Learn more about Search Results GitHub - Page 134

- You may be interested
- 「ロボットのセンシングと移動のためのア...
- 「Googleが最新のVertex AI検索を発表:医...
- 「次のステップは責任あるAIですどのよう...
- 「OpenAIがDall E-3を発売!次世代AIイメ...
- OpenAIはAIチップ製造リーグへの参加を検...
- 「受賞者たちは創造的AIのハイプを超えて...
- 「ウェブポータル開発を加速させる8つの戦...
- 「AIがデジタルツインを2024年にどのよう...
- フルスタック7ステップMLOpsフレームワーク
- 人工汎用知能(AGI)の包括的な紹介
- 「OpenAI、DALL·E 3を発表:テキストから...
- 「言語モデルにアルゴリズム的な推論を教...
- 探索的データ分析:YouTubeチャンネルにつ...
- Gmailを効率的なメールソリューションに変...
- AUCとHarrellのCに対する直感

予測の作成:Pythonにおける線形回帰の初心者ガイド
最も人気のある機械学習アルゴリズムである線形回帰について、その数学的直感とPythonによる実装をすべて学びましょう

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…
AgentGPT ブラウザ内の自律型AIエージェント
あなたのAIエージェントに名前と目標を与え、割り当てられた目的を達成するのを見てください

AWSが開発した目的に特化したアクセラレータを使用することで、機械学習ワークロードのエネルギー消費を最大90%削減できます
従来、機械学習(ML)エンジニアは、モデルの学習と展開コストとパフォーマンスのバランスを取ることに焦点を当ててきました最近では、持続可能性(エネルギー効率)が顧客にとって追加の目標となっていますこれは重要なことであり、MLモデルのトレーニングを行い、トレーニングされたモデルを使用して予測(推論)を行うことは、非常にエネルギーを消費するタスクであるためです加えて、さらに...

20以上のスタートアップに最適なAIツール(2023年)
AIによって、職場の創造性、分析、意思決定が革命化されています。現在、人工知能の能力は、企業が拡大を急ぎ、内部プロセスをより良く管理するための絶大な機会を提供しています。人工知能の応用は、自動化や予測分析からパーソナライゼーションやコンテンツ開発まで多岐にわたります。以下は、若いビジネスに有利に働く最高の人工知能ツールの概要です。 AdCreative.ai AdCreative.aiは究極の人工知能ソリューションで、広告やソーシャルメディアのゲームを強化します。創造的な作業に数時間費やす必要がなく、数秒で生成される高変換率の広告やソーシャルメディア投稿に別れを告げましょう。今すぐAdCreative.aiで成功を最大化し、努力を最小限に抑えましょう。 DALL·E 2 OpenAIのDALLE 2は、単一のテキスト入力から独自かつ創造的なビジュアルを作成する最先端のAIアートジェネレーターです。AIモデルは、画像とテキストの説明の巨大なデータセットでトレーニングされており、書かれたリクエストに応じて詳細で視覚的に魅力的な画像を生成します。スタートアップはDALLE 2を使用して広告やウェブサイト、ソーシャルメディアページの画像を作成し、手動でグラフィックを作成する必要がなく、テキストから異なる画像を生成するこの方法で時間とお金を節約することができます。 Otter AI Otter.AIは人工知能を使用して、共有可能で検索可能、アクセス可能、安全なミーティングノートのリアルタイムトランスクリプションをユーザーに提供します。音声を記録し、ノートを書き、自動的にスライドをキャプチャし、要約を生成するミーティングアシスタントを手に入れましょう。 Notion Notionは、最新のAI技術を活用してユーザー数を増やすことを目指しています。最新機能であるNotion AIは、ノートの要約、ミーティングでのアクションアイテムの識別、テキストの作成と修正などのタスクをサポートする堅牢な生成AIツールです。 Notion AIは、煩雑なタスクを自動化し、ユーザーに提案やテンプレートを提供することで、ワークフローを合理化し、ユーザーエクスペリエンスを最適化することで、最終的に簡単で改善された体験を提供します。 Motion Motionは、ミーティング、タスク、プロジェクトを考慮した日々のスケジュールを作成するためにAIを使用する賢いツールです。計画の手間を省いて、より生産的な人生に別れを告げましょう。 Jasper 先進的なAIコンテンツジェネレーターであるJasperは、その優れたコンテンツ製作機能でクリエイティブ業界で話題となっています。Jasperは、人間のライティングパターンを認識することから効率性が生まれ、グループが興味深いコンテンツを迅速に製作することができます。ランディングページや製品説明のコピーをより良く書くためにJasperをAIパワードのコンパニオンとして使用し、より魅力的で興味深いソーシャルメディア投稿を作成することができます。 Lavender リアルタイムAIメールコーチであるLavenderは、セールス業界でゲームチェンジャーとして広く認知されており、数千人のSDRs、AEs、およびマネージャーがメールのレスポンス率と生産性を向上させています。競争力のあるセールス環境では、効果的なコミュニケーションスキルが成功に不可欠です。スタートアップはLavenderを使用して、電子メールのレスポンス率を向上させ、見込み客とのより深い関係を構築することができます。 Speak AI…

