Learn more about Search Results AI workflow - Page 12

- You may be interested
- 「科学者たちが歴史的なコードを解読し、...
- 🤗 Transformersを使用してTensorFlowとTP...
- 「採用されるデータアナリストの履歴書の...
- 2024年にSQLの概念をマスターするためのト...
- 「16/10から22/10までの週のトップ重要な...
- テクノロジーを通じたアクセシビリティと...
- 「魔法の角度」グラフェンにおける磁気サ...
- 「BlindChat」に会いましょう:フルブラウ...
- パスワードを使用したGit認証の非推奨化
- 「ハッカソンが量子の可能性を垣間見せる」
- ハギングフェイスTGIを使用した大規模言語...
- 『感情を人工知能、OpenAI、および探索的...
- 「AIパワード広告でソーシャルをより魅力...
- 「Apple TV用の最高の10のVPN(2023年8月)」
- 「人工知能生成コンテンツ(AIGC)におけ...
「コードを使用して、大規模な言語モデルを使って、どんなPDFや画像ファイルでもチャットする方法」
「PDFや画像ファイルには非常に価値のある情報が閉じ込められています幸いにも、私たちにはこれらのファイルを処理して特定の情報を見つけることができる強力な脳があります実際、それは素晴らしいことですそれが…」

「SDXL 1.0の登場」
機械学習の急速に進化する世界では、新しいモデルやテクノロジーがほぼ毎日私たちのフィードに押し寄せるため、最新情報を把握し、情報を元にした選択をすることは困難な課題となります今日は、私たちは...

「Pythonによる正規表現のマスタリング」
この記事では、Pythonを使った正規表現の世界に深く立ち入り、複雑ですが強力なツールをマスターしたい人にとっての包括的なガイドを提供します詳細な説明とコードの例もあります

「Amazon SageMakerを使用して、薬剤探索を加速するためのタンパク質折り畳みワークフローを構築する」
薬の開発は、数千種類の薬候補をスクリーニングし、計算や実験的な手法を用いてリードを評価するという複雑で長いプロセスですマッキンゼーによると、1つの薬を疾患ターゲットの同定、薬のスクリーニング、薬のターゲットの検証、そして最終的な商業化までには、10年かかり、平均で26億ドルの費用がかかるとのことです[...]
ランキング評価指標の包括的ガイド
「ランキングは、機械学習における問題であり、目的はエンドユーザーに最適な方法でドキュメントのリストを並べ替え、最も関連性の高いドキュメントが上位に表示されるようにすることですランキングは…」

データサイエンス入門:初心者向けガイド
この記事は新しいデータサイエンティストのためのガイドであり、迅速に始めるのを助けるために設計されていますこれは出発点となるものですが、既に新しい仕事を探している場合は、この記事をもっと読むことをお勧めします

「鳩の中に猫を投げ込む?大規模言語モデルによる人間の計算の補完」
「語源学には常に魅了されてきました多くの場合、言葉やフレーズが私たちが非常に馴染んでいる意味を獲得する過程には、興味深いストーリーがあります変化を経て…」

「PIP、Conda、requirements.txtを忘れましょう!代わりにPoetryを使って、私に感謝してください」
「痛みのない依存関係管理がついに実現しました」
LLM(Language Model)をアプリケーションに統合する際の複雑さと課題
「OpenAIのChatGPTとGPT APIがリリースされる前から、大規模な言語モデル(LLM)は存在していましたしかし、OpenAIの取り組みのおかげで、GPTは今や開発者や非開発者にとって簡単にアクセスできるようになりましたこのリリースは...」
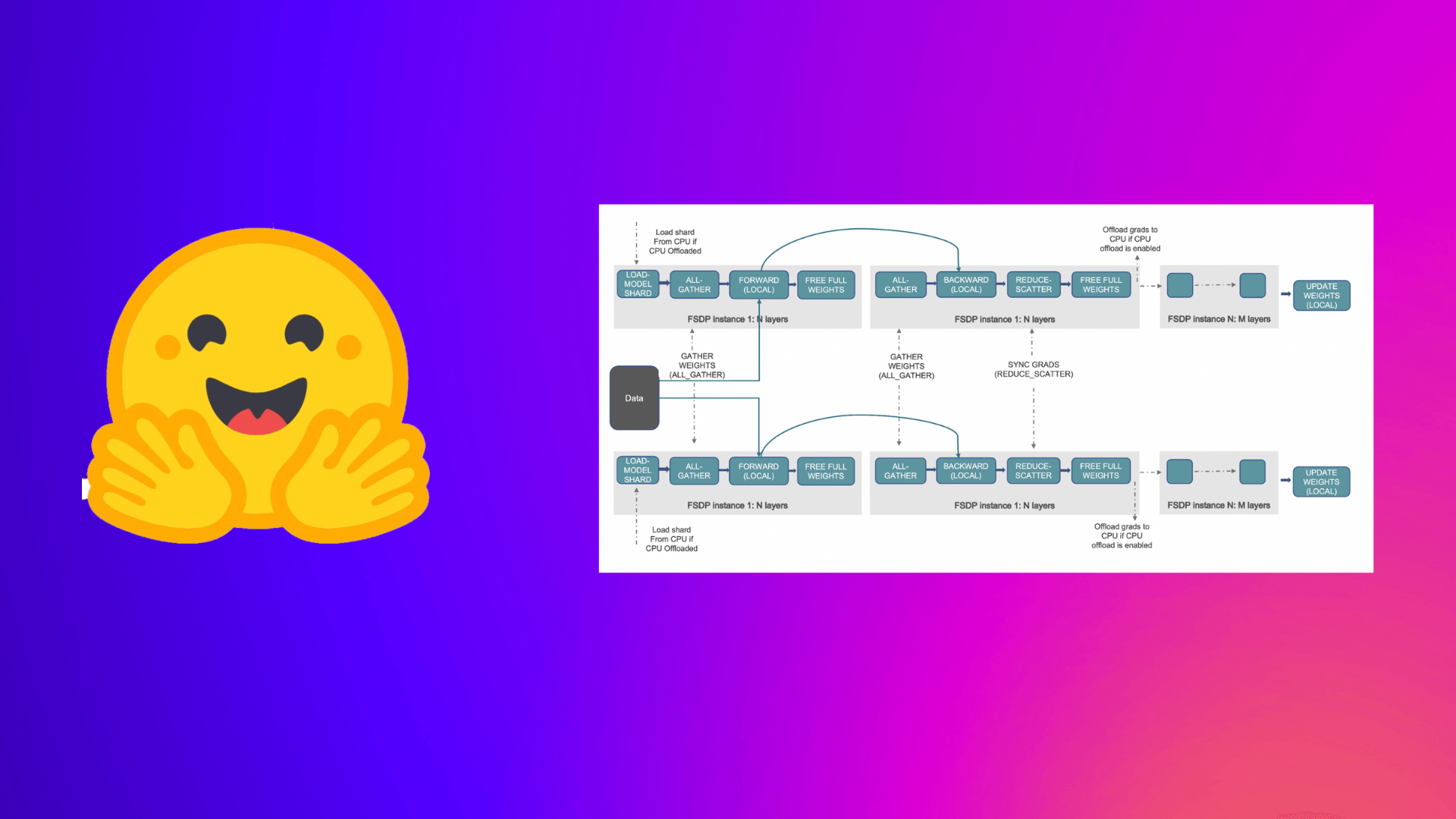
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.