Learn more about Search Results GitHub - Page 124

- You may be interested
- 「ジェネレーティブAIがビジネス、健康医...
- 「深層学習モデルの可視化方法」
- 3日間でAIアプリを作成しました
- 「アマゾン対Google対マイクロソフト:AI...
- 政府の腐敗を出し抜くためのAIの積極的な役割
- 「データエンジニアリングの役割に疲れま...
- 「ラスティックデータ:Plottersを使用し...
- ジェネラティブAIとプロンプトエンジニア...
- 裁判官がChatGPTを法的判決に使用すること...
- このAI研究は「Kosmos-G」という人工知能...
- 「PDFドキュメントを使用したオブジェクト...
- ジャクソン・ジュエットは、より少ないコ...
- 「LangChainとOpenAI APIを使用した生成型...
- Windows上のAnacondaでPythonの依存関係の...
- 「トップAIランダム顔生成アプリ(2023年)」

このAI論文は、DreamDiffusionという「脳のEEG信号から直接高品質の画像を生成するための思考イメージモデル」を紹介しています
脳活動から画像を生成する能力は、特にテキストから画像生成のブレイクスルーにより、近年著しい進歩を遂げています。しかし、脳の脳波(EEG)信号を使用して思考を直接画像に翻訳することは、興味深い課題です。DreamDiffusionは、事前にトレーニングされたテキストから画像の拡散モデルを利用して、EEG信号だけから現実的で高品質な画像を生成するためにこのギャップを埋めることを目指しています。この手法は、EEG信号の時間的側面を探求し、ノイズやデータの限定に対処し、EEG、テキスト、画像の空間を整列させることを目指しています。DreamDiffusionは、効率的な芸術的創造、夢の視覚化、自閉症や言語障害を持つ人々に対する潜在的な治療的応用の可能性を開拓します。 過去の研究では、機能的磁気共鳴画像法(fMRI)やEEG信号などの脳活動から画像を生成する手法が探求されてきました。fMRIベースの手法は高価で非携帯性のある装置が必要ですが、EEG信号はよりアクセスしやすく低コストな代替手段を提供します。DreamDiffusionは、MinD-Visなどの既存のfMRIベースの手法を活用し、事前にトレーニングされたテキストから画像の拡散モデルの力を利用しています。DreamDiffusionは、EEG信号固有の課題に対処するため、マスクされた信号モデリングを使用してEEGエンコーダを事前にトレーニングし、EEG、テキスト、画像の空間を整列させるためにCLIP画像エンコーダを利用します。 DreamDiffusionの方法は、マスクされた信号の事前トレーニング、事前トレーニングされたスタブル拡散を使用した制約付きEEG-画像ペアの微調整、CLIPエンコーダを使用したEEG、テキスト、画像の空間の整列の3つの主要なコンポーネントで構成されています。マスクされた信号モデリングは、コンテキストの手がかりに基づいてマスクされたトークンを再構築することにより、効果的かつ堅牢なEEG表現を可能にするために使用されます。CLIP画像エンコーダは、EEG埋め込みをさらに洗練し、それらをCLIPテキストと画像の埋め込みと整列させるために組み込まれます。結果として得られるEEG埋め込みは、品質が向上した画像生成に使用されます。 DreamDiffusionの制約事項 DreamDiffusionは、その驚異的な成果にもかかわらず、認識すべき制約事項があります。主な制約事項の1つは、EEGデータがカテゴリレベルでしか粗い情報を提供しないことです。いくつかの失敗例では、形状や色が似た他のカテゴリに特定のカテゴリがマッピングされたことが示されました。この不一致は、人間の脳が物体認識において形状と色を重要な要素として考慮していることに起因する可能性があります。 これらの制約にもかかわらず、DreamDiffusionは神経科学、心理学、人間とコンピュータの相互作用の様々な応用において重要な潜在能力を持っています。EEG信号から直接高品質の画像を生成する能力は、これらの分野での研究と実用化の新たな可能性を開拓します。さらなる進展により、DreamDiffusionは制約を克服し、幅広い学際的な領域に貢献することができます。研究者や愛好家は、GitHub上でDreamDiffusionのソースコードにアクセスできるため、この興味深い分野でのさらなる探求と開発を支援します。

人材分析のための R ツールキット:ヘッドカウントのストーリーを伝える
人事分析の仕事では、会社の従業員数や会社が今日のように進化する過程を伝えることが求められることがよくあります私はしばしばこれをウォーターフォールチャートとして提示されるのを見ますが、それは...