GPTエンジニア:1つのプロンプトで強力なアプリを構築する
GPTエンジニアは、1つのプロンプトで完全なコーディングプロジェクトを構築できるAIエージェントです

ビジネスにおける機械学習オペレーションの構築
私のキャリアで気づいたことは、成功したAI戦略の鍵は機械学習モデルを本番環境に展開し、それによって商業的な可能性をスケールで解放する能力にあるということですしかし…
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
人間は常に周囲と相互作用しています。空間を移動したり、物に触れたり、椅子に座ったり、ベッドで寝たりします。これらの相互作用は、シーンの設定やオブジェクトの位置を詳細に示します。マイムは、そのような関係性の理解を利用して、身体の動きだけで豊かで想像力豊かな3D環境を作り出すパフォーマーです。彼らはコンピュータに人間の動作を模倣させて適切な3Dシーンを作ることができるでしょうか?建築、ゲーム、バーチャルリアリティ、合成データの合成など、多くの分野がこの技術に恩恵を受ける可能性があります。たとえば、AMASSなどの3D人間の動きの大規模なデータセットが存在しますが、これらのデータセットには収集された3D設定の詳細がほとんど含まれていません。 AMASSを使用して、すべての動きに対して信憑性の高い3Dシーンを作成できるでしょうか?そうであれば、AMASSを使用してリアルな人間-シーンの相互作用を考慮したトレーニングデータを作成できます。彼らは、MIME(Mining Interaction and Movement to infer 3D Environments)と呼ばれる新しい技術を開発しました。これは、3D人間の動きに基づいて信憑性の高い内部3Dシーンを作成して、このような問いに対応します。それを可能にするのは何でしょうか?基本的な仮定は次のとおりです。(1)空間を移動する人間の動きは、物の欠如を示し、実質的に家具のない画像領域を定義します。また、これにより、シーンに接触する場合の3Dオブジェクトの種類や場所が制限されます。たとえば、座っている人は椅子、ソファ、ベッドなどに座っている必要があります。 図1:人間の動きから3Dシーンを推定します。3D人間の動き(左)から推定された、動きが起こったリアルな3D設定を再現します。彼らの生成モデルは、人間-シーンの相互作用を考慮した、複数のリアリスティックなシナリオ(右)を生成できます。 ドイツのマックスプランク知能システム研究所とAdobeの研究者たちは、これらの直感を具体的な形で示すために、MIMEと呼ばれるトランスフォーマーベースの自己回帰3Dシーン生成技術を作成しました。空のフロアプランと人間の動きシーケンスが与えられると、MIMEは人間と接触する家具を予測します。さらに、人間と接触しないが他のオブジェクトにフィットし、人間の動作によって引き起こされる自由空間の制約に従う信憑性の高いアイテムを予測します。