Learn more about Search Results huggingface.co - Page 12

- You may be interested
- AIシステムは、構造設計のターゲットを満...
- 「Neosyncをご紹介します:開発環境やテス...
- AI幻覚とは何ですか?AIチャットボットで...
- 大規模展開向けのモデル量子化に深く掘り...
- ChatGPTを始めるための初心者向け7つのプ...
- 「サポートベクトルマシンの優しい入門」
- 「テスラ、『不十分な』自動運転安全制御...
- オンライン収益を新たな高みに引き上げま...
- 「AIアラインメントの二つの側面」
- 「機械学習と人工知能を利用した在庫管理...
- 細菌注入システムは、マウスおよび人間細...
- グーグルの研究者たちは、MEMORY-VQという...
- 「AmazonがAIによるレビューの要約を導入」
- 「ChatGPTをより優れたソフトウェア開発者...
- 「MITのインドの学生が声を必要としない会...

「TransformersとTokenizersを使用して、ゼロから新しい言語モデルを訓練する方法」
ここ数か月間で、私たちはtransformersとtokenizersライブラリにいくつかの改良を加え、新しい言語モデルをゼロからトレーニングすることをこれまで以上に簡単にすることを目指しました。 この記事では、”小さな”モデル(84 Mパラメータ = 6層、768隠れユニット、12アテンションヘッド)を「エスペラント」でトレーニングする方法をデモンストレーションします。その後、モデルを品詞タグ付けの下流タスクでファインチューニングします。 エスペラントは学習しやすいことを目標とした人工言語です。このデモンストレーションのために選んだ理由は以下のとおりです: 比較的リソースが少ない言語です(約200万人が話すにもかかわらず)、このデモンストレーションはもう1つの英語モデルのトレーニングよりも面白くなります 😁 文法が非常に規則的です(例:一般的な名詞は-oで終わり、すべての形容詞は-aで終わります)。そのため、小さなデータセットでも興味深い言語的結果が得られるはずです。 最後に、この言語の基盤となる目標は人々をより近づけることです(世界平和と国際理解を促進すること)。これはNLPコミュニティの目標と一致していると言えるでしょう 💚 注:この記事を理解するためにはエスペラントを理解する必要はありませんが、学びたい場合はDuolingoには280,000人のアクティブな学習者がいる素敵なコースがあります。 私たちのモデルの名前は…待ってください…EsperBERTo 😂 1. データセットを見つける まず、エスペラントのテキストコーパスを見つけましょう。ここでは、INRIAのOSCARコーパスのエスペラント部分を使用します。OSCARは、WebのCommon Crawlダンプの言語分類とフィルタリングによって得られた巨大な多言語コーパスです。 データセットのエスペラント部分はわずか299Mですので、Leipzig Corpora Collectionのエスペラントサブコーパスと連結します。このサブコーパスには、ニュース、文学、ウィキペディアなど様々なソースのテキストが含まれています。 最終的なトレーニングコーパスのサイズは3 GBですが、モデルに先行学習するためのデータが多ければ多いほど、より良い結果が得られます。 2.…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…
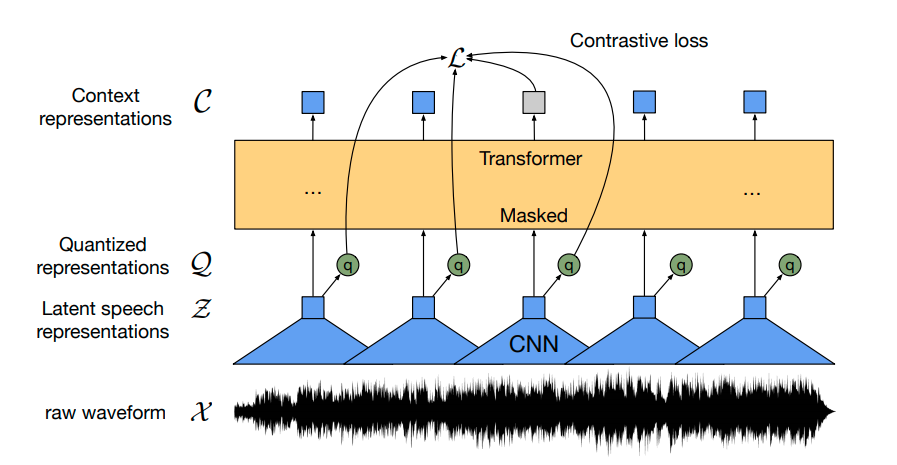
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…