クレジットカードの取引データを使用した顧客セグメンテーションのマスタリング
顧客セグメンテーションとは、過去の購買パターンに基づいて顧客セグメントを特定するプロセスですたとえば、リピート/ロイヤル顧客、高額な顧客の特定などを含むことがあります

トロント大学の研究者たちは、3300万以上の細胞リポジトリ上で生成事前学習トランスフォーマーに基づいたシングルセル生物学のための基礎モデルであるscGPTを紹介しました
自然言語処理とコンピュータビジョンは、生成学習済みモデルが驚異的に成功した分野の例の一部です。特に、基盤モデルを構築するための実行可能な戦略は、様々な大規模データセットを事前学習されたトランスフォーマーと組み合わせることです。この研究では、言語と生物構造(テキストが遺伝子を構成し、それぞれ単語と細胞を特徴付ける)の関連性を引き出すことで、基盤モデルが細胞生物学と遺伝学のさらなる研究を促進する可能性を調査しています。研究者たちは、シングルセル配列データの増加するデータベースを横断する生成学習済みトランスフォーマーに基づくシングルセル生物学のための基盤モデルであるscGPTを構築する最前線にいます。結果は、事前学習された生成トランスフォーマーであるscGPTが、遺伝子と細胞に関連する重要な生物学的洞察を効率的に抽出することを示しています。転移学習を新たな方法で使用することで、スクリプトはさまざまなアプリケーションで改善することができます。これらの課題には、遺伝子ネットワークの推論、遺伝子の変異予測、およびマルチバッチ統合が含まれます。scGPTのソースコードを表示する。 一つ一つの細胞の詳細な特性を容易にし、疾患の発症機序の理解、特異的な細胞系譜の追跡、病原性の解明、および患者固有の治療アプローチの開発に貢献するシングルセルRNAシーケンシング(scRNA-seq)は、細胞性の異質性の調査、系譜の追跡、病原性の解明、および患者固有の治療アプローチの開発への道を切り拓きます。 シーケンシングデータの指数関数的な増加を考慮すると、これらの新しいトレンドを効果的に活用し、適応する方法を作成することが急務です。基盤モデルの生成学習は、この困難を克服するための効果的な戦略です。大規模なデータセットから学習する生成学習は、最近さまざまなドメインで驚異的な成功を収めています。人気のある用途には、自然言語生成(NLG)とコンピュータビジョンがあります。これらのベースラインモデルには、DALL-E2やGPT-4などがあります。これらは大規模な異種データセットでトランスフォーマーを事前学習し、特定の下流タスクとシナリオに簡単に適応できるという原則に基づいています。さらに、これらの事前学習された生成モデルは常にカスタムトレーニングされたモデルよりも優れた性能を発揮します。 研究者たちは、NLGの自己教師あり事前学習手法からヒントを得て、大量のシングルセルシーケンシングデータのモデリングを改善しています。自己注意トランスフォーマーは、テキストの入力トークンをモデリングするための有用で効率的なフレームワークであることが証明されています。 100万以上の細胞で生成学習を行うことにより、これらの科学者たちは、シングルセル基盤モデルであるscGPTを構築する初めての試みを提供しています。彼らは、方法論とエンジニアリングの問題の両方に対処し、大量のシングルセルオミックスデータの事前学習を行うための新しいアプローチを示しています。彼らは、数百のデータセットを格納するためのクイックアクセスを持つインメモリデータ構造を使用して、大量のデータに対処することができます。彼らはトランスフォーマーアーキテクチャを修正して、細胞と遺伝子の表現を同時に学習し、非順序のオミックスデータに適した統一された生成学習アプローチを構築します。また、事前学習モデルをさまざまな下流タスクで使用できるようにするために、モデルの微調整用にタスク固有の目的を持つ標準パイプラインも提供します。 