Learn more about Search Results ImageNet - Page 12

- You may be interested
- Snowflakeにおけるクエリ性能の向上と関連...
- 「AIの誤情報:なぜそれが機能するのか、...
- 「初期ランキング段階への原則的なアプロ...
- IPUを使用したHugging Face Transformers...
- 「ゼロからヒーローへ:AutoGenがLLMを変...
- 「SMPLitexに会ってください:単一画像か...
- 「量子ブースト:cuQuantumとPennyLaneに...
- 「Pythonによるデータクリーニングの技術...
- 「陪審団がGoogleのアプリストアが反競争...
- 「Pandas:データをワンホットエンコード...
- 「LangChainとOpenAIを使用して、自己モデ...
- 洞察を具体的な成果に変える
- 取りましょう NVIDIA NeMo SteerLMは、推...
- エンティティの解決実装の複雑さ
- Scikit-Learnを使用した特徴選択の方法

Hugging Faceデータセットとトランスフォーマーを使用した画像の類似性
この投稿では、🤗 Transformersを使用して画像の類似性システムを構築する方法を学びます。クエリ画像と候補画像の類似性を見つけることは、逆画像検索などの情報検索システムの重要なユースケースです。システムが答えようとしているのは、クエリ画像と候補画像セットが与えられた場合、どの画像がクエリ画像に最も類似しているかということです。 このシステムの構築には、このシステムの構築時に便利な並列処理をシームレスにサポートする🤗のdatasetsライブラリを活用します。 この投稿では、ViTベースのモデル( nateraw/vit-base-beans )と特定のデータセット(Beans)を使用していますが、ビジョンモダリティをサポートし、他の画像データセットを使用するために拡張することもできます。試してみることができるいくつかの注目すべきモデルには次のものがあります: Swin Transformer ConvNeXT RegNet また、投稿で紹介されているアプローチは、他のモダリティにも拡張できる可能性があります。 完全に動作する画像の類似性システムを学習するには、最初に2つの画像間の類似性をどのように定義するかを定義する必要があります。 このシステムを構築するためには、まず与えられた画像の密な表現(埋め込み)を計算し、その後、余弦類似性指標を使用して2つの画像の類似性を決定する一般的な方法があります。 この投稿では、画像をベクトル空間で表現するために「埋め込み」を使用します。これにより、画像の高次元ピクセル空間(たとえば224 x 224 x 3)を意味のある低次元空間(たとえば768)にうまく圧縮する方法が得られます。これによる主な利点は、後続のステップでの計算時間の削減です。 画像から埋め込みを計算するために、入力画像をベクトル空間で表現する方法について理解しているビジョンモデルを使用します。このタイプのモデルは画像エンコーダとも呼ばれます。 モデルをロードするために、AutoModelクラスを活用します。これにより、Hugging Face Hubから互換性のあるモデルチェックポイントをロードするためのインターフェースが提供されます。モデルと共に、データ前処理に関連するプロセッサもロードします。 from transformers…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…

Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
この投稿では、安定拡散を教えるための指示調整について説明します。この方法では、入力画像と「指示」(例:自然画像に漫画フィルタを適用する)を使用して、安定拡散を促すことができます。 ユーザーの指示に従って安定拡散に画像編集を実行させるアイデアは、「InstructPix2Pix: Learning to Follow Image Editing Instructions」で紹介されました。InstructPix2Pixのトレーニング戦略を拡張して、画像変換(漫画化など)や低レベルな画像処理(画像の雨除去など)に関連するより具体的な指示に従う方法について説明します。以下をカバーします: 指示調整の紹介 この研究の動機 データセットの準備 トレーニング実験と結果 潜在的な応用と制約 オープンな問い コード、事前学習済みモデル、データセットはこちらで見つけることができます。 導入と動機 指示調整は、タスクを解決するために言語モデルに指示を従わせる教師ありの方法です。Googleの「Fine-tuned Language Models Are Zero-Shot Learners (FLAN)」で紹介されました。最近では、AlpacaやFLAN V2などの作品が良い例であり、指示調整がさまざまなタスクにどれだけ有益であるかを示しています。…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

