Learn more about Search Results RLHF - Page 12

- You may be interested
- 「イーロン・マスク氏、中国での超知能の...
- 「Amazon SageMaker JumpStartでのテキス...
- LLMツールはソフトウェアの脆弱性を発見し...
- ビッグデータ分析:なぜビジネスインテリ...
- 「ユナイテッド航空がコスト効率の高い光...
- 「ChatGPTエンタープライズ- LLMが行った...
- LlamaIndex インデックスと検索のための究...
- ワイヤレス嗅覚フィードバックシステムはV...
- 統計分析入門ガイド | 5つのステップと例
- 「線形代数からディープラーニングまで 7...
- 「NTUシンガポールの研究者が、3Dポイント...
- 「SQLを使用したデータベースの導入:ハー...
- 「Non-engineers guide LLaMA 2チャットボ...
- 大学フットボールカンファレンスの再編成 ...
- 「大規模言語モデルのための任意のPDFおよ...

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…

ゲーム開発のためのAI:5日間で農業ゲームを作成するパート2
ゲーム開発のためのAIへようこそ!このシリーズでは、AIツールを使用してわずか5日間で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、ゲーム開発のワークフローにさまざまなAIツールを組み込む方法を学ぶことができます。以下に挙げる項目について、どのようにAIツールを使用できるかを紹介します。 アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンがほしいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注意:このチュートリアルは、Unity開発とC#に精通している読者を対象としています。これらの技術に慣れていない場合は、続ける前に「Unity for Beginners」シリーズをチェックしてください。 2日目:ゲームデザイン このチュートリアルシリーズのパート1では、AI for Art Styleを使用しました。具体的には、Stable Diffusionを使用してコンセプトアートを生成し、ゲームのビジュアルスタイルを開発しました。 このパートでは、ゲームデザインのためのAIを使用します。The Short Versionでは、ChatGPTをゲームアイデアの開発ツールとして使用した方法について説明します。しかし、もっと重要なのは、ここで実際に何が起こっているのかです。ゲーム開発における言語モデルとその広範な使用法についての背景については、読み続けてください。 The Short Version 簡単なバージョンはシンプルです。ChatGPTにアドバイスを求め、自己責任でそのアドバイスに従ってください。農業ゲームの場合、私はChatGPTに次のように尋ねました。…

