Learn more about Search Results 場所 - Page 131

- You may be interested
- KNNクラシファイアにおける次元の呪い
- デルタレイク – パーティショニング...
- 元アップル社員が生成型AIをデスクトップ...
- データサイエンティストのための時系列分...
- 「AIがデジタルツインを2024年にどのよう...
- デルタテーブルの削除ベクトル:Databrick...
- チャーン予測とチャーンアップリフトを超えて
- 教師なしの深層学習により、単一の下側頭...
- 「学生として、私がChatGPTを使って生産性...
- オープンなMLモデルを使用してWebアプリジ...
- AIによるテキストメッセージングの変革:...
- 「無料ハーバード講座:PythonでのAI入門」
- Pythonを使用したデータのスケーリング
- 「Pythonを学ぶための5つの無料大学講座」
- 『EMQX MQTT Brokerクラスタリングの基礎...

AIをトレーニングするために雇われた人々が、AIに仕事を外注している…
これは、既にエラーが多いモデルにさらにエラーを導入する可能性のある実践です

ジョン・イサザ弁護士、FAI氏によるAIとChatGPTの法的な土壌を航行する方法
私たちは、Rimon LawのパートナーであるJohn Isaza, Esq., FAIに感謝しています彼は、法的な景観の変化、プライバシー保護とイノベーションの微妙なバランス、そしてAIツールを統合する際に生じる独特の法的な意義など、多岐にわたる側面で自身の物語と貴重な洞察を共有してくれましたJohnは、AIに関連する課題や考慮事項について貴重な観点を提供しています...John Isaza, Esq., FAI がAIとChatGPTの法的景観を航海するための記事を読む»

AWSにおけるマルチモデルエンドポイントのためのCI/CD
生産用機械学習ソリューションの再トレーニングと展開を自動化することは、モデルが共変量シフトを考慮しながら、誤りや不要な人間の介入を制限するための重要なステップです
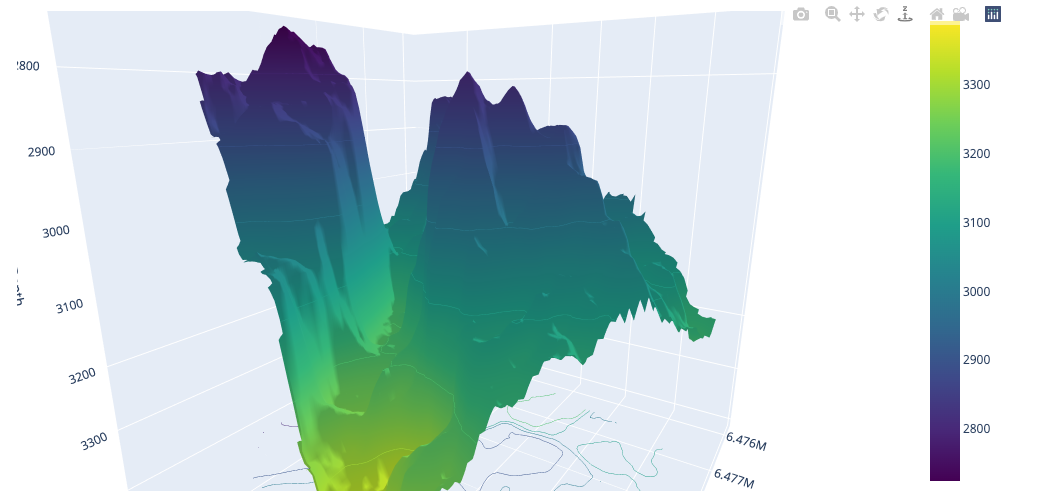
Plotlyの3Dサーフェスプロットを使用して、地質表面を視覚化する
地球科学の分野においては、地下に存在する地質層の完全な理解が不可欠です層の正確な位置と形状を知ることで、...

GPT-5から何を期待できるのか?
私たちが皆待ち望んでいた瞬間-GPT-5とその前身であるGPT-4の印象的な能力

ChatGPTのデジタル商品をオンラインで販売するプロンプト
ChatGPTは、オンラインでデジタル製品を販売して収益を上げたい人にとって、ありがたい存在です
言語学習モデルにおけるOpenAIの関数呼び出しの力:包括的なガイド
OpenAIの関数呼び出し機能を使用したデータパイプラインの変換:PostgreSQLとFastAPIを使用した電子メール送信ワークフローの実装

