Learn more about Search Results 14 - Page 138

- You may be interested
- GPT-4のプロンプト効果の比較:Dash、Pane...
- 「OpenAIのGPTストアで稼ぐための11のカス...
- 東京理科大学の研究者は、材料科学におけ...
- 「AIに友達になる」
- 「光子チップ ‘レゴのようにはめ込...
- 「TxGNN(テキストジーノーディープラーニ...
- 倫理と社会ニュースレター#4:テキストか...
- コードを解読する LLMs
- Instruction-tuning Stable Diffusion wit...
- 「WavJourney:オーディオストーリーライ...
- XGBoost 最終ガイド(パート2)
- 「GANやVAEを超えたNLPにおける拡散モデル...
- 中国の強力なNvidia AIチップの隠れた市場
- 「これら6つの必須データサイエンススキル...
- Siameseネットワークの導入と実装

古い地図を使って、失われた地域の3Dデジタルモデルに変換する
研究者たちは、新しい機械学習の技術を用いて、古いサンボーン火災保険地図を歴史的な地域の三次元デジタルモデルに変換しました

顔認識によって食料品店から立ち入り禁止
英国における民間企業による顔認識技術の使用は増加しています

コンピューターモデルによる作物の収穫量予測
科学者たちは、アメリカ南東部での綿花、トウモロコシ、ソルガム、大豆の収穫量を予測するコンピューターモデルを構築しました
クエリを劇的に改善できる2つの高度なSQLテクニック
SQLは、すべてのデータプロフェッショナルにとっての基本ですデータアナリスト、データサイエンティスト、データエンジニアであるかどうかに関係なく、クリーンで効率的なコードを書く方法をしっかりと理解している必要があります
GEKKOを使用して、世界を確定的な方法でモデリングする
私たちの世界がますますデジタル化される中で、データ収集は急速に拡大していますこのデータによって、私たちはより正確なモデルを作成し、問題を解決し最適化するための手助けをしてきました...

エンタープライズAIとは何ですか?
エンタープライズAIの紹介 時間は重要であり、自動化が答えです。退屈で単調なタスク、人間によるミス、競争の混乱、そして最終的には曖昧な意思決定の苦闘の中で、エンタープライズAIは企業が機械と協力してより効率的に働くことを可能にしています。さもなければ、Netflixでお気に入りの番組を見つけたり、Amazonで必要なアクセサリーを見つけて購入する方法はどうやって見つけるのでしょうか?自動車のWaymoからマーケティングでの迅速な分析まで、人工知能はすでに私たちに十分な理由を提供しています。しかし、それが組織をどのように助けているのでしょうか?また、組織はそれをどのように使用しているのでしょうか?答えはエンタープライズAIです。 こんにちは! Analytics Vidhya Blogの熱心な読者として、私たちはあなたに素晴らしい機会を提供したいと思います。データサイエンスとAIの愛好家の皆さん、ぜひ私たちと一緒に非常に期待されているDataHack Summit 2023に参加してください。8月2日から5日まで、バンガロールの名門NIMHANSコンベンションセンターで行われます。このイベントは、実践的な学習、貴重な業界の洞察、そして無敵のネットワーキングの機会で満たされた、爆発的なものになるでしょう。これらのトピックに興味があり、これらのコンセプトが現実になることをもっと学びたい場合は、こちらのDataHack Summit 2023の情報をチェックしてください。 エンタープライズAIの定義 エンタープライズAIは、大規模な組織内で人工知能技術と技法を応用して、さまざまな機能を改善することを指します。これらの機能には、データの収集と分析、自動化、顧客サービス、リスク管理などが含まれます。エンタープライズAIは、AIアルゴリズム、機械学習(ML)、自然言語処理(NLP)、コンピュータビジョンなどのツールを使用して、複雑なビジネスの問題を解決し、プロセスを自動化し、大量のデータから洞察を得ることを目指しています。 エンタープライズAIは、サプライチェーン管理、ファイナンス、マーケティング、顧客サービス、人事、サイバーセキュリティなど、さまざまな領域に実装することができます。これにより、組織はデータに基づいた意思決定を行い、効率を向上させ、ワークフローを最適化し、顧客体験を向上させ、市場で競争力を持つことができます。 出典:Publicis Sapient エンタープライズAIの主な特徴 エンタープライズAIは、データ分析から自動化まで、組織のさまざまな側面に貢献します。それは異なる技術や技法、そして方法の産物であり、それは各業界やビジネスによって異なるかもしれません。以下にその仕組みを示します。 エンタープライズアプリケーション向けのAI技術の組み合わせ エンタープライズAI企業は、機械学習、自然言語処理、エッジコンピューティング、ディープラーニング、コンピュータビジョンなどの技術の組み合わせを活用することができます。これらの技術は、予測分析、画像認識などのタスクを通じて、ビジネスを支援するための強力な機能を提供します。Netflixのパーソナライズされた推奨機能は、ディープラーニングなどの技術を使用した、その一例です。 組織のニーズに合わせてカスタマイズされ設計された エンタープライズAIは、さまざまな技術の組み合わせです。組織がシステム内でどのようにアプローチするか、どの技法を採用するかは、ビジネスの要件によるものです。なぜなら、サプライチェーン管理に適した方法が、eコマースの場合に必要なわけではないからです。 たとえば、ヘルスケアのエンタープライズAI企業は、画像解析、患者モニタリングなどの技法を採用して、医療業務の効率を向上させています。エネルギー業界では、予測保守、再生可能エネルギーの統合などの技術と技法を使用して、エネルギーの発電と消費を最適化しています。その活用方法の違いにより、組織は人工知能のさまざまな分野を航海しています。 エンタープライズAIの利点と応用 以下はエンタープライズAIの主な利点です:…