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

大規模な言語モデルによるレッドチーミング
警告: この記事はレッドチーミングについてであり、そのためモデル生成の例が不快または不快なものである可能性があります。 大量のテキストデータで訓練された大規模な言語モデル(LLM)は、現実的なテキストを生成するのに非常に優れています。しかし、これらのモデルは、個人情報(社会保障番号など)の公開や誤情報、偏見、憎悪、有害なコンテンツの生成など、望ましくない振る舞いをしばしば示します。たとえば、GPT3の以前のバージョンは、性差別的な振る舞い(以下参照)やムスリムに対する偏見を示すことが知られていました。 LLMを使用する際にこのような望ましくない結果を発見した場合、Generative Discriminator Guided Sequence Generation(GeDi)やPlug and Play Language Models(PPLM)などの戦略を開発してそれらからそれを逸らすことができます。以下は、同じプロンプトを使用してGPT3の生成を制御するためにGeDiを使用した例です。 最近のGPT3のバージョンでも、プロンプトインジェクションによる攻撃を受けると同様に不快なテキストが生成され、その結果、下流のアプリケーションのセキュリティ上の懸念となる可能性があります。このブログで説明されています。 レッドチーミングは、望ましくない振る舞いを引き起こす可能性のあるモデルの脆弱性を引き出す評価の形式です。ジェイルブレイキングは、LLMがそのガードレールから逸脱するように操作されるレッドチーミングの別の言葉です。MicrosoftのチャットボットTay(2016年)やより最近のBingのチャットボットシドニーは、レッドチーミングを使用して基礎となるMLモデルの徹底的な評価の欠如がどれほど壊滅的な結果をもたらすかの実際の例です。レッドチームのアイデアの起源は、軍隊によって実施された対抗者シミュレーションやウォーゲームに遡ることができます。 レッドチーミングの目標は、モデルが有害なテキストを生成する可能性が高いテキストを生成するようにするプロンプトを作成することです。レッドチーミングは、MLのより一般的に知られた評価形式である敵対的攻撃といくつかの類似点と相違点を共有しています。その類似点は、レッドチーミングと敵対的攻撃が実際のユースケースで望ましくないコンテンツを生成するためにモデルを「攻撃」または「だます」という共通の目標を持っていることです。ただし、敵対的攻撃は人間には理解しにくい場合があります。たとえば、各プロンプトに「aaabbbcc」という文字列を接頭辞として付けると、モデルのパフォーマンスが低下するためです。Wallace et al.、’19では、さまざまなNLP分類および生成タスクにおけるそのような攻撃の多くの例が議論されています。一方、レッドチーミングのプロンプトは通常、通常の自然言語のプロンプトと似ています。 レッドチーミングは、ユーザーの不快な体験を引き起こしたり、悪意を持つユーザーによる暴力やその他の違法な活動を支援する可能性があるモデルの制限を明らかにすることができます。レッドチーミングからの出力(敵対的攻撃と同様)は、一般にモデルを訓練して、有害な結果を引き起こす可能性を低くするか、またはそれから逸らすために使用されます。 レッドチーミングは、可能なモデルの障害物の創造的な考えを必要とするため、リソースを消費する問題です。回避策として、与えられたプロンプトにオフェンシブな生成を引き起こす可能性のあるトピックやフレーズを予測するために訓練された分類器をLLMに追加することができます。このような戦略は慎重な方向に進むでしょう。しかし、それは非常に制限的であり、モデルを頻繁に回避的にする原因となります。したがって、モデルが役立つこと(指示に従うこと)と無害であること(少なくとも有害な行動を引き起こしにくいこと)の間には緊張があります。 レッドチームは、ハードループ内の人間または有害な出力をテストするために別のLMをテストしているLMです。安全性とアライメントのためにファインチューニングされたモデルに対してレッドチーミングプロンプトを作成するには、Ganguli et al.、’22で説明されているような悪意のあるキャラクターとして振る舞うようにLLMに指示する役割プレイ攻撃の形で創造的な思考が必要です。モデルに自然言語の代わりにコードで応答するように指示することも、モデルの学習バイアスを明らかにすることができます。 さらなる例については、このツイートスレッドをご覧ください。 ChatGPT自体によるLLMのジェイルブレイキングのアイデアのリストは次のとおりです。…

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…
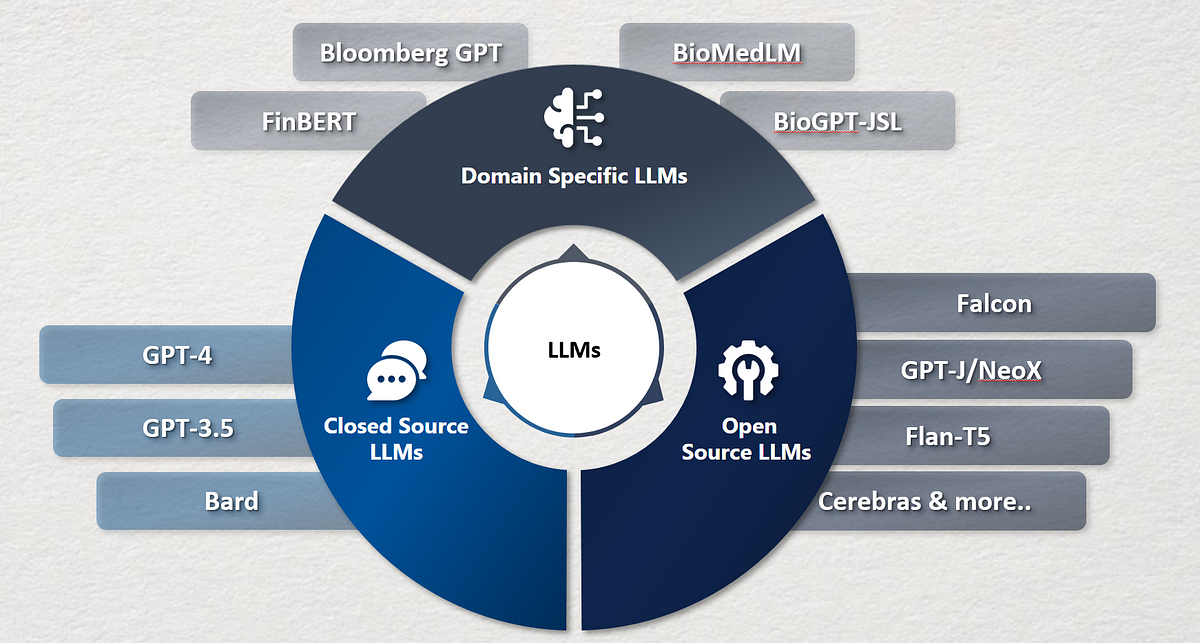
企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
最近の数年間で、言語モデルは大きな注目を集め、自然言語処理、コンテンツ生成、仮想アシスタントなど、さまざまな分野を革新しました最も注目されているのは、

