Learn more about Search Results データサイエンス - Page 137

- You may be interested
- Learning to build—Towards AI コミュニテ...
- グーグルサーチは、Googleサーチで文法チ...
- GoogleシートのAI搭載ソリューション「ス...
- なぜ無料のランチがあるのか
- Reka AIは、視覚センサと聴覚センサを備え...
- ハイパーヒューマンに会ってください:潜...
- ベイジアンマーケティングミックスモデル...
- 『Google AI Researchが効率的な連成振動...
- Meet ChatGLM2-6B:オープンソースのバイ...
- 「2023年のトップ18のAIベースのウェブサ...
- 意味レイヤー:AIパワードデータエクスペ...
- 「2023年の市場で利用可能な15の最高のETL...
- 光を乗りこなす:Sunswift RacingがWorld ...
- PyTorch完全にシャーディングされたデータ...
- 探索的なノートブックの使い方[ベストプラ...

データアナリストの仕事内容はどのように見えますか?
はじめに グローバルなデータ分析市場は、2026年までに年率28.9%で132,903百万ドルに達すると予想されています。データは世界中の企業の強力な支援力となっていますが、データアナリストとしてのキャリアをスタートするのは十分に正当なことです。データアナリストの仕事の説明には、データの収集、クリーニング、調整、翻訳に熟練が求められます。この分野で前進する計画がある場合は、データアナリストの役割と責任、および求職者が職に就くために期待される資格について説明します。 データアナリストとは何ですか? データアナリストは、大量のデータセットを収集、解釈、分析して有益な洞察とトレンドを明らかにします。彼らは統計的および分析的技術を使用してデータを調べ、パターンを特定し、意味のある結論を導き出します。データアナリストは、ビジネスや組織が情報を得て効果的な戦略を開発するのを支援することが重要です。彼らは、売上高、顧客デモグラフィック、ウェブサイトのトラフィック、ソーシャルメディアのエンゲージメントなど、多様なデータソースであるスプレッドシート、統計ソフトウェア、プログラミング言語などのツールを使用します。データ分析、可視化、レポート作成の専門知識を持つことで、データアナリストはビジネスのパフォーマンスを向上させ、データに基づく意思決定を促進します。 データアナリストの主な責任 重要なデータアナリストの責任には、アクション可能な洞察を生成し、意思決定プロセスを促進するためにデータを収集、分析、解釈することが含まれます。