実践におけるFew-shot学習:GPT-Neoと🤗高速推論API
多くの機械学習のアプリケーションでは、利用可能なラベル付きデータの量が高性能なモデルの作成の障害となります。NLPの最新の発展では、大きな言語モデルで推論時にわずかな例を提供することで、この制限を克服することができることが示されています。これはFew-Shot Learningとして知られる技術です。このブログ投稿では、Few-Shot Learningとは何かを説明し、GPT-Neoという大きな言語モデルと🤗 Accelerated Inference APIを使用して独自の予測を生成する方法を探ります。 Few-Shot Learningとは何ですか? Few-Shot Learningは、機械学習モデルに非常に少量の訓練データを与えて予測を行うことを指します。つまり、推論時にいくつかの例を与えるということです。これは、標準的なファインチューニング技術とは異なり、事前に訓練されたモデルが所望のタスクに適応するために比較的大量の訓練データが必要とされるものです。 この技術は主にコンピュータビジョンで使用されてきましたが、EleutherAI GPT-NeoやOpenAI GPT-3などの最新の言語モデルを使用することで、自然言語処理(NLP)でも使用することができるようになりました。 NLPでは、Few-Shot Learningは大規模な言語モデルと組み合わせて使用することができます。これらのモデルは、大規模なテキストデータセットでの事前トレーニング中に暗黙的に多くのタスクを実行することを学習しています。これにより、モデルはわずかな例だけで関連するが以前に見たことのないタスクを理解することができます。 Few-Shot NLPの例は主に以下の3つの主要な要素から構成されます: タスクの説明:モデルが行うべきタスクの短い説明、例えば「英語からフランス語への翻訳」 例:モデルに予測してほしいことを示すいくつかの例、例えば「sea otter => loutre de mer」…

Amazon SageMakerを使用して、Hugging Faceモデルを簡単にデプロイできます
今年早くも、Hugging FaceをAmazon SageMakerで利用しやすくするためにAmazonとの戦略的な協力を発表し、最先端の機械学習機能をより速く提供することを目指しています。新しいHugging Face Deep Learning Containers (DLCs)を導入し、Amazon SageMakerでHugging Face Transformerモデルをトレーニングすることができます。 今日は、Amazon SageMakerでHugging Face Transformersを展開するための新しい推論ソリューションを紹介します!新しいHugging Face Inference DLCsを使用すると、トレーニング済みモデルをわずか1行のコードで展開できます。また、Model Hubから10,000以上の公開モデルを選択し、Amazon SageMakerで展開することもできます。 SageMakerでモデルを展開することで、AWS環境内で簡単にスケーリング可能な本番用エンドポイントが提供されます。モニタリング機能やエンタープライズ向けの機能も組み込まれています。この素晴らしい協力を活用していただければ幸いです! 以下は、新しいSageMaker Hugging Face…

