Learn more about Search Results arXiv - Page 11

- You may be interested
- 「サンフランシスコ大学データサイエンス...
- 「ODSC West 2023に登場する10のトレンデ...
- アリババは、2つのオープンソースの大規模...
- 生成AIの責任ある使用の緊急性
- 「驚くほど速い、コード不要のPython Foli...
- あなたの言語モデルやAPIを活用するための...
- ドクトランとLLM:消費者の苦情を分析する...
- 「ETLにおける進化:変換の省略がデータ管...
- 無料でニュースレターを成長させる4つの方法
- Googleが「Gemini」というAIツールと、そ...
- ジェネラティブAIをマスターするための5つ...
- 「音で見る:GPT-4V(イジョン)とテキス...
- 「NVIDIAのCEO、ジェンソン・ホアン氏がSI...
- ランナーの疲労検知のための時間系列分類 ...
- 基本に戻る ウィーク4:高度なトピックと展開

このAI研究は、ポイントクラウドを2D画像、言語、音声、およびビデオと一致させる3Dマルチモダリティモデルである「Point-Bind」を紹介します
現在の技術的な景観では、3Dビジョンが急速な成長と進化により注目を浴びています。この関心の高まりは、自動運転、強化されたナビゲーションシステム、高度な3Dシーン理解、およびロボティクスといった分野の急成長に大いに貢献しています。3Dポイントクラウドを他のモダリティのデータと組み合わせるためには、3D理解の向上、テキストからの3D生成、および3Dの質問に答えるための試みが数多く行われています。 https://arxiv.org/abs/2309.00615 研究者は、Point-Bindという革命的な3Dマルチモーダルモデルを紹介しました。このモデルは、2D画像、言語、音声、ビデオなどのさまざまなデータソースとのポイントクラウドのシームレスな統合を目指しています。ImageBindの原則に基づいてガイドされたこのモデルは、3Dデータとマルチモダリティの間のギャップを埋める統一された埋め込み空間を構築します。このブレークスルーにより、任意のモダリティに基づいた3D生成、3D埋め込み算術、包括的な3Dオープンワールド理解など、多くのエキサイティングなアプリケーションが可能になります。 上記の画像では、Point-Bindの全体的なパイプラインが表示されています。研究者はまず、対照的な学習のために3D-画像-音声-テキストデータのペアを収集し、ImageBindによって3Dモダリティを他のモダリティに調整します。共通の埋め込み空間を持つことで、Point-Bindは3Dクロスモーダル検索、任意のモダリティに基づいた3D生成、3Dゼロショット理解、および3D大規模言語モデルの開発(Point-LLM)に利用することができます。 この研究のPoint-Bindの主な貢献は以下の通りです: ImageBindによる3Dの整列:共通の埋め込み空間内で、Point-Bindはまず3Dポイントクラウドを2D画像、ビデオ、言語、音声などのマルチモダリティと整列させます。 任意のモダリティに基づいた3D生成:既存のテキストから3Dへの生成モデルに基づいて、Point-Bindはテキスト/画像/音声/ポイントからメッシュの生成など、任意のモダリティに基づいた3D形状合成を可能にします。 3D埋め込み空間の算術:Point-Bindの3D特徴は、他のモダリティと組み合わせてその意味を取り込むために追加することができます。これにより、構成されたクロスモーダル検索が実現されます。 3Dゼロショット理解:Point-Bindは、3Dゼロショット分類の最先端の性能を達成します。また、テキストに加えて音声に基づいた3Dオープンワールド理解もサポートします。 https://arxiv.org/abs/2309.00615 研究者はPoint-Bindを活用して、3D質問応答やマルチモーダルな推論を実現するためにLLaMAを最適化した3D大規模言語モデル(Point-LLM)を開発しています。Point-LLMの全体的なパイプラインは、上記の画像で確認することができます。 Point LLMの主な貢献は以下の通りです: 3D質問応答のためのPoint-LLM: PointBindを使用して、英語と中国語の両方をサポートする、3Dポイントクラウド条件で指示に応答する初の3D LLM、Point-LLMを紹介します。 データとパラメータの効率: 3Dの指示データなしで、公共のビジョン言語データのみを調整に使用し、リソースを節約するためにパラメータ効率の高いファインチューニング技術を採用しています。 3Dおよびマルチモーダル推論: 共有埋め込み空間を介して、Point-LLMは3Dとマルチモーダルの入力の組み合わせを推論することにより、記述的な応答を生成することができます。例えば、画像/音声とポイントクラウドなどです。 将来の研究は、室内や屋外のシーンなど、より多様な3Dデータとマルチモダリティを統合することに焦点を当て、より広範な応用シナリオを可能にする予定です。
