Learn more about Search Results ランキング - Page 12

- You may be interested
- 「AI週間ニュース、2023年7月31日:」
- ギアアップしてゲームオン:ギアボックス...
- 「ChatGPT Visionのすごい活用方法」
- 「ディープマインドのアルファコードの力...
- Amazon AlexaのAI研究者がQUADRoを発表:Q...
- トレンドのAI GitHubリポジトリ:2023年11...
- 「大規模言語モデルにおける早期割れに打...
- 7月号 データサイエンティストのための気...
- Google AIは、MediaPipe Diffusionプラグ...
- 2023年にディープラーニングのためのマル...
- 「10ベストAI WhatsAppツール」
- 「ChatGPTのコピーライターへの影響:AIと...
- LangChainの発見:ドキュメントとのチャッ...
- 「AUCスコアの深い理解:何が重要なのか?」
- Amazon SageMaker JumpStartを使用した対...

「検索強化生成システムのパフォーマンスを向上させるための10の方法」
LLMは素晴らしい発明ですが、1つの重要な問題がありますそれは、彼らが事実とは異なる情報を作り出すことですRAGは、LLMにクエリに回答する際に事実の文脈を与えることで、より有用にしますクイックスタートガイドを使用して...

「LLMプロンプティングにおける思考の一端:構造化されたLLM推論の概要」
スマートフォンやスマートホームの時代に、単なる指示に従うだけでなく、私たちと同様に複雑な論理を扱い、実際に考えるAIを想像してみてくださいまるでSFのように聞こえますね…

物体検出リーダーボード
リーダーボードとモデルの評価の世界へようこそ。前回の投稿では、大規模言語モデルの評価について説明しました。今日は、異なるが同じくらい挑戦的な領域、つまり物体検出に乗り出します。 最近、オブジェクト検出のリーダーボードをリリースしました。このリーダーボードでは、ハブで利用可能な物体検出モデルをいくつかのメトリックに基づいてランキングしています。このブログでは、モデルの評価方法を実証し、物体検出で使用される一般的なメトリック、Intersection over Union (IoU)、Average Precision (AP)、Average Recall (AR)の謎を解き明かします。さらに重要なことは、評価中に発生する可能性のある相違点や落とし穴に焦点を当て、モデルのパフォーマンスを批判的に理解し評価できる知識を身につけることです。 すべての開発者や研究者は、正確に物体を検出し区別できるモデルを目指しています。私たちのオブジェクト検出リーダーボードは、彼らのアプリケーションのニーズに最も適したオープンソースモデルを見つけるための正しい場所です。しかし、「正確」とはこの文脈では本当に何を意味するのでしょうか?どのメトリックを信頼すべきでしょうか?それらはどのように計算されるのでしょうか?そして、さらに重要なことは、なぜいくつかのモデルが異なるレポートで相違した結果を示すことがあるのかということです。これらのすべての質問にこのブログで答えます。 では、一緒にこの探求の旅に乗り出し、オブジェクト検出リーダーボードの秘密を解き明かしましょう!もしも紹介を飛ばして、物体検出メトリックの計算方法を学びたい場合は、メトリックセクションに移動してください。オブジェクト検出リーダーボードを基に最良のモデルを選ぶ方法を知りたい場合は、オブジェクト検出リーダーボードセクションを確認してください。 目次 はじめに 物体検出とは メトリック 平均適合率(Average Precision)とは、どのように計算されるのか? 平均再現率(Average Recall)とは、どのように計算されるのか? 平均適合率と平均再現率のバリエーションとは? オブジェクト検出リーダーボード メトリックに基づいて最適なモデルを選ぶ方法は? 平均適合率の結果に影響を与えるパラメータは? 結論…