Transformers.jsを使用してMLを搭載したウェブゲームの作成
このブログ記事では、ブラウザ上で完全に動作するリアルタイムのMLパワードWebゲーム「Doodle Dash」を作成した方法を紹介します(Transformers.jsのおかげで)。このチュートリアルの目的は、自分自身でMLパワードのWebゲームを作成するのがどれだけ簡単かを示すことです… ちょうどOpen Source AI Game Jam(2023年7月7日-9日)に間に合います。まだ参加していない場合は、ぜひゲームジャムに参加してください! ビデオ:Doodle Dashデモビデオ クイックリンク デモ:Doodle Dash ソースコード:doodle-dash ゲームジャムに参加:Open Source AI Game Jam 概要 始める前に、作成する内容について話しましょう。このゲームは、GoogleのQuick, Draw!ゲームに触発されており、単語とニューラルネットワークが20秒以内にあなたが描いているものを推測するというものです(6回繰り返し)。実際には、彼らのトレーニングデータを使用して独自のスケッチ検出モデルを訓練します!オープンソースは最高ですよね? 😍 このバージョンでは、1つのプロンプトずつできるだけ多くのアイテムを1分間で描くことができます。モデルが正しいラベルを予測した場合、キャンバスがクリアされ、新しい単語が与えられます。タイマーが切れるまでこれを続けてください!ゲームはブラウザ内でローカルに実行されるため、サーバーの遅延について心配する必要はありません。モデルはあなたが描くと同時にリアルタイムの予測を行うことができます… 🤯…

Perceiver AR(パーシーバーAR):汎用、長文脈の自己回帰生成
私たちはPerceiver ARを開発していますこれは自己回帰型であり、モダリティを問わないアーキテクチャで、クロスアテンションを使用して長距離の入力を少数の潜在変数にマッピングすると同時に、エンドツーエンドの因果的マスキングを維持しますPerceiver ARは、手作りの疎なパターンやメモリメカニズムの必要なしに、10万以上のトークンに直接アテンションを注ぐことができ、実用的な長文脈の密度推定を可能にします
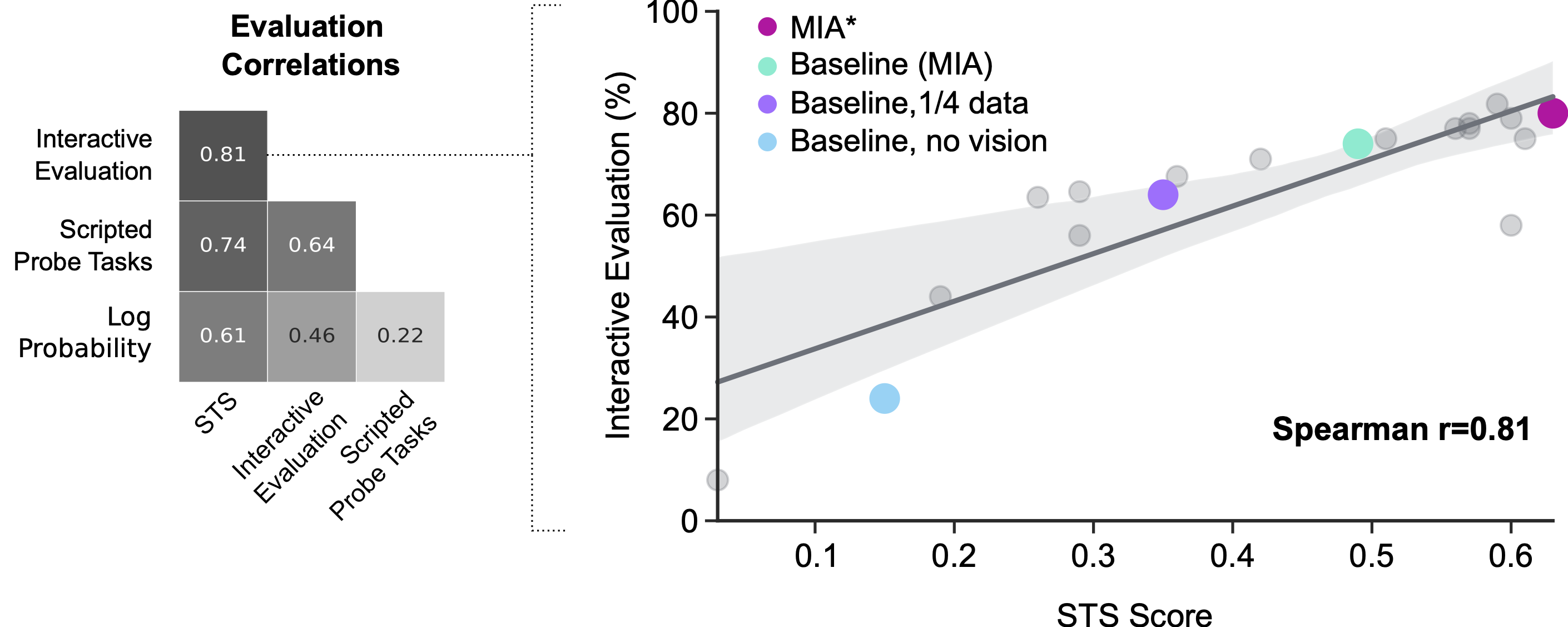
マルチモーダルインタラクティブエージェントの評価
この論文では、これらの既存の評価尺度の利点を評価し、Standardised Test Suite (STS) と呼ばれる評価方法の新しいアプローチを提案しますSTSは、実際の人間の相互作用データから採掘された行動シナリオを使用します

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.