現在、データアナリストの仕事の説明の職務は、業界、会社、役割などの特定に基づいて異なる場合があります。 ここでは、異なる文脈で役立つ5つのデータアナリストの役割と責任を紹介します。 1. データの収集と分析 データアナリストの役割には、データベース、スプレッドシート、APIなどからデータを収集することが含まれます。アナリストは、データの正確性と一貫性を確保することが期待されています。さらに、データを分析しやすくするために変換することも含まれる場合があります。 2. データのクリーニングと前処理 分析を行う前に、データアナリストはしばしば生データをクリーニングして前処理する必要があります。これにより、分析に適したデータであることが確認されます。欠落しているデータの処理、データの検証の実行、外れ値の処理など、データクリーニングに使用される技術の熟練度を確保することも重要です。 3. データの探索と可視化 データアナリストの仕事の説明には、統計的技術とデータ可視化ツールの熟練度が必須とされることがよくあります。データの探索と可視化を行うことで、データ内のパターンを特定し、意味のある洞察を導き出すことが不可欠です。したがって、データアナリストは、Excel、SQL、Python、またはRなどのプログラミング言語などのツールを使いこなす必要があります。 4. パターン、トレンド、および洞察の特定 データアナリストの仕事の説明には、数値を精査し、パターン、トレンド、相関関係を探すというタスクが、データアナリストの主な責任として強調されています。統計的手法や分析技術を用いて、専門家は価値のある洞察を抽出するための解釈技術に精通している必要があります。 5. レポートとプレゼンテーションの作成 データアナリストの役割は、データドリブンの洞察や推奨事項を提供することで問題解決を支援することです。データアナリストは、意思決定者やステークホルダーと緊密に協力して、要件を理解し、データ分析に基づいてよりよい意思決定を行うのを支援します。彼らは、実行可能な推奨事項と洞察を提供して、ビジネス戦略を推進し、パフォーマンスを向上させます。 データアナリストのスキル 企業固有のデータアナリストの仕事の説明に基づいて、必要なスキルと資格のリストを作成することが理想的ですが、データアナリストとして競争に勝つためには、技術的な専門知識、分析思考力、強力なコミュニケーションスキルを組み合わせる必要があります。…
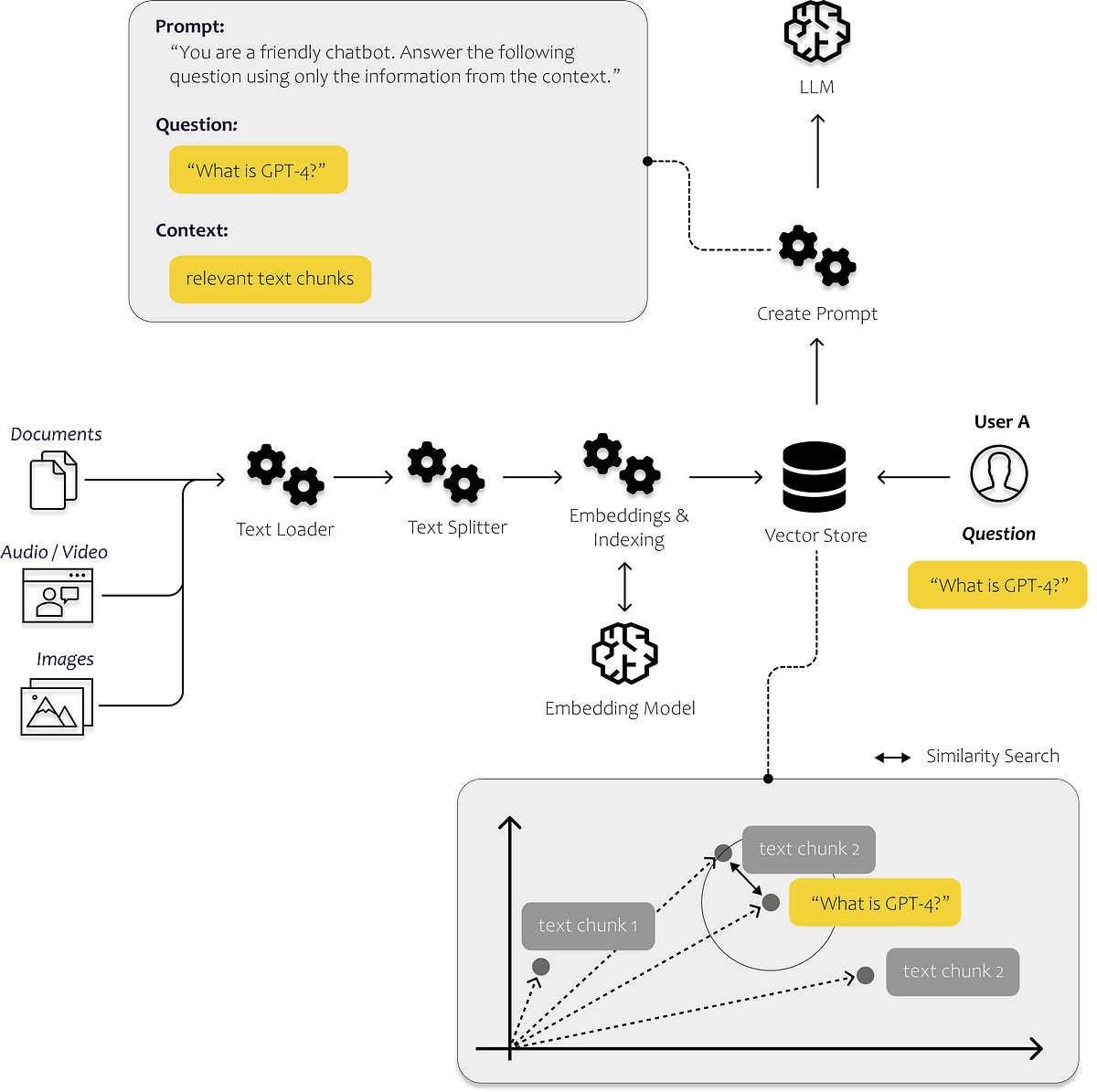
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

