Learn more about Search Results - Page 13

- You may be interested
- 「メタは、トレーニングにLLaMAモデルを使...
- AIガバナンス:専門家との深い探求
- SalesForce AI 研究 BannerGen マルチモダ...
- アジアにおける生成型AIの機会
- 「PythonでChatGPTを使用する方法」
- メディアでのアルコール摂取の検出:CLIP...
- 「スパースなデータセットの扱い方に関す...
- 僧侶の病気探偵:AI技術を活用した植物健...
- 初心者のための畳込みニューラルネットワーク
- 「アニマ・アナンドクマールとともにAIを...
- 「ChatGPTのためにNGINXを使用してOpenAI...
- ニューヨーク市の可視化
- UCサンタクルーズの研究者たちは、概念や...
- 最大のLLMベンチマーキングスイート:MEGA...
- 「LLMによる製品の発見:ハイブリッド検索...

「ビジュアルで高速にMLパイプラインを構築する方法!」
最近のディープラーニングの進歩が、リアルタイムメディアの使用例において、たくさんの機械学習(ML)モデルを生み出すことがどれほど注目されるべきか無視するのは難しいです例えば、背景を変える能力など様々な例があります

「グラフ機械学習 @ ICML 2023」
「壮大なビーチとトロピカルなハワイの風景🌴は、勇敢な科学者たちを国際機械学習会議に出席し、最新の研究成果を発表することから遠ざけませんでした...」

「Juliaプログラミング言語の探求:MongoDB」
「科学プログラミングのためのJuliaの機能を学ぶ旅へ、再びようこそ👋🤗!初めての方も大丈夫ですとても歓迎しますので、前回の記事を読むことをおすすめします…」
「Hugging Face Transformersライブラリを解剖する」
これは、実践的に大規模言語モデル(LLM)を使用するシリーズの3番目の記事ですここでは、Hugging Face Transformersライブラリについて初心者向けのガイドを提供しますこのライブラリは、簡単で...

大規模画像モデルのための最新のCNNカーネル
「OpenAIのChatGPTの驚異的な成功が大型言語モデルのブームを引き起こしたため、多くの人々が大型画像モデルにおける次のブレークスルーを予測していますこの領域では、ビジョンモデルは...」

マシンラーニングのロードマップ:コミュニティの推奨事項2023
前回の記事で、このロードマップの第1部では、機械学習のための出発点と方向性について簡単に説明しました初心者が堅固な基盤を築くためのシンプルな計画について話しました

