Learn more about Search Results documentation - Page 11

- You may be interested
- ポッドキャストのアクセシビリティを向上...
- 「AIバイアス&文化的なステレオタイプ:...
- MetaがEmuビデオとEmu編集を発表:テキス...
- ヘリオットワット大学とAlana AIの研究者...
- 「ユナイテッド航空がコスト効率の高い光...
- 「DifFaceに会ってください:盲目の顔の修...
- 「OWLv2のご紹介:ゼロショット物体検出に...
- 「世界最大の広告主がAIの力を受け入れる...
- ジェンAIの活用:攻撃型AIに対するサイバ...
- なぜプロンプトエンジニアリングは一時的...
- 50以上の機械学習面接(インタビュアーと...
- 「おそらく知らなかった4つのPython Itert...
- 「LLMモニタリングと観測性 – 責任...
- 「生データから洗練されたデータへ:デー...
- NumpyとPandasを超えて:知られざるPython...

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…
Amazon SageMakerを使用して、Hugging Faceモデルを簡単にデプロイできます
今年早くも、Hugging FaceをAmazon SageMakerで利用しやすくするためにAmazonとの戦略的な協力を発表し、最先端の機械学習機能をより速く提供することを目指しています。新しいHugging Face Deep Learning Containers (DLCs)を導入し、Amazon SageMakerでHugging Face Transformerモデルをトレーニングすることができます。 今日は、Amazon SageMakerでHugging Face Transformersを展開するための新しい推論ソリューションを紹介します!新しいHugging Face Inference DLCsを使用すると、トレーニング済みモデルをわずか1行のコードで展開できます。また、Model Hubから10,000以上の公開モデルを選択し、Amazon SageMakerで展開することもできます。 SageMakerでモデルを展開することで、AWS環境内で簡単にスケーリング可能な本番用エンドポイントが提供されます。モニタリング機能やエンタープライズ向けの機能も組み込まれています。この素晴らしい協力を活用していただければ幸いです! 以下は、新しいSageMaker Hugging Face…
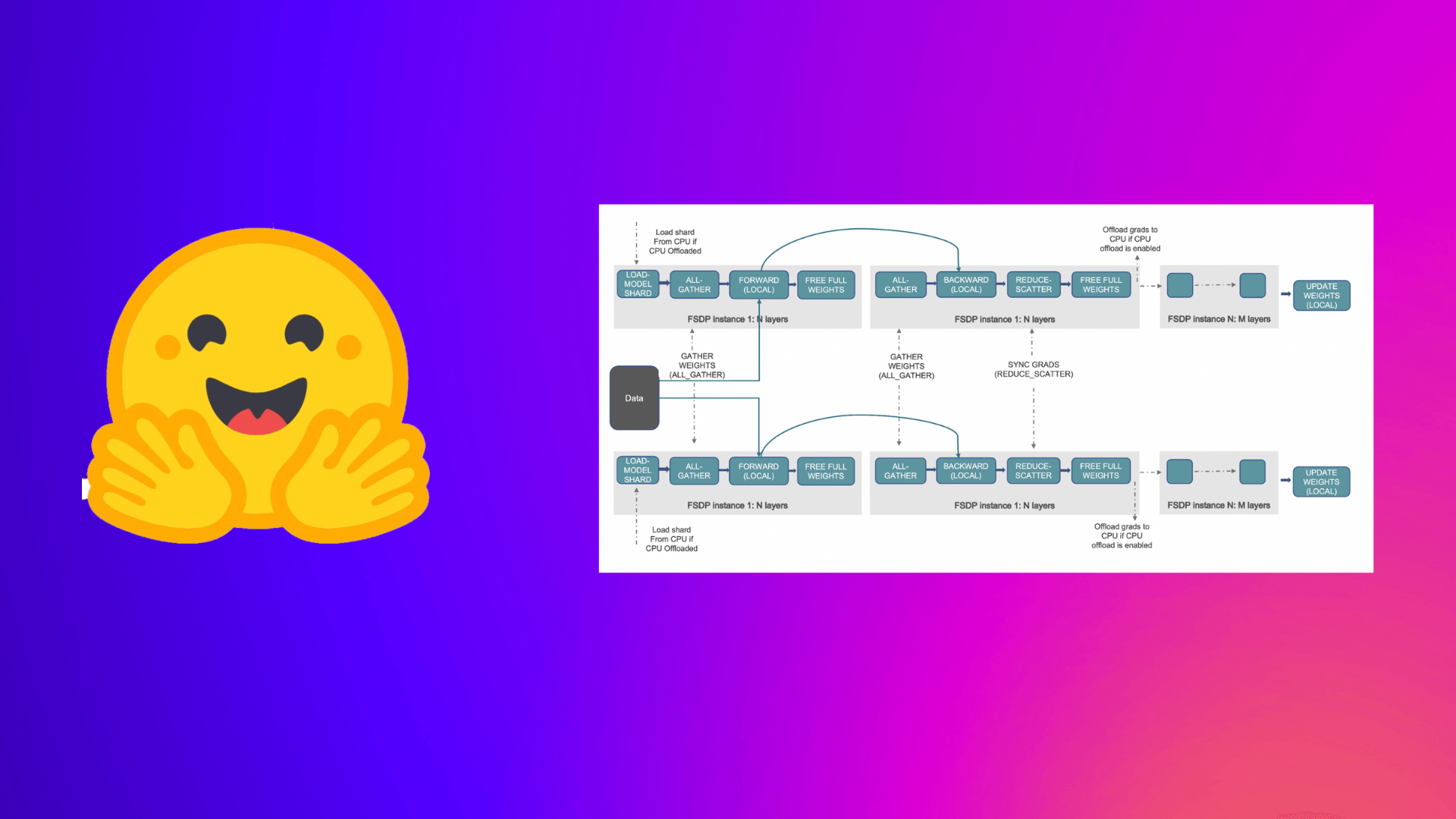
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