機械学習によるストレス検出の洞察を開示
イントロダクション ストレスとは、身体や心が要求や挑戦的な状況に対して自然に反応することです。外部の圧力や内部の思考や感情に対する身体の反応です。仕事に関するプレッシャーや財政的な困難、人間関係の問題、健康上の問題、または重要な人生の出来事など、様々な要因によってストレスが引き起こされることがあります。データサイエンスと機械学習によるストレス検知インサイトは、個人や集団のストレスレベルを予測することを目的としています。生理学的な測定、行動データ、環境要因などの様々なデータソースを分析することで、予測モデルはストレスに関連するパターンやリスク要因を特定することができます。 この予防的アプローチにより、タイムリーな介入と適切なサポートが可能になります。ストレス予測は、健康管理において早期発見と個別化介入、職場環境の最適化に役立ちます。また、公衆衛生プログラムや政策決定にも貢献します。ストレスを予測する能力により、これらのモデルは個人やコミュニティの健康増進と回復力の向上に貢献する貴重な情報を提供します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 機械学習を用いたストレス検知の概要 機械学習を用いたストレス検知は、データの収集、クリーニング、前処理を含みます。特徴量エンジニアリング技術を適用して、ストレスに関連するパターンを捉えることができる意味のある情報を抽出したり、新しい特徴を作成したりすることができます。これには、統計的な測定、周波数領域解析、または時間系列解析などが含まれ、ストレスの生理学的または行動的指標を捉えることができます。関連する特徴量を抽出またはエンジニアリングすることで、パフォーマンスを向上させることができます。 研究者は、ロジスティック回帰、SVM、決定木、ランダムフォレスト、またはニューラルネットワークなどの機械学習モデルを、ストレスレベルを分類するためのラベル付きデータを使用してトレーニングします。彼らは、正解率、適合率、再現率、F1スコアなどの指標を使用してモデルのパフォーマンスを評価します。トレーニングされたモデルを実世界のアプリケーションに統合することで、リアルタイムのストレス監視が可能になります。継続的なモニタリング、更新、およびユーザーフィードバックは、精度向上に重要です。 ストレスに関連する個人情報の扱いには、倫理的な問題やプライバシーの懸念を考慮することが重要です。個人のプライバシーや権利を保護するために、適切なインフォームドコンセント、データの匿名化、セキュアなデータストレージ手順に従う必要があります。倫理的な考慮事項、プライバシー、およびデータセキュリティは、全体のプロセスにおいて重要です。機械学習に基づくストレス検知は、早期介入、個別化ストレス管理、および健康増進に役立ちます。 データの説明 「ストレス」データセットには、ストレスレベルに関する情報が含まれています。データセットの特定の構造や列を持たない場合でも、パーセンタイルのためのデータ説明の一般的な概要を提供できます。 データセットには、年齢、血圧、心拍数、またはスケールで測定されたストレスレベルなど、数量的な測定を表す数値変数が含まれる場合があります。また、性別、職業カテゴリ、または異なるカテゴリ(低、VoAGI、高)に分類されたストレスレベルなど、定性的な特徴を表すカテゴリカル変数も含まれる場合があります。 # Array import numpy as np # Dataframe import pandas as pd #Visualization…

AIの仕事を見つけるための最高のプラットフォーム
あなたのキャリアの目標、好みの仕事スタイル、およびAIの専門分野に依存するAIの仕事に最適なプラットフォームについてもっと学びましょう
PythonからJuliaへ:基本的なデータ操作とEDA
統計計算の領域でエマージングなプログラミング言語として、Julia は近年ますます注目を集めています他の言語に優る2つの特徴があります...