ChatGPTはデータサイエンティストを置き換えるのか?
すべての職業は危険にさらされていますあなたのキャリアをAIに対応させる方法をご紹介します

Google DeepMindは、ChatGPTを超えるアルゴリズムの開発に取り組んでいます
画期的な発表により、GoogleのDeepMind AI研究所のCEOであるデミス・ハサビス氏は、革新的なAIシステムであるGeminiの開発を発表しました。Geminiは、DeepMindが囲碁のゲームでの歴史的な勝利から導き出した技術を活用し、OpenAIのChatGPTを超える予定のアルゴリズムを持つことで、人工知能の分野で重要なマイルストーンを示すものです。この発表は、AIの未来における能力の向上と革新的な進展を約束するものであり、その詳細と将来への潜在的な影響について詳しく探っていきます。 Gemini:AI技術の次の飛躍 DeepMindの画期的なAIシステムであるGeminiは、人工知能の分野でのゲームチェンジャーとして登場しました。AlphaGoの驚異的な成果を基にしたGeminiは、DeepMindの先駆的な技術とGPT-4の言語能力を組み合わせることで、OpenAIのChatGPTの能力を超えるものとなっています。これらの強みの融合により、GeminiはAIの景観を再定義する有望なイノベーションとなっています。 強みの融合:AlphaGoとGPT-4のシナジー AlphaGoの強力な技法をGPT-4モデルに取り入れることで、Geminiは従来の言語モデルの制約を超越します。Geminiの言語能力と問題解決能力のユニークな組み合わせは、AIを革新することを約束します。DeepMindのCEOであるデミス・ハサビス氏は、テキストの理解と生成に優れたシステムが複雑な問題を計画し解決する能力を持つシステムを想像しています。 また読む:DeepMind CEOがAGIの実現が非常に近い可能性を示唆 革新の公開:Geminiの魅力的な特徴 Geminiは、AIの能力の限界を押し広げる多くの魅力的な特徴を導入する予定です。AlphaGoタイプのシステムと大規模な言語モデルの結合により、GeminiはAIの潜在能力の新たな時代をもたらします。DeepMindのエンジニアたちは、Gemini内のいくつかの興味深いイノベーションを示唆しており、公式のローンチに対する期待感をさらに高めています。 強化学習:AlphaGoの成功の基盤 画期的な強化学習技術は、AlphaGoの歴史的な勝利の中核にありました。DeepMindのソフトウェアは、繰り返しの試行とパフォーマンスに対するフィードバックを通じて、複雑な問題をマスターしました。さらに、AlphaGoはツリーサーチと呼ばれる方法を利用して、ボード上の潜在的な手を探索して記憶することができました。この基盤はGeminiの将来の発展の基礎となっています。 また読む:強化学習の包括的なガイド 進行中の旅:Geminiの開発 Geminiはまだ開発段階にありますが、ハサビス氏はその取り組みと投資の大きさを強調しています。DeepMindのチームは、Geminiを完成させるために数か月と膨大な資金(数千万ドルまたは数億ドルにもなる可能性があります)が必要となると推定しています。この取り組みの重要性は、Geminiの潜在的な影響の重要性を示しています。 