ゼロから大規模言語モデルを構築するための初心者ガイド
はじめに TwitterやLinkedInなどで、私は毎日多くの大規模言語モデル(LLMs)に関する投稿に出会います。これらの興味深いモデルに対してなぜこれほど多くの研究と開発が行われているのか、私は疑問に思ったこともあります。ChatGPTからBARD、Falconなど、無数のモデルの名前が飛び交い、その真の性質を解明したくなるのです。これらのモデルはどのように作成されるのでしょうか?大規模言語モデルを構築するにはどうすればよいのでしょうか?これらのモデルは、あなたが投げかけるほとんどの質問に答える能力を持つのはなぜでしょうか?これらの燃えるような疑問は私の心に長く残り、好奇心をかき立てています。この飽くなき好奇心は私の内に火をつけ、LLMsの領域に飛び込む原動力となっています。 私たちがLLMsの最先端について議論する刺激的な旅に参加しましょう。一緒に、彼らの開発の現状を解明し、彼らの非凡な能力を理解し、彼らが言語処理の世界を革新した方法に光を当てましょう。 学習目標 LLMsとその最新の状況について学ぶ。 利用可能なさまざまなLLMsとこれらのLLMsをゼロからトレーニングするアプローチを理解する。 LLMsのトレーニングと評価におけるベストプラクティスを探究する。 準備はいいですか?では、LLMsのマスタリングへの旅を始めましょう。 大規模言語モデルの簡潔な歴史 大規模言語モデルの歴史は1960年代にさかのぼります。1967年にMITの教授が、自然言語を理解するための最初のNLPプログラムであるElizaを作成しました。Elizaはパターンマッチングと置換技術を使用して人間と対話し理解することができます。その後、1970年にはMITチームによって、人間と対話し理解するための別のNLPプログラムであるSHRDLUが作成されました。 1988年には、テキストデータに存在するシーケンス情報を捉えるためにRNNアーキテクチャが導入されました。2000年代には、RNNを使用したNLPの研究が広範に行われました。RNNを使用した言語モデルは当時最先端のアーキテクチャでした。しかし、RNNは短い文にはうまく機能しましたが、長い文ではうまく機能しませんでした。そのため、2013年にはLSTMが導入されました。この時期には、LSTMベースのアプリケーションで大きな進歩がありました。同時に、アテンションメカニズムの研究も始まりました。 LSTMには2つの主要な懸念がありました。LSTMは長い文の問題をある程度解決しましたが、実際には非常に長い文とはうまく機能しませんでした。LSTMモデルのトレーニングは並列化することができませんでした。そのため、これらのモデルのトレーニングには長い時間がかかりました。 2017年には、NLPの研究において Attention Is All You Need という論文を通じてブレークスルーがありました。この論文はNLPの全体的な景色を変革しました。研究者たちはトランスフォーマーという新しいアーキテクチャを導入し、LSTMに関連する課題を克服しました。トランスフォーマーは、非常に多数のパラメータを含む最初のLLMであり、LLMsの最先端モデルとなりました。今日でも、LLMの開発はトランスフォーマーに影響を受けています。 次の5年間、トランスフォーマーよりも優れたLLMの構築に焦点を当てた重要な研究が行われました。LLMsのサイズは時間とともに指数関数的に増加しました。実験は、LLMsのサイズとデータセットの増加がLLMsの知識の向上につながることを証明しました。そのため、BERT、GPTなどのLLMsや、GPT-2、GPT-3、GPT 3.5、XLNetなどのバリアントが導入され、パラメータとトレーニングデータセットのサイズが増加しました。 2022年には、NLPにおいて別のブレークスルーがありました。 ChatGPT は、あなたが望むことを何でも答えることができる対話最適化されたLLMです。数か月後、GoogleはChatGPTの競合製品としてBARDを紹介しました。…