AIは自己を食べるのか?このAI論文では、モデルの崩壊と呼ばれる現象が紹介されており、モデルが時間の経過とともに起こり得ないイベントを忘れ始める退行的な学習プロセスを指します
安定した拡散により、言葉だけで画像を作ることができます。GPT-2、GPT-3(.5)、およびGPT-4は、多くの言語の課題で驚異的なパフォーマンスを発揮しました。この種の言語モデルについての一般の知識は、ChatGPTを通じて最初に公開されました。大規模言語モデル(LLM)は恒久的なものとして確立され、オンラインテキストおよび画像エコシステム全体を大幅に変えることが期待されています。大量のWebスクレイピングデータからのトレーニングは、十分な考慮が与えられた場合にのみ維持できます。実際に、LLMが生成したコンテンツをインターネットから収集したデータに含めることで、システムとの真の人間の相互作用に関する取得されたデータの価値は高まるでしょう。 英国とカナダの研究者は、モデルの崩壊が、あるモデルが他のモデルによって生成されたデータから学習すると発生することを発見しました。この退化的なプロセスにより、モデルは時間の経過とともに真の基盤となるデータ分布の追跡を失い、変化がない場合でも、誤って解釈されるようになります。彼らは、ガウス混合モデル、変分オートエンコーダー、および大規模言語モデルの文脈でモデルの失敗の事例を提供することによって、この現象を説明しています。彼らは、獲得された行動が世代を超えて推定値に収束し、この真の分布に関する知識の喪失が尾の消失から始まる方法を示し、この結果が機能推定エラーがないほぼ最適な状況でも不可避であることを示しています。 研究者たちは、モデルの崩壊の大きな影響について述べ、基盤となる分布の尾の場所を特定するために生データにアクセスすることがどれだけ重要かを指摘しています。したがって、LLMとの人間の相互作用に関するデータがインターネット上で大規模に投稿される場合、データ収集を汚染し、トレーニングに使用することがますます役立つようになるでしょう。 モデル崩壊とは何ですか? 学習済みの生成モデルの一世代が次の世代に崩壊するとき、後者は汚染されたデータでトレーニングされるため、世界を誤解することになり、破綻的な忘却過程とは対照的に、このアプローチでは、時間を通じて多くのモデルを考慮することを考慮しています。モデルは以前に学習したデータを忘れないで、彼らのアイデアを強化することで彼らが実際に現実であると認識するものを誤って解釈するようになります。これは、様々な世代を通じて組み合わされた二つの異なる誤り源によって起こるため、過去のモデルから生じるものであり、この特定の誤りメカニズムが最初の世代を超えて生き残る必要があります。 モデル崩壊の原因 モデルの失敗の基本的および二次的な原因は以下の通りです。 最も一般的なエラーは統計的近似の結果であり、有限のサンプルがあると起こりますが、サンプルサイズが無限に近づくにつれて減少します。 関数近似器が十分に表現力がない(または元の分布を超えて過剰に表現力がある場合がある)ために引き起こされる二次的なエラーを機能近似エラーと呼びます。 これらの要因は、モデル崩壊の可能性を悪化または緩和することができます。より良い近似力は、統計的ノイズを増幅または減衰させることができるため、基盤となる分布のより良い近似をもたらす一方で、それを増幅することもできます。 モデル崩壊は、再帰的にトレーニングされた生成モデルすべてで発生すると言われており、すべてのモデル世代に影響を与えます。彼らは実際のデータに適用されると崩壊する基本的な数学モデルを作成することができますが、興味のある値の解析方程式を導くために使用することができます。彼らの目標は、様々なエラータイプの影響を元の分布の最終近似に置く数値を示すことです。 研究者たちは、別の生成モデルからのデータでトレーニングすることによってモデル崩壊が引き起こされることがわかり、分布のシフトが生じるため、モデルがトレーニング問題を誤って解釈するようになると示しています。長期的な学習には、元のデータソースにアクセスし、LLMsによって生成された他のデータを時間をかけて利用する必要があります。LLMsの開発と展開に参加するすべての当事者が、証明問題を解決するために必要なデータを伝達し、共有するためにコミュニティ全体で調整することが1つのアプローチです。技術が広く採用される前にインターネットからクロールされたデータまたは人間によって提供されたデータにアクセスすることができるため、LLMsの後続バージョンをトレーニングすることがますます簡単になる可能性があります。 以下をチェックしてください: 論文と参考記事。 24k+ ML SubReddit、Discordチャンネル、および電子メールニュースレターに参加することを忘れないでください。そこでは、最新のAI研究ニュース、クールなAIプロジェクトなどを共有しています。上記の記事に関する質問がある場合や、何か見落としがあった場合は、お気軽に[email protected]までメールでお問い合わせください。

AIの創造的かつ変革的な可能性
ジェームズ・マニカ氏は、AIと創造性についてカンヌライオンズフェスティバルで講演しました彼の発言の抜粋を読んでください

AWS CDK を使用して Amazon SageMaker Studio ライフサイクル構成をデプロイします
Amazon SageMaker Studioは、機械学習(ML)のための最初の完全に統合された開発環境(IDE)ですStudioは、データを準備し、モデルを構築、トレーニング、展開するために必要なすべてのML開発ステップを実行できる単一のWebベースのビジュアルインターフェースを提供しますライフサイクル設定は、Studioライフサイクルイベントによってトリガーされるシェルスクリプトです [...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.