Diffusersを使用したDreamboothによる安定した拡散のトレーニング
ドリームブースは、特殊なファインチューニングの形式を使用して、安定拡散に新しい概念を教えるための技術です。一部の人々は、素晴らしい状況に自分自身を配置するために、いくつかの写真を使用してそれを利用しています。一方、他の人々は新しいスタイルを取り入れるためにそれを使用しています。🧨 Diffusersは、Dreamboothトレーニングスクリプトを提供しています。トレーニングには時間はかかりませんが、適切なハイパーパラメータのセットを選択するのは難しく、過学習しやすいです。 私たちは、Dreamboothのさまざまな設定の効果を分析するために多くの実験を行いました。この投稿では、Stable DiffusionをDreamboothでファインチューニングする際に結果を改善するための見つけたポイントといくつかのヒントを紹介します。 始める前に、この方法は決して悪意のある目的、何らかの害を引き起こすため、または人々を知らずになりすますために使用してはなりません。それでトレーニングされたモデルは、Stable Diffusionモデルの配布を規制するCreativeML Open RAIL-Mライセンスによって依然として拘束されます。 注意:この投稿の以前のバージョンはW&Bレポートとして公開されました。 要約:推奨設定 ドリームブースはすぐに過学習します。良質な画像を得るためには、トレーニングステップ数と学習率の間の「適切なスイートスポット」を見つける必要があります。低い学習率を使用し、結果が満足できるまでステップ数を徐々に増やすことを推奨します。 ドリームブースでは、顔に対してはより多くのトレーニングステップが必要です。私たちの実験では、バッチサイズ2とLR 1e-6を使用した場合に、800〜1200ステップがうまく機能しました。 事前保存は、顔のトレーニング時に過学習を避けるために重要です。他の対象に対しては、それほど大きな違いはないようです。 生成された画像がノイズが多いか品質が低下している場合、それはおそらく過学習を意味します。まず、上記の手順を試して避けてみてください。生成された画像がまだノイズが多い場合は、DDIMスケジューラを使用するか、より多くの推論ステップ(私たちの実験では約100ステップがうまく機能しました)を実行してみてください。 UNetに加えてテキストエンコーダをファインチューニングすることは、品質に大きな影響を与えます。私たちの最良の結果は、テキストエンコーダのファインチューニング、低いLR、適切なステップ数の組み合わせを使用して得られました。ただし、テキストエンコーダのファインチューニングにはより多くのメモリが必要ですので、少なくとも24 GBのRAMを持つGPUが理想です。Google ColabやKaggleが提供する16 GBのGPUのようなものでは、8ビットAdam、fp16トレーニング、勾配蓄積などの技術を使用してトレーニングすることが可能です。 EMAを使用してファインチューニングするかどうかに関係なく、類似の結果が得られました。 ドリームブースをトレーニングするためにsksという単語を使用する必要はありません。最初の実装の一部は、それが語彙の中で稀なトークンであったためにそれを使用しましたが、実際にはライフルの一種です。私たちの実験および@nitrosockeなどの実験は、ターゲットを説明するために自然に使用する用語を選択しても問題ないことを示しています。 学習率の影響 ドリームブースは非常に速く過学習します。良い結果を得るためには、データセットに合理的な学習率とトレーニングステップ数を調整します。私たちの実験(以下で詳細に説明)では、高い学習率と低い学習率で4つの異なるデータセットでファインチューニングを行いました。すべての場合で、低い学習率でより良い結果が得られました。 実験設定…
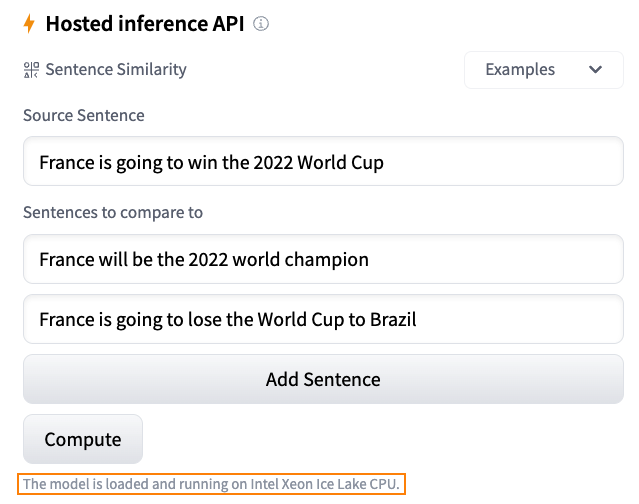
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.