トランスフォーマーにおけるアテンションの説明【エンコーダーの観点から】
この記事では、特にエンコーダの視点から、トランスフォーマーネットワークにおけるアテンションの概念について詳しく掘り下げます以下のトピックをカバーします ...を見ていきます

「ChatGPTを再び視覚させる:このAIアプローチは、リンクコンテキスト学習を探求してマルチモーダル学習を可能にします」
言語モデルは、連続的で文脈に即したテキストを生成する能力により、コンピュータとのコミュニケーション方法を革新しました。大規模な言語モデル(LLM)は、人間の言語のパターンや微妙なニュアンスを学習するために、膨大な量のテキストデータにトレーニングされ、この進歩の最前線に立っています。LLMの革命の先駆者であるChatGPTは、さまざまな学問分野の人々に非常に人気があります。 LLMの非常に高い能力のおかげで、様々なタスクが容易になりました。テキストの要約、メールの作成支援、コーディングタスクの自動化、ドキュメントの説明などに使用されます。これらのタスクは、1年前にはかなり時間がかかるものでしたが、今ではわずか数分で完了します。 しかし、テキスト、画像、さらにはビデオなど、さまざまなモダリティをまたがってコンテンツを処理および生成する必要があるマルチモーダル理解の需要が増えてきており、マルチモーダル大規模言語モデル(MLLM)の必要性が浮上しています。MLLMは、言語モデルの力を視覚理解と組み合わせることで、機械がより包括的で文脈に即した方法でコンテンツを理解および生成することを可能にします。 ChatGPTのブームが少し収まった後、MLLMがAI界に台風のように吹き荒れ、テキストと画像をまたがるコンテンツの理解と生成を可能にしました。これらのモデルは、画像認識、ビジュアルグラウンディング、指示の理解などのタスクで驚異的なパフォーマンスを示しています。ただし、これらのモデルを効果的にトレーニングすることは依然として課題です。最大の課題は、MLLMが画像とラベルの両方が未知の完全に新しいシナリオに遭遇した場合です。 さらに、MLLMは、より長いコンテキストを処理する際に「中途で迷子になる」傾向があります。これらのモデルは、始まりと中間の位置に大きく依存しているため、ショット数が増えるにつれて正確性が停滞することを説明しています。そのため、MLLMはより長い入力に苦労します。 それでは、さあリンクコンテキスト学習(LCL)に会いましょう。 提案されたリンクコンテキスト学習のデモダイアログ。出典:https://arxiv.org/abs/2308.07891 MLLMには2つの主要なトレーニング戦略があります。マルチモーダルプロンプトチューニング(M-PT)とマルチモーダルインストラクションチューニング(M-IT)です。M-PTは、モデルの一部のパラメータのみを微調整し、他の部分は凍結したままにするアプローチです。このアプローチにより、計算リソースを最小限に抑えながら、完全な微調整と同様の結果を達成することができます。一方、M-ITは、指示の説明を含むデータセットでMLLMを微調整することにより、ゼロショットの能力を向上させます。この戦略により、事前のトレーニングなしで新しいタスクを理解し、応答するモデルの能力が向上します。これらはうまく機能しますが、どちらも一部の側面を犠牲にしています。 インコンテキスト学習とリンクコンテキスト学習の違い。出典:https://arxiv.org/abs/2308.07891 その代わりに、LCLは異なるトレーニング戦略を探求しています:ミックス戦略、2ウェイ戦略、2ウェイランダム、2ウェイウェイト。ミックス戦略はゼロショットの正確性を大幅に向上させ、6ショットで印象的な結果を達成することで注目されます。ただし、16ショットではパフォーマンスがわずかに低下します。これに対して、2ウェイ戦略は、2ショットから16ショットまでの正確性が徐々に向上しており、トレーニングされたパターンとのより密な一致を示しています。 従来の文脈学習とは異なり、LCLはモデルに源と目標の間のマッピングを確立させることで、全体的なパフォーマンスを向上させます。因果関係を持つデモンストレーションを提供することで、LCLはMLLMに類推だけでなく、データ点間の潜在的な因果関係も識別できるようにし、未知の画像を認識し、新しい概念をより効果的に理解することができます。ISEKAIデータセットは、リンクコンテキスト学習の文脈でMLLMの能力を評価および向上させるための重要なリソースとして機能します。 さらに、LCLはISEKAIデータセットを導入し、MLLMの能力を評価するために特別に設計された新しい包括的なデータセットです。ISEKAIデータセットには完全に生成された画像と作り出された概念が含まれています。これにより、MLLMは進行中の会話から新しい概念を吸収し、正確な質問応答のためにこの知識を保持することに挑戦されます。 結論として、LCLはマルチモーダル言語モデルのトレーニング戦略に関する貴重な洞察を提供します。混合戦略と2ウェイ戦略は、MLLMのパフォーマンスを向上させるための異なるアプローチを提供し、それぞれ独自の強みと制約があります。文脈分析は、長い入力を処理する際にMLLMが直面する課題に光を当て、この領域でのさらなる研究の重要性を強調しています。

