Learn more about Search Results GitHub - Page 129

- You may be interested
- ジェン AI for the Genome LLM は COVID ...
- カスタムデータセットのセグメンテーショ...
- 「SIEM-SOAR インテグレーションによる次...
- Amazon SageMakerを使用して、オーバーヘ...
- 「技術的な視点からのGoogleの最強のマル...
- DeepMind RoboCat:自己学習ロボットAIモデル
- 「大規模なコンピュートプロジェクトにお...
- 「初めに、AWS上でMONAI Deployを使用して...
- ヘルスケアの革新:医学における大規模言...
- スタンフォード大学の研究者たちは、MLAge...
- 「データ可視化での色の使い方」
- 「ゼロからの実験オーケストレーション」
- ReLoRa GPU上で大規模な言語モデルを事前...
- Hugging Face Hubへようこそ、Stable-base...
- ミストラル7B:コンピューターでの微調整...
データサイエンスにおけるキャリアキャピタルを構築するために非常に過小評価されている方法
もちろん、LinkedInはプロフェッショナルなネットワークを構築するための素晴らしい方法であり、ポートフォリオはあなたが行った素晴らしい仕事を紹介するための素晴らしい方法ですしかし、もし誰もあなたのポートフォリオのリンクをクリックしない場合や、あなたがポートフォリオを持っていない場合、

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...

あなたが作るものはあなたそのものです:コードをより人間的にする方法
GitHubのクリスティーナ・エンチェヴタさんが、AIアプリケーションが私たちの価値観を反映していることや、建設的なフィードバックの提供方法などについて話します

Langchainを使用してYouTube動画用のChatGPTを構築する
はじめに ビデオとチャットで話すことができたらどのくらい便利だろうかと考えたことがありますか?私自身、ブログを書く人間として、関連する情報を見つけるために1時間ものビデオを見ることはしばしば退屈に感じます。ビデオから有用な情報を得るために、ビデオを見ることが仕事のように感じることもあります。そこで、YouTubeビデオやその他のビデオとチャットできるチャットボットを作成しました。これは、GPT-3.5-turbo、Langchain、ChromaDB、Whisper、およびGradioによって実現されました。この記事では、Langchainを使用してYouTubeビデオのための機能的なチャットボットを構築するコードの解説を行います。 学習目標 Gradioを使用してWebインターフェースを構築する Whisperを使用してYouTubeビデオを処理し、テキストデータを抽出する テキストデータを適切に処理およびフォーマットする テキストデータの埋め込みを作成する Chroma DBを構成してデータを保存する OpenAI chatGPT、ChromaDB、および埋め込み機能を使用してLangchainの会話チェーンを初期化する 最後に、Gradioチャットボットに対するクエリとストリーミング回答を行う コーディングの部分に入る前に、使用するツールや技術に慣れておきましょう。 この記事は、Data Science Blogathonの一部として公開されました。 Langchain Langchainは、Pythonで書かれたオープンソースのツールで、Large Language Modelsデータに対応したエージェントを作成できます。では、それはどういうことでしょうか?GPT-3.5やGPT-4など、商用で利用可能な大規模言語モデルのほとんどは、トレーニングされたデータに制限があります。たとえば、ChatGPTは、すでに見た質問にしか答えることができません。2021年9月以降のものは不明です。これがLangchainが解決する核心的な問題です。Wordドキュメントや個人用PDFなど、どのデータでもLLMに送信して人間らしい回答を得ることができます。ベクトルDB、チャットモデル、および埋め込み関数などのツールにはラッパーがあり、Langchainだけを使用してAIアプリケーションを簡単に構築できます。 Langchainを使用すると、エージェント(LLMボット)を構築することもできます。これらの自律エージェントは、データ分析、SQLクエリ、基本的なコードの記述など、複数のタスクに設定できます。これらのエージェントを使用することで、低レベルな知識作業をLLMに外注することができるため、時間とエネルギーを節約できます。 このプロジェクトでは、Langchainツールを使用して、ビデオ用のチャットアプリを構築します。Langchainに関する詳細については、公式サイトを訪問してください。 Whisper Whisperは、OpenAIの別の製品です。これは、オーディオまたはビデオをテキストに変換できる汎用音声認識モデルです。多言語翻訳、音声認識、および分類を実行するために、多様なオーディオをトレーニングしています。…
ヒッティングタイム予測:時系列確率予測の別の方法
正確な予測をする能力は、すべての時系列予測アプリケーションにとって基本的なものですこの目的に従って、データサイエンティストたちは、最小化する最適なモデルを選択することに慣れています...

Twitterの後
問題を抱えたTwitterに挑戦するために、新しいソーシャルアプリが現れている

テーブル内の重複した値を見つけるための最高のSQLトリック2つ
まず、重複行の基準を定義してくださいテーブルから重複レコードを見つける方法の一つは、GROUP BYとHAVINGですもう一つの方法はROW_NUMBER()です詳細はこちらをご覧ください
Cox回帰の隠されたダークシークレット:Coxを解きほぐす
もし以前のブログ投稿をフォローしていた場合、ロジスティック回帰が完全に分離されたデータにフィットしようとすると問題が発生し、オッズ比が無限大になることを思い出すかもしれません
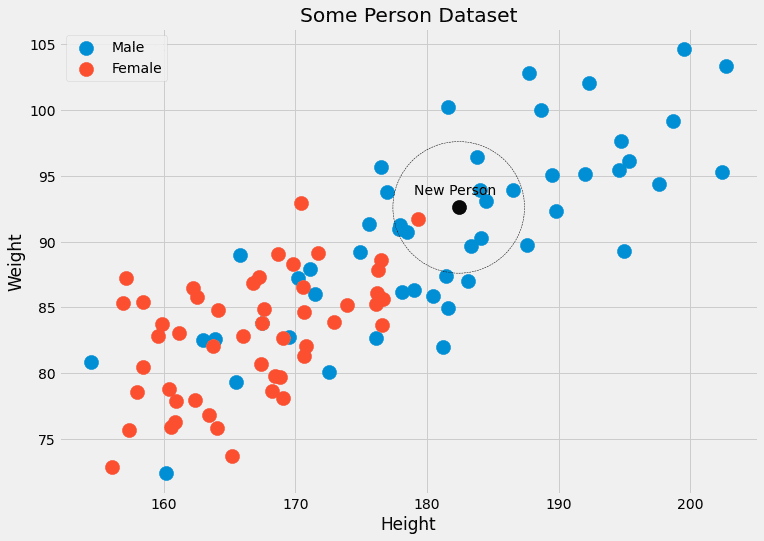
理論から実践へ:k最近傍法分類器の構築
k-最近傍法分類器は、新しいデータポイントを、k個の最も近い隣人の中で最も一般的なクラスに割り当てる機械学習アルゴリズムですこのチュートリアルでは、Pythonでこの分類器を構築および適用する基本的な手順を学びます
Pandas 2.0 データサイエンティストにとってのゲームチェンジャー?
Pandas 2.0の効率的なデータ操作を可能にするトップ5の機能を活用する方法を学び、データサイエンススキルを次のレベルに引き上げましょう!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.