彼らは、人間の動きを接触と非接触のスニペットに分割して、3Dシーン作成を人間の動きに条件付けます。POSAを使用して接触可能なポーズを推定します。非接触姿勢は、足の頂点を地面に投影して、部屋の自由空間を確立し、2Dフロアマップとして記録します。 POSAによって予測された接触頂点は、接触ポーズと関連する3D人体モデルを反映した3D境界ボックスを作成します。接触と自由空間の基準を満たすオブジェクトは、トランスフォーマーへの入力として自己回帰的に期待されます。図1を参照してください。彼らは、3D-FRONTという大規模な合成シーンデータセットを拡張して、MIMEをトレーニングするための新しいデータセットである3D-FRONT HUMANを作成しました。彼らは、RenderPeopleスキャンからの静止接触ポーズと、AMASSからのモーションシーケンスを使用して、3Dシナリオに人を自動的に追加します(一連の歩行モーションと立っている人を含む非接触人と、座って、触れて、横たわっている人を含む接触人)。 MIMEは、3Dバウンディングボックスとして表される入力動作のリアルな3Dシーンレイアウトを推論時に作成します。彼らは、この配置に基づいて3D-FUTUREコレクションから3Dモデルを選択し、人間の位置とシーンの間の幾何学的制約に基づいて3D配置を微調整します。彼らの手法は、ATISSのような純粋な3Dシーン作成システムとは異なり、人間の接触と動きをサポートする3Dセットを作成し、自由空間に説得力のあるオブジェクトを配置することができます。Pose2Roomという最近のポーズ条件付け生成モデルとは異なり、個々のオブジェクトではなく完全なシーンを予測することができます。彼らは、PROX-Dのように記録された本物のモーションシーケンスに対して調整なしで彼らの手法が機能することを示しました。 まとめると、彼らが提供したものは以下の通りです: • 人と接触するものを自動的に生成し、運動定義された空きスペースを占有しないように自己回帰的に作成する、3Dルームシーンの全く新しい運動条件付き生成モデル。 • RenderPeopleの静止接触/立ち姿勢からの3Dモーションデータを用いて、人と自由空間にいる人々が相互作用する3Dシーンデータセットが、3D FRONTを埋めるように作成されました。 コードはGitHubで入手可能であり、ビデオデモとアプローチのビデオ解説も提供されています。
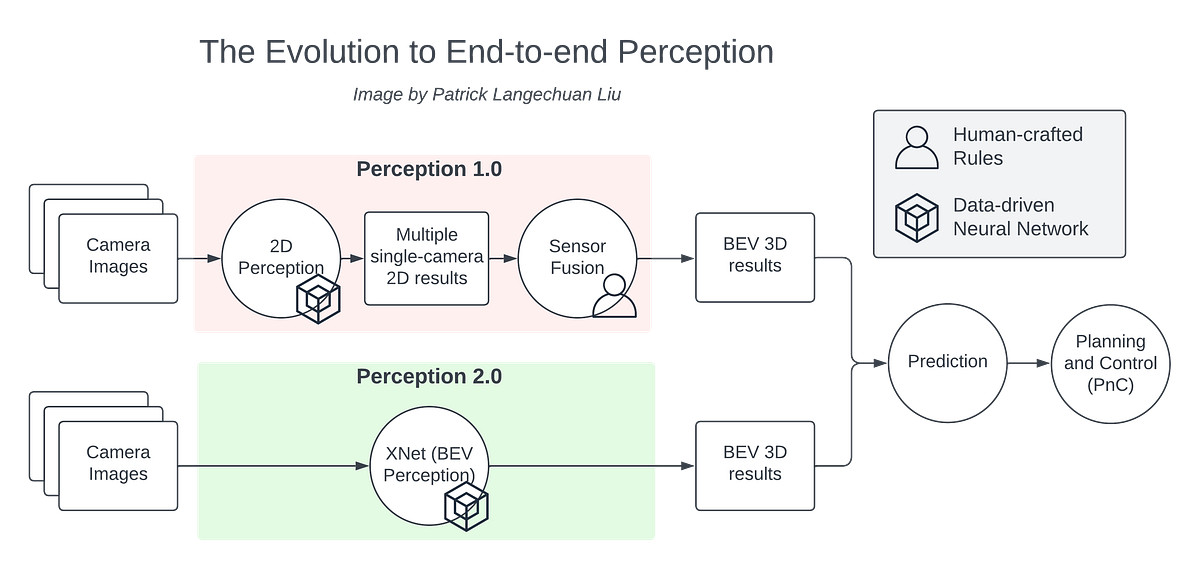
量産自動運転におけるBEVパーセプション
BEVの認識技術は、ここ数年で非常に進歩しました自動運転車の周りの環境を直接認識することができますBEVの認識技術はエンド・トゥ・エンドと考えることができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.