れたパフォーマンスを発揮するかどうかを調べることができます。 結論 フェデレーテッドラーニングがリードをしているものの、セキュアなエンクレーブやマルチパーティ計算などのさまざまなプライバシー強化技術(PET)もあり、フェデレーションと組み合わせてマルチレイヤのプライバシー保護環境を作成することができます。これらが医療分野での協力を可能にしている方法に興味がある場合は、こちらをご覧ください。 使用される方法に関係なく、データプライバシーは私たち全員の権利であることに注意することが重要です。AIブームをプライバシーと倫理に念頭に置いて前進することが重要です。 もしSubstraを試してみて、プロジェクトでフェデレーテッドラーニングを実装したい場合は、こちらのドキュメントをご覧ください。

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...

表現力豊かなブール式を使用した説明可能なAI
人工知能(AI)と機械学習の応用の急速な拡大は、ほぼすべての産業や生活の領域に浸透していますしかし、その成長には皮肉な側面もありますAIは意思決定やワークフローを簡素化または加速するために存在しているにもかかわらず、その方法論はしばしば非常に複雑です実際、一部の「ブラックボックス」機械学習アルゴリズムは非常に...

データサイエンスにおける正規分布の適用と使用
データサイエンスを始める際に非常に困難なことの一つは、その旅がどこから始まり、どこで終わるのかを正確に把握することですデータサイエンスの旅の終わりに関して言えば、それは...

人材分析のための R ツールキット:ヘッドカウントのストーリーを伝える
人事分析の仕事では、会社の従業員数や会社が今日のように進化する過程を伝えることが求められることがよくあります私はしばしばこれをウォーターフォールチャートとして提示されるのを見ますが、それは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.