アテンションメカニズムを利用した時系列予測
はじめに 時系列予測は、金融、気象予測、株式市場分析、リソース計画など、さまざまな分野で重要な役割を果たしています。正確な予測は、企業が情報に基づいた決定を行い、プロセスを最適化し、競争上の優位性を得るのに役立ちます。近年、注意機構が、時系列予測モデルの性能を向上させるための強力なツールとして登場しています。本記事では、注意の概念と、時系列予測の精度を向上させるために注意を利用する方法について探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 時系列予測の理解 注意機構について詳しく説明する前に、まず時系列予測の基礎を簡単に見直してみましょう。時系列は、日々の温度計測値、株価、月次の売上高など、時間の経過とともに収集されたデータポイントの系列から構成されます。時系列予測の目的は、過去の観測値に基づいて将来の値を予測することです。 従来の時系列予測手法、例えば自己回帰和分移動平均(ARIMA)や指数平滑法は、統計的手法や基礎となるデータに関する仮定に依存しています。研究者たちはこれらの手法を広く利用し、合理的な結果を得ていますが、データ内の複雑なパターンや依存関係を捉えることに課題を抱えることがあります。 注意機構とは何か? 人間の認知プロセスに着想を得た注意機構は、深層学習の分野で大きな注目を集めています。機械翻訳の文脈で初めて紹介された後、注意機構は自然言語処理、画像キャプション、そして最近では時系列予測など、様々な分野で広く採用されています。 注意機構の主要なアイデアは、モデルが予測を行うために最も関連性の高い入力シーケンスの特定の部分に焦点を合わせることを可能にすることです。注意は、すべての入力要素を同等に扱うのではなく、関連性に応じて異なる重みや重要度を割り当てることができるようにします。 注意の可視化 注意の仕組みをよりよく理解するために、例を可視化してみましょう。数年にわたって日々の株価を含む時系列データセットを考えます。次の日の株価を予測したいとします。注意機構を適用することで、モデルは、将来の価格に影響を与える可能性が高い、過去の価格の特定のパターンやトレンドに焦点を合わせることができます。 提供された可視化では、各時間ステップが小さな正方形として描かれ、その特定の時間ステップに割り当てられた注意重みが正方形のサイズで示されています。注意機構は、将来の価格を予測するために、関連性が高いと判断された最近の価格により高い重みを割り当てることができることがわかります。 注意に基づく時系列予測モデル 注意機構の理解ができたところで、時系列予測モデルにどのように統合できるかを探ってみましょう。人気のあるアプローチの1つは、注意を再帰型ニューラルネットワーク(RNN)と組み合わせることで、シーケンスモデリングに広く使用されている方法です。 エンコーダ・デコーダアーキテクチャ エンコーダ・デコーダアーキテクチャは、エンコーダとデコーダの2つの主要なコンポーネントから構成されています。過去の入力シーケンスをX = [X1、X2、…、XT]、Xiが時間ステップiの入力を表すようにします。 エンコーダ エンコーダは、入力シーケンスXを処理し、基礎となるパターンと依存関係を捉えます。このアーキテクチャでは、エンコーダは通常、LSTM(長短期記憶)レイヤを使用して実装されます。入力シーケンスXを取り、隠れ状態のシーケンスH = [H1、H2、…、HT]を生成します。各隠れ状態Hiは、時間ステップiの入力のエンコード表現を表します。 H、_= LSTM(X)…
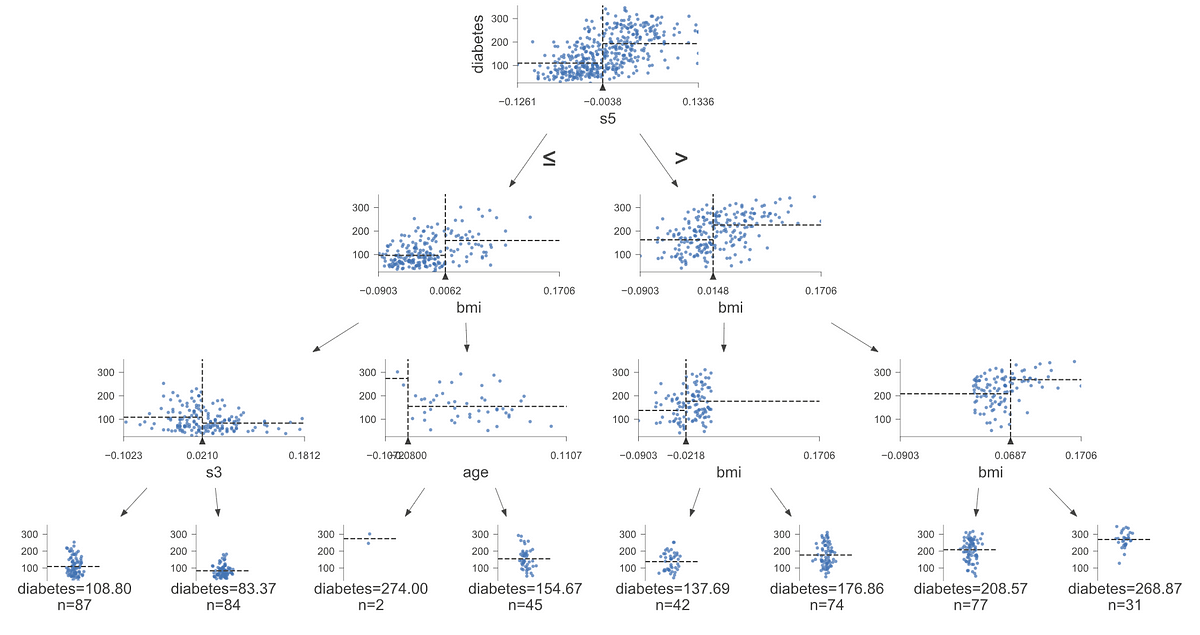
dtreevizを使用して、信じられないほどの意思決定木の視覚化を作成する
決定木モデルを視覚化できることは、モデルの説明可能性にとって重要であり、ステークホルダーがこれらのモデルに信頼を持つのに役立つことがあります
超幾何分布の理解
二項分布は、データサイエンスの内外でよく知られた分布ですしかし、あなたはその人気のないいところのいとこである超幾何分布について聞いたことがありますか?もしそうでない場合、この投稿をご覧ください...

予測の作成:Pythonにおける線形回帰の初心者ガイド
最も人気のある機械学習アルゴリズムである線形回帰について、その数学的直感とPythonによる実装をすべて学びましょう

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.