Hugging Face Hubへようこそ、spaCyさん
spaCyは、産業界で広く使用される高度な自然言語処理のための人気のあるライブラリです。spaCyを使用すると、固有表現認識、テキスト分類、品詞タグ付けなどのタスクのためのパイプラインの使用とトレーニングが容易になり、大量のテキストを処理して分析する強力なアプリケーションを構築できます。 Hugging Faceを使用すると、spaCyパイプラインをコミュニティと簡単に共有できます!単一のコマンドで、モデルカードが含まれ、必要なメタデータが自動生成されたパイプラインパッケージをアップロードできます。推論APIは現在、固有表現認識(NER)をサポートしており、パイプラインをブラウザで対話的に試すことができます。また、パッケージ用のライブURLも提供されるため、プロトタイプから本番環境までのスムーズなパスでどこからでもpip installできます! モデルの検索 spaCy orgには、60以上のカノニカルモデルがあります。これらのモデルは最新の3.1リリースからのものであり、最新のリリースモデルをすぐに試すことができます!さらに、コミュニティからのすべてのspaCyモデルはここで見つけることができます:https://huggingface.co/models?filter=spacy。 ウィジェット この統合にはNERウィジェットのサポートも含まれており、NERコンポーネントを持つすべてのモデルは、デフォルトでこれを備えています!近日中に、テキスト分類や品詞タグ付けのサポートも追加されます。 既存のモデルの使用 Hubからのすべてのモデルは、pip installを使用して直接インストールすることができます。 pip install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl # spacy.load()を使用する。 import spacy nlp = spacy.load("en_core_web_sm") # モジュールとしてインポートする。…
スケールにおけるトランスフォーマーの最適化ツールキット、Optimumをご紹介します
この投稿は、Hugging Faceが最先端の機械学習プロダクションパフォーマンスを民主化するための旅の第一歩です。目指すところに到達するために、私たちはハードウェアパートナーと手を組んで取り組む予定です。以下のIntelと協力しています。この旅に参加して、新しいオープンソースライブラリであるOptimumをフォローしてください! なぜ 🤗 Optimum なのか? 🤯 Transformersのスケーリングは難しい Tesla、Google、Microsoft、Facebook、これらの企業に共通するものは何でしょうか?もちろんいくつかありますが、その1つは毎日数十億のTransformerモデルの予測を実行していることです。TeslaのAutoPilotのためのTransformer、Gmailの文章補完のためのTransformer、Facebookの投稿のリアルタイム翻訳のためのTransformer、Bingの自然言語クエリに対する回答のためのTransformerなど、さまざまな用途で使用されています。 Transformerは機械学習モデルの精度を飛躍的に向上させ、NLPを征服し、SpeechやVisionなどの他のモダリティにも広がっています。しかし、これらの巨大なモデルを本番環境に持ち込み、スケールで高速に実行することは、どの機械学習エンジニアリングチームにとっても大きな課題です。 上記の企業のように、数百人の高度に熟練した機械学習エンジニアを雇っていない場合はどうでしょうか?私たちの新しいオープンソースライブラリであるOptimumを通じて、Transformerのプロダクションパフォーマンスのための究極のツールキットを構築し、特定のハードウェア上でモデルをトレーニングおよび実行するための最大の効率性を実現することを目指しています。 🏭 OptimumがTransformerを活用します 最適なパフォーマンスでモデルをトレーニングおよび提供するためには、モデルのアクセラレーション技術は対象のハードウェアと互換性が必要です。各ハードウェアプラットフォームは、パフォーマンスに大きな影響を与える特定のソフトウェアツール、機能、ノブを提供しています。同様に、スパース化や量子化などの高度なモデルアクセラレーション技術を活用するためには、最適化されたカーネルがシリコン上の演算子と互換性があり、モデルアーキテクチャから派生したニューラルネットワークグラフに特化している必要があります。この3次元の互換性行列やモデルアクセラレーションライブラリの使用方法について詳しく調査するのは、ほとんどの機械学習エンジニアにとって困難な作業です。 Optimumはこの作業を簡単にすることを目指し、効率的なAIハードウェアを対象としたパフォーマンス最適化ツールを提供し、ハードウェアパートナーとの共同開発で機械学習エンジニアをML最適化の魔術師に変えます。 Transformerライブラリでは、最先端のモデルを研究者やエンジニアが簡単に使用できるようにし、フレームワーク、アーキテクチャ、パイプラインの複雑さを抽象化しました。 Optimumライブラリでは、エンジニアが利用可能なすべてのハードウェア機能を活用し、ハードウェアプラットフォーム上でのモデルアクセラレーションの複雑さを抽象化することで、エンジニアに簡単になります。 🤗 Optimumの実践:Intel Xeon CPU向けのモデルの量子化方法 🤔 量子化の重要性と正しい方法 BERTなどの事前学習済み言語モデルは、さまざまな自然言語処理タスクで最先端の結果を達成しており、ViTやSpeech2Textなどの他のTransformerベースのモデルも、コンピュータビジョンや音声タスクで最先端の結果を達成しています。Transformerは機械学習の世界で広く使われており、今後も使われ続けます。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…

Gradioを使用して、Spacesで自分のプロジェクトをショーケースしましょう
Gradioを利用することで、機械学習プロジェクトを簡単にデモンストレーションすることができます。 このブログ記事では、以下の内容について説明します: 最近のGradioの統合により、Inference APIを活用してHubからモデルをシームレスにデモンストレーションする方法 Hugging Face Spacesを使用して、独自のモデルのデモをホストする方法 GradioでのHugging Face Hub統合 Hubでモデルを簡単にデモンストレーションすることができます。以下を含むインターフェースを定義するだけでOKです: 推論を行いたいモデルのリポジトリID 説明とタイトル オーディエンスをガイドするための入力例 インターフェースを定義したら、.launch()を呼び出すだけでデモが開始されます。これはColabで行うこともできますが、コミュニティと共有する場合はSpacesを使用するのがおすすめです! SpacesはPythonでMLデモアプリを簡単にホストするための無料の方法です。Spacesを使用するには、https://huggingface.co/new-space にリポジトリを作成し、SDKとしてGradioを選択します。作業が完了すると、app.pyというファイルを作成し、下のコードをコピーするだけで、数秒でアプリを起動できます! import gradio as gr description = "GPT-2によるストーリー生成"…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.