「人物再識別入門」
「人物再識別」は、異なる非重複カメラビューに現れる個人を識別するプロセスですこのプロセスは、顔認識に頼らずに、服装を考慮します...
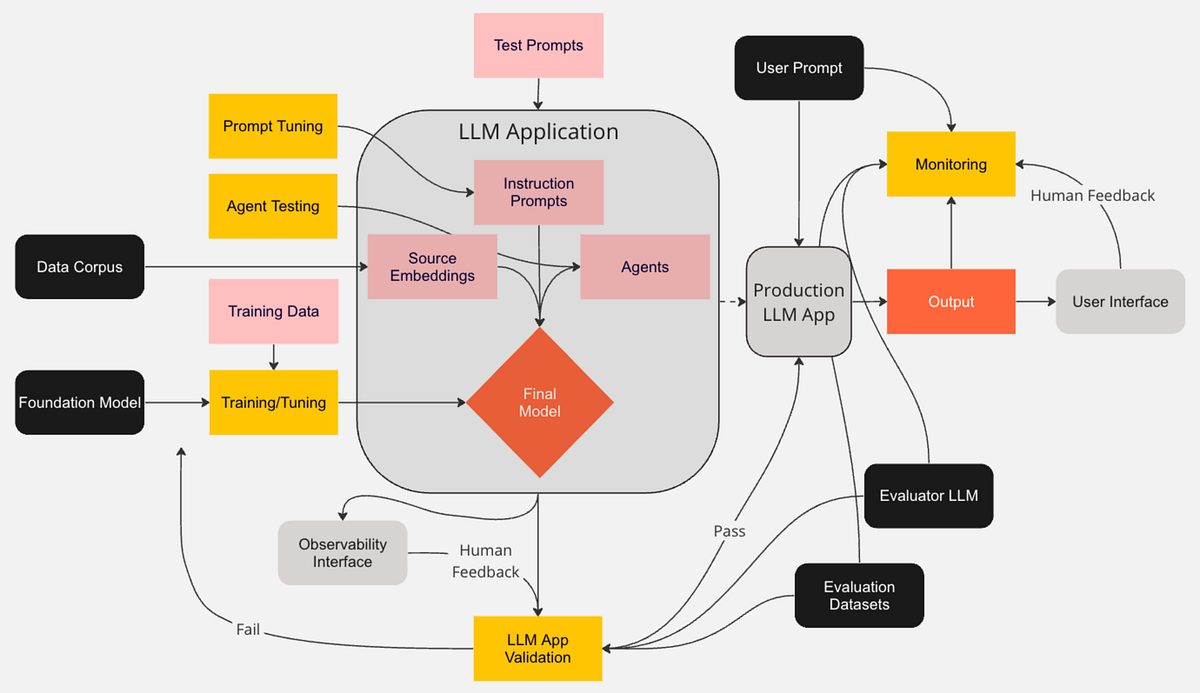
「LLMモニタリングと観測性 – 責任あるAIのための手法とアプローチの概要」
対象読者:実践者が利用可能なアプローチと実装の始め方を学びたい方、そして構築する際に可能性を理解したいリーダーたち…

ウェブサイトのためにChatGPTに適切なテクニカルテキストを書かせる方法
「長いテキストを書くように依頼しないでくださいできるだけ多くの詳細と仕様を提供し、適切な言語を使用し、AIディテクターでチェックしてください」

2023年にディープラーニングのためのマルチGPUシステムを構築する方法
「これは、予算内でディープラーニングのためのマルチGPUシステムを構築する方法についてのガイドです特に、コンピュータビジョンとLLMモデルに焦点を当てています」

Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
今日、生成型AIモデルはテキスト要約、Q&A、画像やビデオの生成など、さまざまなタスクをカバーしています出力の品質を向上させるために、n-短期学習、プロンプトエンジニアリング、検索補完生成(RAG)およびファインチューニングなどの手法が使用されていますファインチューニングにより、これらの生成型AIモデルを調整して、ドメイン固有の改善されたパフォーマンスを達成することができます

「LangChain、Activeloop、そしてGPT-4を使用して、Redditのソースコードをリバースエンジニアリングするための分かりやすいガイド」
この記事では、Redditのバージョン1のソースコードをリバースエンジニアリングして、その動作をより理解します