「ソースフリーなドメイン適応の汎用的な方法を探求する」
Google の研究科学者であるエレニ・トリアンタフィルーと学生研究員であるマリック・ブディアフによって投稿されました。 ディープラーニングは、最近多くの問題とアプリケーションで著しい進歩を遂げていますが、モデルは未知のドメインや分布で展開された場合に予測不能に失敗することがよくあります。ソースフリーなドメイン適応(SFDA)は、事前にトレーニングされたモデル(「ソースドメイン」でトレーニングされたもの)を新しい「ターゲットドメイン」に適応させるための方法を、後者の非ラベルデータのみを使用して設計するための研究分野です。 ディープモデルに対する適応方法の設計は、重要な研究分野です。モデルとトレーニングデータセットの規模の増加が彼らの成功の鍵要素である一方で、この傾向の否定的な結果は、このようなモデルのトレーニングがますます計算コストがかかるということであり、一部の場合では大規模なモデルのトレーニングがアクセスしにくくなり、不必要に炭素フットプリントを増加させることになります。この問題を緩和する方法の一つは、既にトレーニングされたモデルを活用して新しいタスクに対処したり、新しいドメインに一般化するための技術を設計することです。実際、モデルを新しいタスクに適応することは、転移学習の枠組みの下で広く研究されています。 SFDAは、適応が望まれるいくつかの実世界のアプリケーションにおいて、ターゲットドメインからのラベル付きの例が利用できないという問題に直面しています。実際、SFDAは増加している注目を集めています[1, 2, 3, 4]。しかし、野心的な目標に基づいているものの、ほとんどのSFDAの研究は非常に狭い枠組みに基づいており、画像分類タスクでの単純な分布シフトのみを考慮しています。 この傾向から大きく逸脱し、私たちはバイオアコースティクスの分野に注目し、自然発生的な分布シフトが広く存在し、しばしばターゲットドメインのラベル付きデータが不十分で、実践者にとって障害となっていることに着目します。このアプリケーションにおけるSFDAの研究は、既存の方法の一般化可能性を学術界に知らせ、オープンな研究方向を特定するだけでなく、フィールドの実践者に直接的な利益をもたらし、私たちの世紀の最大の課題の一つである生物多様性保全に寄与することができます。 この投稿では、「ソースフリーなドメイン適応の汎用的な手法を探る」と題したICML 2023で発表される論文を紹介します。私たちは、バイオアコースティクスにおける現実的な分布シフトに直面した場合、最先端のSFDAの手法が性能を発揮しない場合や崩壊する場合があることを示します。さらに、既存の手法は、ビジョンベンチマークで観察されるのとは異なる相対的なパフォーマンスを発揮し、驚くべきことに、時には適応なしよりも悪い結果を示す場合もあります。また、私たちはNOTELAという新しいシンプルな手法を提案し、これらのシフトで既存の手法を凌駕しながら、さまざまなビジョンデータセットで強力なパフォーマンスを発揮することを示します。全体として、私たちは、一般に使用されるデータセットと分布シフトのみでSFDAの手法を評価すると、相対的なパフォーマンスと汎化性能について狭視野な視点になると結論付けます。彼らの約束を果たすためには、SFDAの手法はより広範な分布シフトでテストされる必要があり、高い影響を持つアプリケーションに利益をもたらす自然発生的なシフトを考慮することを提唱します。 バイオアコースティクスにおける分布シフト バイオアコースティクスでは、自然発生的な分布シフトが広く存在します。鳥の鳴き声のための最大のラベル付きデータセットはXeno-Canto(XC)であり、世界中の野生鳥のユーザー投稿の録音のコレクションです。XCの録音は「焦点化」されており、自然環境で捕獲された個体を対象としており、識別された鳥の鳴き声が前景にあります。しかし、連続的なモニタリングや追跡の目的では、実践者はしばしば全周マイクを介して得られる「サウンドスケープ」における鳥の識別に関心を持っています。これは非常に困難であることを最近の研究が示しているよく文書化された問題です。この現実的なアプリケーションに着想を得て、私たちはバイオアコースティクスでSFDAを研究し、ソースモデルとしてXCで事前にトレーニングされた鳥種分類器を使用し、さまざまな地理的位置からの「サウンドスケープ」(シエラネバダ(S.ネバダ)、パウダーミル・ネイチャーリザーブ(ペンシルベニア州、米国)、ハワイ、カプレス・ウォーターシェッド(カリフォルニア州、米国)、サプサッカー・ウッズ(ニューヨーク州、米国)、コロンビア)をターゲットドメインとして使用します。 この焦点化から受動化への変化は大きいです。後者の録音では、しばしば信号対雑音比が低く、複数の鳥が同時に鳴いており、雨や風などの多くの鳥や環境の雑音もあります。さらに、異なるサウンドスケープは異なる地理的位置から発生しており、XCの種の非常に小さな部分しか表示されないため、非常に極端なラベルのシフトを引き起こします。さらに、現実のデータでは、ソースドメインとターゲットドメインの両方が顕著なクラスの不均衡を持っているため、いくつかの種は他の種よりも著しく一般的です。さらに、SFDAが通常研究される標準的な単一ラベルの画像分類シナリオとは異なり、各録音内で複数の鳥が識別される可能性があるため、私たちはマルチラベル分類問題も考慮しています。 「フォーカス→サウンドスケープ」のシフトのイラストです。フォーカスされた領域では、録音は通常、シグナル対雑音比(SNR)が高い、単一の鳥の鳴き声が前景に捉えられていますが、背景には他の鳥の鳴き声がある場合もあります。一方、サウンドスケープには全方位マイクロフォンからの録音が含まれ、同時に複数の鳥が鳴き、昆虫や雨、車、飛行機などの環境音も含まれることがあります。 オーディオファイル フォーカス領域 サウンドスケープ領域1 スペクトログラム画像 フォーカス領域(左)からサウンドスケープ領域(右)への分布の変化を、各データセットからの代表的な録音のオーディオファイル(上)とスペクトログラム画像(下)で示したものです。2つ目のオーディオクリップでは、鳥の鳴き声が非常にかすかです。これは、サウンドスケープ録音では鳥の鳴き声が「前景」にないことが一般的な特徴です。クレジット:左:Sue…
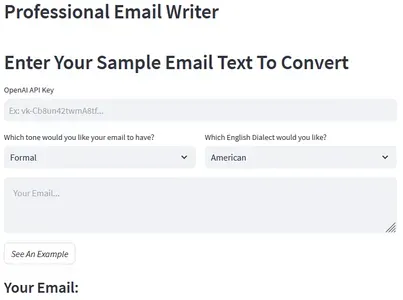
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…

