Learn more about Search Results App Store - Page 12

- You may be interested
- PandasAIの紹介:GenAIを搭載したデータ分...
- SDFStudio(エスディーエフスタジオ)は、...
- 「パフォーマンスと使いやすさを向上させ...
- 「GO TO Any Thing(GOAT)」とは、完全に...
- 画像認識におけるディープラーニング:技...
- 東京理科大学の研究者は、材料科学におけ...
- AIにおけるブロックチェーンの包括的なレ...
- AutoMLのジレンマ
- LOMO(LOw-Memory Optimization)をご紹介...
- Transcript AIコンテンツの生成を検出する
- ビジネスを革新する3つの素晴らしい方法
- NLPスーパーパワーを活用する:ステップバ...
- 「これら6つの必須データサイエンススキル...
- 「PyrOSM Open Street Mapデータとの作業」
- JupyterAI 生成AI + JupyterLab
「複雑さを排除したデータレイクテーブル上のデータアクセスAPI」
データレイクテーブルは、主にSparkやFlinkなどのビッグデータコンピュートエンジンを使用するデータエンジニアリングチームや、モデルやレポートを作成するデータアナリストや科学者によって利用されます

VoAGI ニュース、9月27日:ChatGPT プロジェクトのチートシート • PyTorch & Lightning AI の紹介
「10 シャットGPT プロジェクト チートシート • ディープ ラーニング ライブラリ入門 PyTorch と Lightning AI • GPT-4 のトップ5の無料の代替手段 • マシン ラーニング 評価メトリックス 理論と概要 • Poe とのキックアス 中間進化のプロンプト」

「Matplotlibのマスタリング:データ可視化の包括的なガイド」
こんにちは、データ愛好家👋 データはビジュアライゼーションを通じてより理解しやすくなることを知っていますそれは洞察を得るのに役立つだけでなく、ビジュアライゼーションはクライアントに洞察を説明するのも簡単にします...

本番環境向けのベクトル検索の構築
ベクトルストアは、機械学習の進化において重要な役割を果たし、データの数値エンコーディングのための必須のリポジトリとして機能しますベクトルは、多次元空間におけるカテゴリカルなデータポイントを表すために使用される数学的なエンティティです機械学習の文脈では、ベクトルストアは、データの保存、取得、フィルタリングを行う手段を提供します