自動車産業における生成AIの画期的な影響
生成AIは、製造業の進歩、自動化の向上、乗客の福祉と安全性の向上など、自動車産業を含むさまざまな分野で変革的な力として現れています。生成AIは、自動車の様々な側面を革新することができます。 この記事では、現在と将来の車における生成AIのさまざまな応用について説明します。 自動運転車(AV) 生成AIの力を利用することで、仮想環境や現実的なシミュレーションの構築に役立つ画像やビデオを生成することができます。これにより、自動運転車(AV)は制御された環境内で学習し適応することができます。 さらに、AVには信頼性の高いセンサーデータが大量に必要であり、生成AIモデルを使用することで、現実世界の状況を代表する合成データを生成することができます。これにより、高コストかつ時間のかかる現地テストの必要性をなくすことができます。また、大量のデータを生成することにより、生成AIは意思決定モデルのトレーニングに使用できる実用的なアルゴリズムの作成に役立ちます。 ユーザーのパーソナライズ 生成AIモデルは、ユーザーの好みを予測する能力を持っています。例えば、与えられたルートに基づいて好みのルートを予測し、オンラインマーケットプレイスを個別化し、サービスの推薦を提供する機械学習アルゴリズムなどがあります。さらに、この技術はユーザーのダッシュボードの設定に自動的に適応し、よく使用される機能がナビゲーションパネルでより目立つようになります。 また、最も興味深い将来の応用の1つは、生成AIによって動力を得た車内パーソナルアシスタントです。これは、会話能力と包括的なサポートを備えた知能型のパーソナルアシスタントと考えることができます。 マーケティング 生成モデルは、マーケティングや広告における顧客エンゲージメントを革新し、より効果的な結果を生み出します。パワフルな生成AIツールであるJasperは、GPT-3上に構築されており、販売用メール、ブログ、ソーシャルメディアの投稿など、顧客中心のマーケティングコンテンツを簡単に生成します。一方、DALL-E 2などの画像生成モデルは、広告業界で人気を集めています。 この革新的な技術は、従来のマーケティング予算から具体的な結果を得るのが難しい自動車会社にとって、有望な解決策を提供します。生成AIを使用することで、これらの企業はマーケティング投資をより効果的に追跡し最適化することができ、リソースの効率的かつ効果的な割り当てを確保することができます。 製品開発 自動車産業は数年にわたって10億ドル以上を製品開発に投資しており、生成AIはデザイン、開発、納品の段階の時間差を最小限に抑えることでコスト削減の機会を提供します。これは、データの合成、分析、パターン検出、結果の予測などの能力によって実現されます。 予測メンテナンス 生成AIはIoTと連携して予測メンテナンスを提供することができます。IoTシステムと統合された車の数が増えるにつれて、車両に埋め込まれたセンサーは車両の状態に関するリアルタイム情報を提供します。生成AIを活用することで、これらの膨大なデータセットを分析し、異常を検出し、車両のメンテナンスの必要性について的確な判断を行うことができます。 自動車産業における生成AIの実際の例 メルセデス・ベンツ メルセデスはベータプログラムの一環としてGPTモデルを90万台の車に導入しました。このモデルは、会社の音声アシスタントを介してアクセスすることができ、ドライバーは目的地について問い合わせたり、新しい夕食のレシピの提案や複雑な質問に対する回答を求めたりすることができます。 BMW BMWは、生成AIをデザインプロセスに組み込んでおり、重量最適化、接続ポイント、負荷容量などの正確なデザイン仕様を考慮したAIモデルを活用しています。このモデルは、デザイン基準を満たす革新的で効率的かつ視覚的に魅力的な車両部品を幅広く生成し、新しいデザイン提案の開発に必要な時間を大幅に短縮すると同時に、デザイン要件の達成を保証します。 トヨタ トヨタリサーチインスティチュート(TRI)は、革新的な生成AI技術を導入して車両デザイナーの能力を向上させています。公開されているテキストから画像を生成する生成AIツールを活用することで、デザイナーは初期のデザインスケッチとエンジニアリングの制約を創造的なプロセスに取り入れることができます。この新しい技術により、デザインとエンジニアリングの考慮事項を調和させるために必要な反復を大幅に減らし、デザイナーにとってより効率的なワークフローを提供します。 テスラ…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.