FHEを用いた暗号化された大規模言語モデルに向けて
大規模言語モデル(LLM)は最近、プログラミング、コンテンツ作成、テキスト分析、ウェブ検索、遠隔学習などの多くの分野で生産性を向上させるための信頼性のあるツールとして証明されています。 大規模言語モデルがユーザーのプライバシーに与える影響 LLMの魅力にもかかわらず、これらのモデルによって処理されるユーザークエリに関するプライバシーの懸念が残っています。一方で、LLMの能力を活用することは望ましいですが、他方で、LLMサービスプロバイダーに対して機密情報が漏洩するリスクがあります。医療、金融、法律などの一部の分野では、このプライバシーリスクは問題の原因となります。 この問題への1つの解決策は、オンプレミス展開です。オンプレミス展開では、LLMの所有者がクライアントのマシンにモデルを展開します。これは、LLMの構築に数百万ドル(GPT3の場合は4.6Mドル)かかるため、最適な解決策ではありません。また、オンプレミス展開では、モデルの知的財産(IP)が漏洩するリスクがあります。 Zamaは、ユーザーのプライバシーとモデルのIPの両方を保護できると考えています。このブログでは、Hugging Face transformersライブラリを活用して、モデルの一部を暗号化されたデータ上で実行する方法を紹介します。完全なコードは、このユースケースの例で見つけることができます。 完全同型暗号(FHE)はLLMのプライバシーの課題を解決できます ZamaのLLM展開の課題に対する解決策は、完全同型暗号(FHE)を使用することです。これにより、暗号化されたデータ上で関数の実行が可能となります。モデルの所有者のIPを保護しながら、ユーザーのデータのプライバシーを維持することが可能です。このデモでは、FHEで実装されたLLMモデルが元のモデルの予測の品質を維持していることを示しています。これを行うためには、Hugging Face transformersライブラリのGPT2の実装を適応し、Concrete-Pythonを使用してPython関数をそのFHE相当に変換する必要があります。 図1は、GPT2のアーキテクチャを示しています。これは繰り返し構造を持ち、連続的に適用される複数のマルチヘッドアテンション(MHA)レイヤーから成り立っています。各MHAレイヤーは、モデルの重みを使用して入力をプロジェクションし、アテンションメカニズムを計算し、アテンションの出力を新しいテンソルに再プロジェクションします。 TFHEでは、モデルの重みと活性化は整数で表現されます。非線形関数はプログラマブルブートストラッピング(PBS)演算で実装する必要があります。PBSは、暗号化されたデータ上でのテーブルルックアップ(TLU)演算を実装し、同時に暗号文をリフレッシュして任意の計算を可能にします。一方で、PBSの計算時間は線形演算の計算時間を上回ります。これらの2つの演算を活用することで、FHEでLLMの任意のサブパート、または、全体の計算を表現することができます。 FHEを使用したLLMレイヤーの実装 次に、マルチヘッドアテンション(MHA)ブロックの単一のアテンションヘッドを暗号化する方法を見ていきます。また、このユースケースの例では、完全なMHAブロックの例も見つけることができます。 図2は、基礎となる実装の簡略化された概要を示しています。クライアントは、共有モデルから削除された最初のレイヤーまでの推論をローカルで開始します。ユーザーは中間操作を暗号化してサーバーに送信します。サーバーは一部のアテンションメカニズムを適用し、その結果をクライアントに返します。クライアントはそれらを復号化してローカルの推論を続けることができます。 量子化 まず、暗号化された値上でモデルの推論を実行するために、モデルの重みと活性化を量子化し、整数に変換する必要があります。理想的には、モデルの再トレーニングを必要としない事後トレーニング量子化を使用します。このプロセスでは、FHE互換のアテンションメカニズムを実装し、整数とPBSを使用し、LLMの精度への影響を検証します。 量子化の影響を評価するために、暗号化されたデータ上で1つのLLMヘッドが動作する完全なGPT2モデルを実行します。そして、重みと活性化の量子化ビット数を変化させた場合の精度を評価します。 このグラフは、4ビットの量子化が元の精度の96%を維持していることを示しています。この実験は、約80の文章からなるデータセットを使用して行われます。メトリクスは、元のモデルのロジット予測と量子化されたヘッドモデルを比較して計算されます。 Hugging Face GPT2モデルにFHEを適用する Hugging…
LangChainによるAIの変革:テキストデータのゲームチェンジャー
このPythonライブラリを活用して、AIの使用を向上させる方法を学びましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.