農業におけるビジョン・トランスフォーマー | 革新的な収穫
はじめに 農業は常に人類文明の基盤であり、数十億人に生計と食料を提供してきました。技術の進歩により、農業の実践を向上させるための新たで革新的な方法が見つかっています。そのような進歩の一つが、Vision Transformers(ViTs)を使用して作物の葉の病気を分類することです。このブログでは、農業におけるビジョン・トランスフォーマーが、作物の病気の特定と軽減のための効率的かつ正確な解決策を提供することで、革命を起こしていることを探求します。 キャッサバ、またはマニオクまたはユカは、食事の主食から産業用途までさまざまな用途がある多目的な作物です。その耐久性と強靭さは、栽培条件の厳しい地域で不可欠な作物です。しかし、キャッサバの植物はさまざまな病気に対して脆弱であり、CMDとCBSDが最も破壊的なものの一部です。 CMDは、ホワイトフライによって伝播される複数のウイルスによって引き起こされ、キャッサバの葉に重度のモザイク症状を引き起こします。一方、CBSDは、2つの関連するウイルスによって引き起こされ、主に貯蔵根に影響を与え、食用に適さなくします。これらの病気を早期に特定することは、広範な作物被害を防ぐために重要であり、食料の安全保障を確保するために不可欠です。Vision Transformersは、自然言語処理(NLP)のために最初に設計されたトランスフォーマー・アーキテクチャの進化形であり、視覚データの処理に非常に効果的であることが証明されています。これらのモデルは、パッチのシーケンスとして画像を処理し、データ内の複雑なパターンと関係を捉えるために自己注意機構を使用します。キャッサバの葉の病気分類の文脈では、ViTsは感染したキャッサバの葉の画像を分析してCMDとCBSDを特定するために訓練されます。 学習成果 ビジョン・トランスフォーマーとそれらが農業にどのように適用され、特に葉の病気の分類においてどのように使用されるかを理解する。 トランスフォーマー・アーキテクチャの基本的な概念、自己注意機構などの理解し、これらが視覚データの処理にどのように適応されるかを学ぶ。 キャッサバの葉の病気の早期検出のために農業におけるビジョン・トランスフォーマー(ViTs)の革新的な利用方法を理解する。 スケーラビリティやグローバルなコンテキストなどのビジョン・トランスフォーマーの利点、および計算要件やデータ効率などの課題についての洞察を得る。 この記事は、Data Science Blogathonの一環として公開されました。 ビジョン・トランスフォーマーの台頭 コンピュータビジョンは、畳み込みニューラルネットワーク(CNN)の開発により、近年大きな進歩を遂げています。CNNは、画像分類から物体検出まで、さまざまな画像関連のタスクのための定番アーキテクチャとなっています。しかし、ビジョン・トランスフォーマーは、視覚情報の処理に新しい手法を提供する強力な代替手段として台頭しています。Google Researchの研究者たちは、2020年に「画像は16×16の単語に値する:スケールでの画像認識のためのトランスフォーマー」という画期的な論文でビジョン・トランスフォーマーを紹介しました。彼らは、もともと自然言語処理(NLP)のために設計されたトランスフォーマー・アーキテクチャをコンピュータビジョンの領域に適応させました。この適応により、新たな可能性と課題が生まれました。 ViTsの使用は、従来の方法に比べていくつかの利点を提供しています。それには以下のものがあります: 高い精度:ViTsは高い精度であり、葉の病気の信頼性のある検出と区別が可能です。 効率性:訓練された後、ViTsは画像を素早く処理できるため、現場でのリアルタイム病気検出に適しています。 スケーラビリティ:ViTsはさまざまなサイズのデータセットを処理できるため、さまざまな農業環境に適応できます。 汎化性:ViTsはさまざまなキャッサバの品種や病気のタイプに汎化することができ、各シナリオごとに特定のモデルが必要な必要性を減らします。 トランスフォーマー・アーキテクチャの概要 ビジョン・トランスフォーマーに入る前に、トランスフォーマー・アーキテクチャの核心的な概念を理解することが重要です。トランスフォーマーは、もともとNLPのために設計され、言語処理のタスクを革新しました。トランスフォーマーの主な特徴は、自己注意機構と並列化であり、より包括的な文脈理解とより高速なトレーニングを可能にします。…

『LangChain & Flan-T5 XXL の解除 | 効率的なドキュメントクエリのガイド』
はじめに 大規模言語モデル(LLM)として知られる特定の人工知能モデルは、人間のようなテキストを理解し生成するために設計されています。”大規模”という用語は、それらが持つパラメータの数によってしばしば定量化されます。たとえば、OpenAIのGPT-3モデルは1750億個のパラメータを持っています。これらのモデルは、テキストの翻訳、質問への回答、エッセイの執筆、テキストの要約など、さまざまなタスクに使用することができます。LLMの機能を示すリソースやそれらとチャットアプリケーションを設定するためのガイダンスが豊富にありますが、実際のビジネスシナリオにおける適用可能性を徹底的に検討した試みはほとんどありません。この記事では、LangChain&Flan-T5 XXLを活用して、大規模言語ベースのアプリケーションを構築するためのドキュメントクエリングシステムを作成する方法について学びます。 学習目標 技術的な詳細に踏み込む前に、この記事の学習目標を確立しましょう: LangChainを活用して大規模言語ベースのアプリケーションを構築する方法を理解する テキスト対テキストフレームワークとFlan-T5モデルの簡潔な概要 LangChain&任意のLLMモデルを使用してドキュメントクエリシステムを作成する方法 これらの概念を理解するために、これらのセクションについて詳しく説明します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 LLMアプリケーションの構築におけるLangChainの役割 LangChainフレームワークは、チャットボット、生成型質問応答(GQA)、要約など、大規模言語モデル(LLM)の機能を活用したさまざまなアプリケーションの開発に設計されています。LangChainは、ドキュメントクエリングシステムを構築するための包括的なソリューションを提供します。これには、コーパスの前処理、チャンキングによるこれらのチャンクのベクトル空間への変換、クエリが行われたときに類似のチャンクを特定し、適切な回答にドキュメントを洗練するための言語モデルの活用が含まれます。 Flan-T5モデルの概要 Flan-T5は、Googleの研究者によって商業的に利用可能なオープンソースのLLMです。これはT5(Text-To-Text Transfer Transformer)モデルの派生モデルです。T5は、”テキスト対テキスト”フレームワークでトレーニングされた最先端の言語モデルです。さまざまなNLPタスクを実行するために、タスクをテキストベースの形式に変換することでトレーニングされます。FLANは、Finetuned Language Netの略です。 ドキュメントクエリシステムの構築に入りましょう LangChainとFlan-T5 XXLモデルを使用して、Google Colabの無料版でこのドキュメントクエリシステムを構築することができます。以下の手順に従ってドキュメントクエリシステムを構築しましょう: 1:必要なライブラリのインポート 以下のライブラリをインポートする必要があります:…