高性能意思決定のためのRLHF:戦略と最適化
はじめに 人間の要因/フィードバックからの強化学習(RLHF)は、RLの原則と人間のフィードバックを組み合わせた新興の分野です。これは、現実世界の複雑なシステムにおいて意思決定を最適化し、パフォーマンスを向上させるように設計されます。高性能のRLHFは、さまざまなドメインの設計、使いやすさ、安全性を向上させるために、人間の行動、認知、文脈、知識、相互作用を理解することに焦点を当てています。 RLHFは、機械中心の最適化と人間中心の設計のギャップを埋めるために、RLアルゴリズムと人間要因の原則を統合することを目指しています。研究者は、人間のニーズ、好み、能力に適応するインテリジェントシステムを作成し、ユーザーエクスペリエンスを最適化することを目指しています。RLHFでは、計算モデルが人間の反応をシミュレート、予測、予測し、個人が情報に基づいた意思決定を行い、複雑な環境との相互作用をどのように行うのかについての洞察を得ることができます。これらのモデルを強化学習アルゴリズムと組み合わせることを想像してみてください! RLHFは、意思決定プロセスを最適化し、システムのパフォーマンスを向上させ、今後数年間で人間と機械の協力を向上させることを目指しています。 学習目標 RLHFの基礎と人間中心の設計における重要性を理解することが最初で最も重要なステップです。 さまざまなドメインでの意思決定の最適化とパフォーマンスを向上させるためのRLHFの応用を探求します。 強化学習、人間要因工学、適応インターフェースなど、RLHFに関連する主要なトピックを特定します。 知識グラフがデータ統合とRLHFの研究および応用における洞察を促進する役割を認識します。 RLHF:人間中心のドメインを革新する 人間要因を活用した強化学習(RLHF)は、人間要因が重要なさまざまな分野を変革する可能性があります。人間の認知的制約、行動、相互作用の理解を活かして、個別のニーズに合わせた適応的なインターフェース、意思決定支援システム、支援技術を作成します。これにより、効率性、安全性、ユーザー満足度が向上し、業界全体での採用が促進されます。 RLHFの進化の中で、研究者は新しい応用を探求し、人間要因を強化学習アルゴリズムに統合する課題に取り組んでいます。計算モデル、データ駆動型アプローチ、人間中心の設計を組み合わせることで、RLHFは高度な人間と機械の協力、意思決定の最適化、パフォーマンスの向上を可能にしています。 なぜRLHFが重要なのか? RLHFは、ヘルスケア、金融、交通、ゲーム、ロボティクス、サプライチェーン、顧客サービスなど、さまざまな産業にとって非常に価値があります。 RLHFにより、AIシステムは人間の意図とニーズにより合わせて学習できるため、広範なアプリケーションでの快適で安全かつ効果的な使用が可能になります。 なぜRLHFが価値があるのか? 複雑な環境でのAIの活用はRLHFの得意とするところです。多くの産業では、AIシステムが運用する環境は通常複雑でモデル化が難しいです。一方、RLHFではAIシステムが人間の要因から学び、効率と精度の面で従来のアプローチが失敗する複雑なシナリオに適応することができます。 RLHFは責任あるAIの行動を促進し、人間の価値観、倫理、安全性に合わせることができます。これらのシステムへの継続的な人間のフィードバックは、望ましくない行動を防ぐのに役立ちます。一方、RLHFは人間の要因、判断、優先順位、好みを組み込むことで、エージェントの学習の旅をガイドする別の方法を提供します。 効率の向上とコストの削減知識グラフやAIシステムのトレーニングによる試行錯誤の必要性があります。特定のシナリオでは、両方ともダイナミックな状況で迅速に採用できます。 リアルタイム適応のためのRPAと自動化を可能にするほとんどの産業は既にRPAまたは一部の自動化システムを使用しており、AIエージェントが迅速に状況の変化に適応する必要があります。 RLHFはこれらのエージェントが人間のフィードバックを受けて即座に学習し、不確実な状況でもパフォーマンスと精度を向上させるのに役立ちます。私たちはこれを「意思決定インテリジェンスシステム」と呼んでいます。RDF(リソース開発フレームワーク)は同じシステムにセマンティックウェブ情報をもたらすことさえでき、情報に基づいた意思決定に役立ちます。 専門知識のデジタル化:すべての産業領域で専門知識は重要です。RLHFの助けを借りて、AIシステムは専門家の知識から学ぶことができます。同様に、知識グラフとRDFを使用すると、専門家のデモンストレーション、プロセス、問題解決の事実、判断能力からこの知識をデジタル化することができます。 RLHFは知識をエージェントに効果的に伝達することもできます。 ニーズに合わせたカスタマイズ:AIシステムは通常、ユーザーや専門家からのフィードバックを収集し、現実世界のシナリオで運用されるため、継続的な改善が必要です。フィードバックと意思決定に基づいてAIを継続的に改善することができます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.