Learn more about Search Results [3] - Page 12

- You may be interested
- ピクセルを説明的なラベルに変換する:Ten...
- ChatGPT の機能 観察、ヒント、およびトリ...
- トップ10の生成AI 3Dオブジェクトジェネレ...
- 拡散モデル:どのように拡散するのでしょ...
- Googleの研究者が新たな大規模言語モデル...
- 「データ分析での創発的AIの解放」
- 大規模言語モデルにおける文脈の長さの拡張
- DALLE-3の5つの使用例
- AIと機械学習のためのReactJS:強力な組み...
- ⚔️AI vs. AI⚔️は、深層強化学習マルチエー...
- スマートなメスは、医師が手術のスキルを...
- 「EU AI Actについて今日関心を持つべき理...
- オレゴン大学とアドビの研究者がCulturaX...
- この AI ペーパーでは、X-Raydar を発表し...
- MLモデルのトレーニングパイプラインの構...

「数字から行動へ:データを企業のために活用する」
「今日、組織や個人はデータに圧倒されています世界全体で1日あたり329百万テラバイトのデータが生成され、年間で合計120ゼタバイトも蓄積されています [1]しかし、それは一体何を意味しているのでしょうか...」
「PyTorchモデルのパフォーマンス分析と最適化 – パート3」
これは、PyTorch ProfilerとTensorBoardを使用してPyTorchモデルの分析と最適化を行うトピックに関するシリーズ投稿の3部目です私たちの意図は、...の利点を強調することでした
「探索的データ分析の改善のための実践的なヒント」
探索的データ分析(EDA)は、機械学習モデルを使用する前に必要なステップですEDAプロセスでは、データアナリストとデータサイエンティストにとって集中力と忍耐力が必要です:事前に…

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…

「ドメイン特化LLMの潜在能力の解放」
イントロダクション 大規模言語モデル(LLM)は世界を変えました。特にAIコミュニティにおいて、これは大きな進歩です。テキストを理解し、返信することができるシステムを構築することは、数年前には考えられなかったことでした。しかし、これらの機能は深さの欠如と引き換えに得られます。一般的なLLMは何でも屋ですが、どれも専門家ではありません。深さと精度が必要な領域では、幻覚のような欠陥は高価なものになる可能性があります。それは医学、金融、エンジニアリング、法律などのような領域がLLMの恩恵を受けることができないことを意味するのでしょうか?専門家たちは、既に同じ自己教師あり学習とRLHFという基礎的な技術を活用した、これらの領域に特化したLLMの構築を始めています。この記事では、領域特化のLLMとその能力について、より良い結果を生み出すことを探求します。 学習目標 技術的な詳細に入る前に、この記事の学習目標を概説しましょう: 大規模言語モデル(LLM)とその強みと利点について学びます。 一般的なLLMの制限についてさらに詳しく知ります。 領域特化のLLMとは何か、一般的なLLMの制限を解決するためにどのように役立つのかを見つけます。 法律、コード補完、金融、バイオ医学などの分野におけるパフォーマンスにおけるその利点を示すためのさまざまな領域特化言語モデルの構築について、例を交えて探求します。 この記事はData Science Blogathonの一部として公開されました。 LLMとは何ですか? 大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ人工知能システムであり、テキストを理解し生成するために構築されます。トレーニングでは、モデルにインターネットのテキスト、書籍、記事、ウェブサイトなどからの多数の文を提示し、マスクされた単語または文の続きを予測するように教えます。これにより、モデルはトレーニングされたテキストの統計パターンと言語的関係を学びます。LLMは、言語翻訳、テキスト要約、質問応答、コンテンツ生成など、さまざまなタスクに使用することができます。トランスフォーマーの発明以来、無数のLLMが構築され、公開されてきました。最近人気のあるLLMの例には、Chat GPT、GPT-4、LLAMA、およびStanford Alpacaなどがあり、画期的なパフォーマンスを達成しています。 LLMの強み LLMは、言語理解、エンティティ認識、言語生成の問題など、言語に関するさまざまな課題のためのソリューションとして選ばれるようになりました。GLUE、Super GLUE、SQuAD、BIGベンチマークなどの標準的な評価データセットでの優れたパフォーマンスは、この成果を反映しています。BERT、T5、GPT-3、PALM、GPT-4などが公開された時、それらはすべてこれらの標準テストで最新の結果を示しました。GPT-4は、BARやSATのスコアで平均的な人間よりも高得点を獲得しました。以下の図1は、大規模言語モデルの登場以来、GLUEベンチマークでの大幅な改善を示しています。 大規模言語モデルのもう一つの大きな利点は、改良された多言語対応の能力です。たとえば、104の言語でトレーニングされたマルチリンガルBERTモデルは、さまざまな言語で優れたゼロショットおよびフューショットの結果を示しています。さらに、LLMの活用コストは比較的低くなっています。プロンプトデザインやプロンプトチューニングなどの低コストの方法が登場し、エンジニアはわずかなコストで既存のLLMを簡単に活用することができます。そのため、大規模言語モデルは、言語理解、エンティティ認識、翻訳などの言語に基づくタスクにおけるデフォルトの選択肢となっています。 一般的なLLMの制限 Web、書籍、Wikipediaなどからのさまざまなテキストリソースでトレーニングされた上記のような一般的なLLMは、一般的なLLMと呼ばれています。これらのLLMには、Bing ChatのGPT-4、PALMのBARDなどの検索アシスタント、マーケティングメール、マーケティングコンテンツ、セールスピッチなどのコンテンツ生成タスク、個人チャットボット、カスタマーサービスチャットボットなど、さまざまなアプリケーションがあります。 一般的なAIモデルは、さまざまなトピックにわたるテキストの理解と生成において優れたスキルを示していますが、専門分野にはさらなる深さとニュアンスが必要な場合があります。たとえば、「債券」とは金融業界での借入の形態ですが、一般的な言語モデルはこの独特なフレーズを理解せず、化学や人間同士の債券と混同してしまうかもしれません。一方、領域特化のLLMは、特定のユースケースに関連する専門用語を専門的に理解し、業界固有のアイデアを適切に解釈する能力があります。 また、一般的なLLMには複数のプライバシーの課題があります。たとえば、医療LLMの場合、患者データは非常に重要であり、一般的なLLMに機械学習強化学習(RLHF)などの技術が使用されることで、機密データの公開がプライバシー契約に違反する可能性があります。一方、特定のドメインに特化したLLMは、データの漏洩を防ぐために閉じたフレームワークを確保します。…