「Amazon SageMakerを使用して、Rayベースの機械学習ワークフローをオーケストレーションする」
機械学習(ML)は、お客様がより困難な問題を解決しようとするにつれて、ますます複雑になっていますこの複雑さはしばしば、複数のマシンを使用して単一のモデルをトレーニングする必要性を引き起こしますこれにより、複数のノード間でタスクを並列化することが可能になり、トレーニング時間の短縮、スケーラビリティの向上、[…] などがもたらされます
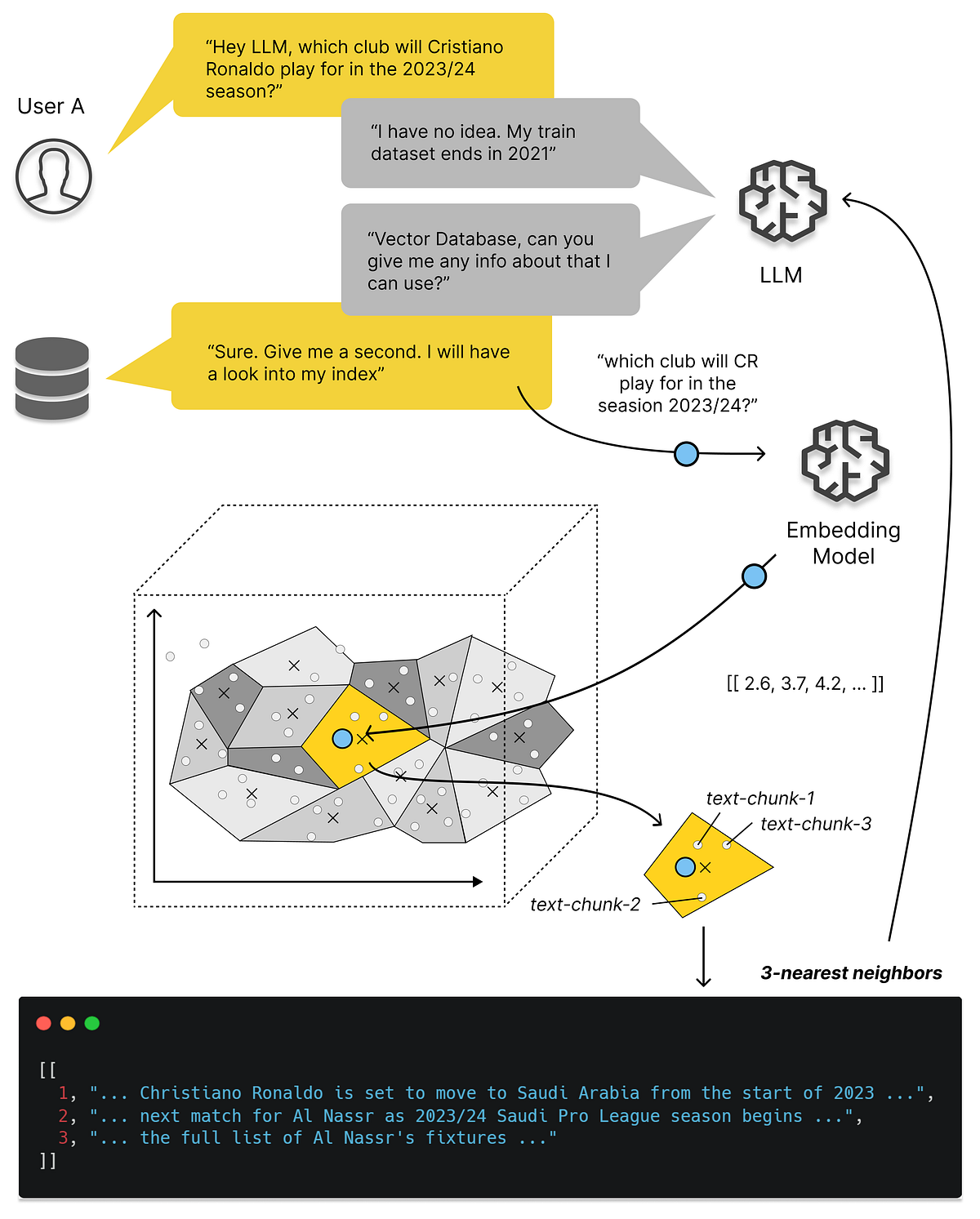
ベクトルデータベースについて知っておくべきすべてと、それらを使用してLLMアプリを拡張する方法
「ベクトルデータベースの特別な点は何ですか? 文の意味を数値表現にどのようにマッピングしますか? それが私たちのLLMアプリにどのように役立ちますか? なぜ私たちは単にLLMに持っているすべてのデータを与えることができないのですか…」