これらの3つのコンポーネントを通じて、scGPTモデルはシングルセル基盤コンセプトの革新的なポテンシャルを示しています。それは、scGPTから始まる、さまざまな下流活動への転移学習をサポートする最初の大規模な生成基盤モデルです。彼らは、細胞型注釈、遺伝子変異予測、バッチ補正、およびマルチオミックス統合において最先端のパフォーマンスを達成することで、シングルセルオミクスの計算アプリケーションに対する「普遍的な事前学習、オンデマンドでの微調整」アプローチの有効性を実証しています。 特に、scGPTはscATAC-seqデータや他のシングルセルオミクスを組み込むことができる唯一のベースモデルです。第二に、scGPTは、洗練されたモデルと生の事前学習モデルの遺伝子の埋め込みと注意の重みを比較することで、特定の条件下での遺伝子間相互作用に関する重要な生物学的洞察を明らかにします。第三に、結果はスケーリングの法則を示しており、事前学習フェーズでより多くのデータを使用することにより、より良い事前学習埋め込みとより高い下流タスクのパフォーマンスが得られます。この発見は、基盤モデルが研究コミュニティに利用可能なシーケンシングデータがますます利用可能になるにつれて着実に改善する可能性を強調しています。これらの結果を踏まえて、彼らは、事前学習された基盤モデルを使用することで細胞生物学の知識を大幅に増やし、この分野の将来の進歩の基礎を築くことができるという仮説を立てています。scGPTモデルとワークフローを一般に公開することで、これらおよび関連する分野の研究が強化され、加速されます。 このスクリプトは、研究者によって説明されたように、大量のシングルセルデータを理解するために事前学習されたトランスフォーマーを使用する新しい生成学習済み基盤モデルです。chatGPTやGPT4などの言語モデルで、自己教師あり事前学習が効果的であることが証明されています。シングルセルの研究では、彼らは同じ戦略を使って複雑な生物学的な関係を解読しました。細胞の異なる側面をよりよくモデリングするために、scGPTはトランスフォーマーを使用して遺伝子と細胞の埋め込みを同時に学習します。シングルセルGPT(scGPT)は、トランスフォーマーの注意機構を使用して、シングルセルレベルでの遺伝子間相互作用を捉え、新しい解釈可能性の次元を追加します。 研究者は、ゼロショットとファインチューニングのシナリオでの包括的な研究を行い、事前トレーニングの価値を証明しました。訓練されたモデルは、任意のデータセットの特徴抽出器として既に機能します。ゼロショットの研究では、顕著な細胞塊が表示される印象的な外挿能力が示されました。さらに、scGPTの学習済み遺伝子ネットワークと以前に確立された機能関係の間には高い一致度があります。私たちは、遺伝子間相互作用を捉え、既知の生物学的情報を効果的に反映するモデルの適切な発見能力を信じています。また、いくつかのファインチューニングを行うことで、事前トレーニングされたモデルによって学習された情報をさまざまな後続タスクに活用することができます。最適化されたscGPTモデルは、セルタイプの注釈、マルチバッチ、マルチオミック統合といったタスクで、スクラッチからトレーニングされたモデルを定期的に上回ります。これにより、事前トレーニングされたモデルが精度と生物学的関連性を向上させることで、後続タスクへの利益が示されます。全体的に、テストはscGPTの事前トレーニングの有用性を示し、一般化能力、遺伝子ネットワークの把握、転移学習を活用した後続タスクの性能向上の能力を示しています。 主な特徴 ジェネラリスト戦略により、シングルセル研究において統合されたマルチオミック解析とパーティクル予測を単一のモデルで実行することができます。 