競争に対抗する:Googleの戦略的な対応 OpenAIのChatGPTが注目を集める中、Googleは迅速に生成型AIを製品に統合し、チャットボットBardを導入し、AIを検索エンジンに組み込みました。GoogleはDeepMindとGoogleの主要なAI研究所であるBrainを統合してGoogle DeepMindを形成することで、ChatGPTによる競争の脅威に対処しようとしています。この戦略的な動きは、GoogleがAIのイノベーションの最前線にとどまることへの取り組みを示しています。 また読む:Chatgpt-4対Google Bard:ヘッドトゥヘッドの比較 DeepMindの旅:買収から驚嘆まで DeepMindの2014年のGoogleによる買収は、AI研究における転換点となりました。この会社の革新的なソフトウェアは強化学習によって駆動し、以前には想像もつかなかった能力を示しました。AlphaGoが2016年に囲碁のチャンピオン李世ドルに対して勝利を収めたことは、AIコミュニティを驚かせ、複雑なゲームにおける人間レベルの熟練度を達成するためのタイムラインに関する先入観に挑戦しました。 また読む:DeepMindのAIマスターゲーマー:2時間で26のゲームを学ぶ トランスフォーマーのトレーニング:大規模言語モデルの基盤…

QLoRAを使用して、Amazon SageMaker StudioノートブックでFalcon-40Bと他のLLMsをインタラクティブにチューニングしてください
大規模な言語モデル(LLM)の微調整により、オープンソースの基礎モデルを調整して、特定のドメインタスクでのパフォーマンスを向上させることができますこの記事では、Amazon SageMakerノートブックを使用して、最新のオープンソースモデルを微調整する利点について説明します私たちは、Hugging Faceのパラメータ効率の良い微調整(PEFT)ライブラリと、bitsandbytesを介した量子化技術を利用して、インタラクティブな微調整をサポートしています
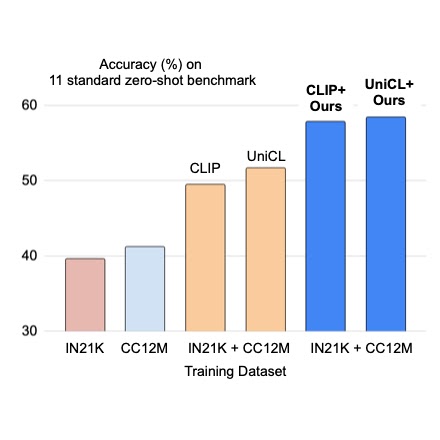
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。 CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。 高レベルのアイデア 分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。 それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 プレフィックス条件付け プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。 トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。 CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。 接頭辞条件付けのイラスト。 実験結果…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.