「Pythonにおけるフィボナッチ数列 | コード、アルゴリズム、その他」
イントロダクション Pythonにおけるフィボナッチ数列は、0と1で始まる数学的な数列であり、各後続の数は前の2つの数の合計となります。Pythonでは、フィボナッチ数列を生成することは、クラシックなプログラミングの演習だけでなく、再帰と反復的な解法を探求する素晴らしい方法でもあります。 F(0) = 0 F(1) = 1 F(n) = F(n-1) + F(n-2) (ただし、n > 1) フィボナッチ数列とは何ですか? フィボナッチ数列は、0と1で始まる数列であり、それぞれの数は直前の2つの数の合計です。 無料でPythonを学びたいですか? 今すぐ無料のコースを探索してください! フィボナッチ数列の数学的な式 フィボナッチ数列を計算するための数学的な式は次のとおりです: F(n) =…

「LangchainとDeep Lakeでドキュメントを検索してください!」
イントロダクション langchainやdeep lakeのような大規模言語モデルは、ドキュメントQ&Aや情報検索の分野で大きな進歩を遂げています。これらのモデルは世界について多くの知識を持っていますが、時には自分が何を知らないかを知ることに苦労することがあります。それにより、知識の欠落を埋めるためにでたらめな情報を作り出すことがありますが、これは良いことではありません。 しかし、Retrieval Augmented Generation(RAG)という新しい手法が有望です。RAGを使用して、プライベートな知識ベースと組み合わせてLLMにクエリを投げることで、これらのモデルをより良くすることができます。これにより、彼らはデータソースから追加の情報を得ることができ、イノベーションを促進し、十分な情報がない場合の誤りを減らすことができます。 RAGは、プロンプトを独自のデータで強化することによって機能し、大規模言語モデルの知識を高め、同時に幻覚の発生を減らします。 学習目標 1. RAGのアプローチとその利点の理解 2. ドキュメントQ&Aの課題の認識 3. シンプルな生成とRetrieval Augmented Generationの違い 4. Doc-QnAのような業界のユースケースでのRAGの実践 この学習記事の最後までに、Retrieval Augmented Generation(RAG)とそのドキュメントの質問応答と情報検索におけるLLMのパフォーマンス向上への応用について、しっかりと理解を持つことができるでしょう。 この記事はデータサイエンスブログマラソンの一環として公開されました。 はじめに ドキュメントの質問応答に関して、理想的な解決策は、モデルに質問があった時に必要な情報をすぐに与えることです。しかし、どの情報が関連しているかを決定することは難しい場合があり、大規模言語モデルがどのような動作をするかに依存します。これがRAGの概念が重要になる理由です。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.