学習済みの注意重みと遺伝子埋め込みを使用して、特定の条件下での遺伝子間相互作用を特定することができます。 データ量の増加とともにモデルの性能が持続的に向上するスケーリング則を特定しました。 scGPTモデルゾーには、さまざまな実質的な臓器用の多くの事前トレーニング済み基礎モデル(GitHub参照)と包括的なパンガンサーモデルがあります。最適な出発点モデルを使用してデータを探索を開始してください。 事前トレーニングは、マルチオミックデータ、空間オミックス、さまざまな疾患状態を含むより大規模なデータセットで行われることが期待されています。モデルは、パーティクルと時間軸データが事前トレーニングフェーズに含まれる場合、因果関係を学習し、遺伝子や細胞が時間経過に応答する方法を推定することができます。事前トレーニングモデルの学習内容をより理解し解釈するためには、広範な生物学的に有意なタスクでモデルを検証することが理想的です。さらに、単一細胞データのための文脈に関する知識を調査することを目指しています。事前トレーニングされたモデルは、ゼロショット構成で追加のファインチューニングなしで新しいジョブや環境に適応する必要があります。さまざまな研究の微妙さとユニークなニーズを理解するように教育することで、scGPTの有用性と適用範囲を多くの研究コンテキストで向上させることができます。事前トレーニングパラダイムは、シングルセル研究で容易に実装できると期待されており、急速に拡大するセルアトラスの蓄積された知識を活用するための基盤を築くものとなるでしょう。
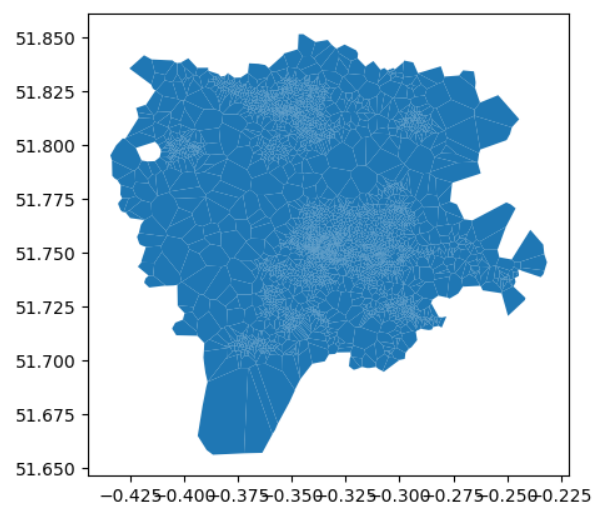
郵便番号レベルでの地理空間データの操作
一部の国では、郵便番号は地域ではなく、ポイントやルートで表されます例えば、カナダの郵便番号の最後の3桁は、地域配送ユニットに対応していて、それは一つの家に対応するかもしれません...
PolarsによるEDA:Pandasユーザーのためのステップバイステップガイド(パート1)
時折、データ解析のやり方を大きく変えるツールが現れます私はPolarsがそのようなツールの一つであると信じていますので、このシリーズの記事では、詳しく掘り下げて説明します
AWSとPower BIを使用して、米国のフライトを調査する
∘ 問題の説明 ∘ データ ∘ AWSアーキテクチャ ∘ AWS S3を使ったデータストレージ ∘ スキーマの設計 ∘ AWS Glueを使ったETL ∘ AWS Redshiftを使ったデータウェアハウジング ∘ インサイトの抽出...

Amazon SageMaker Jumpstartを使用して、車両フリートの故障確率を予測します
予測保全は自動車産業において重要ですなぜなら、突発的な機械故障や運用を妨げる事後処理の活動を回避することができるからです車両の故障を予測し、メンテナンスや修理のスケジュールを立てることにより、ダウンタイムを減少させ、安全性を向上させ、生産性を向上させることができますもし、車両の故障を引き起こす一般的な領域にディープラーニングの技術を適用できたら、どうでしょうか

Amazon Pollyを使用してテキストが話されている間にテキストをハイライト表示します
Amazon Pollyは、テキストを生き生きとした音声に変換するサービスですこのサービスは、テキストを複数の言語に音声に変換するアプリケーションの開発を可能にしますこのサービスは、他のAWS AIや機械学習(ML)サービスと組み合わせて、チャットボットやオーディオブックなどのテキスト読み上げアプリケーションで使用することができます[…]

2023年の最高の人工知能(AI)ニュースレター
人工知能(AI)分野では、AIの進展について情報を得て先を見るために、様々なAIニュースレターが登場しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.