パンダのコピー・オン・ライトモードの詳細な調査:パートI
「pandas 2.0 は4月初旬にリリースされ、新しいCopy-on-Write (CoW) モードに多くの改善がもたらされましたこの機能は、予定されている pandas 3.0 でデフォルトになることが期待されています」
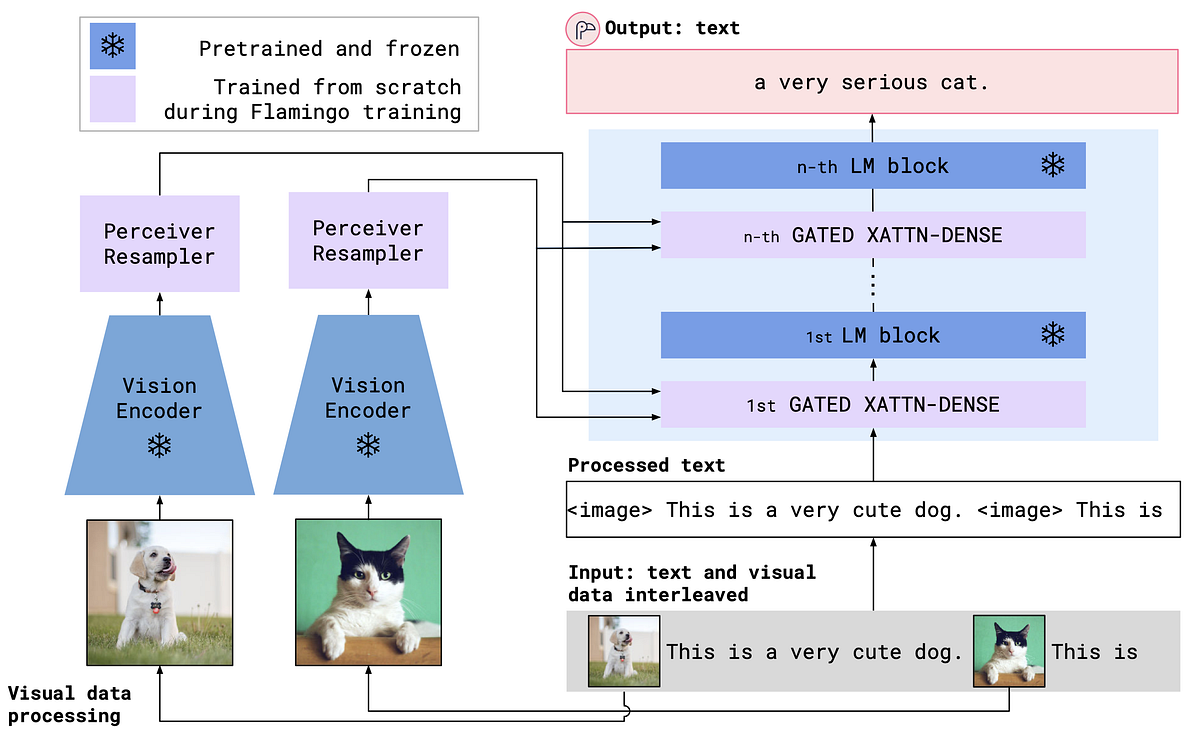
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」

「Amazon SageMakerに展開された生成AIを使用して創造的な広告を生成する」
創造的な広告は、生成AI(GenAI)によって革命を起こす可能性がありますGenAIモデルを再トレーニングし、テキストのプロンプト(シーンやモデルによって生成されるオブジェクトを説明する文)など、モデルにいくつかの入力を提供することで、製品写真などの新しい画像の幅広いバリエーションを作成できるようになりました
「HaystackにおけるRAGパイプラインの拡張 DiversityRankerとLostInTheMiddleRankerの紹介」
最近の自然言語処理(NLP)と長文質問応答(LFQA)の進歩は、わずか数年前にはまるでSFの世界から来たようなものだと思われていたでしょう誰...

「生成AIの規制」
生成型の人工知能(AI)が注目を集める中、この技術を規制する必要性が高まっていますなぜなら、この技術は大規模な人口に対して迅速に負の影響を与える可能性があるからです影響は以下のようなものが考えられます...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.