「フラミンゴとDALL-Eはお互いを理解しているのか?イメージキャプションとテキストから画像生成モデルの相互共生を探る」
テキストとビジュアルのコンピュータ理解を向上させるマルチモーダル研究は、最近大きな進歩を遂げています。DALL-EやStable Diffusion(SD)などのテキストからイメージを生成するモデルや、FlamingoやBLIPのようなイメージからテキストを生成するモデルは、現実の状況からの複雑な言語的記述を高精度のビジュアルに変換することができます。しかし、テキストからイメージを生成するモデルと画像キャプション生成モデルの間には近接性がありながらも、独立して研究されることが多く、これらのモデルの相互作用は探求される必要があります。テキストからイメージを生成するモデルと画像からテキストを生成するモデルがお互いを理解できるかどうかという問題は興味深いものです。 この問題に取り組むために、特定の画像に対してテキストの説明を生成するためにBLIPという画像からテキストのモデルを使用します。このテキストの説明は、SDというテキストからイメージを生成するモデルに供給され、新しい画像が作成されます。彼らは、作成された画像が元の画像に似ている場合、BLIPとSDがコミュニケーションできると主張しています。共有された理解によって、各モデルの基本的なアイデアを理解する能力が向上し、キャプションの作成と画像合成がより良くなる可能性があります。このコンセプトは図1に示されており、上のキャプションは元の画像のより正確な再構成を導き、下のキャプションよりも入力画像をよりよく表現しています。 https://arxiv.org/abs/2212.12249 LMU Munich、Siemens AG、およびUniversity of Oxfordの研究者は、DALL-EがFlamingoが特定の画像に対して生成する説明を使用して新しい画像を合成する再構成タスクを開発しました。この仮定をテストするために、テキスト-イメージ-テキストとイメージ-テキスト-イメージの2つの再構成タスクを作成します(図1を参照)。最初の再構成タスクでは、事前学習済みのCLIPイメージエンコーダで抽出された画像の特徴の距離を計算し、再構成された画像と入力画像の意味がどれだけ似ているかを判断します。次に、生成されたテキストの品質を人間によって注釈付けされたキャプションと比較します。彼らの研究は、生成されたテキストの品質が再構成のパフォーマンスにどのように影響するかを示しています。これにより、彼らの最初の発見が導かれます:生成モデルが元の画像を再構成するための説明は、画像に最も適した説明であるということです。 同様に、SDがテキストの入力から画像を作成し、その作成された画像からBLIPがテキストを作成する逆のタスクを作成します。彼らは、元のテキストを生成した画像がテキストにとって最も優れたイラストであることを発見します。彼らは、再構成プロセス中に入力画像からの情報がテキストの記述に正確に保持されると仮定しています。この意味のある説明は、画像モダリティへの忠実な回復につながります。彼らの研究は、テキストからイメージやイメージからテキストのモデルがお互いとコミュニケーションするのを容易にする独自のフレームワークを示唆しています。 具体的には、彼らのパラダイムでは、生成モデルは再構成損失と人間のラベルからトレーニング信号を受け取ります。1つのモデルは、他のモダリティの特定の画像またはテキストの入力の表現を最初に作成し、異なるモデルはこの表現を入力モダリティに戻します。再構成コンポーネントは、初期モデルの微調整を指示する正則化損失を作成します。このようにして、彼らは自己および人間の監督を得て、生成がより正確な再構成に結果をもたらす可能性を高めます。たとえば、画像キャプションモデルは、ラベル付きの画像テキストのペアに対応するだけでなく、信頼性のある再構成につながるキャプションを好む必要があります。 エージェント間の通信は彼らの仕事と密接に関連しています。エージェント間の主要な情報交換手段は言語です。しかし、最初のエージェントと2番目のエージェントが猫や犬の定義を同じく持っていることを確信することはできますか?この研究では、最初のエージェントに画像を調査し、それを説明する文を生成するように求めます。テキストを受け取った後、2番目のエージェントはそれに基づいて画像をシミュレーションします。後者の段階は具現化プロセスです。彼らの仮説によれば、通信は効果的である場合、2番目のエージェントの入力画像のシミュレーションが最初のエージェントが受け取った入力画像に近い場合です。本質的には、彼らは人間の主要なコミュニケーション手段である言語の有用性を評価しています。特に、新たに確立された大規模な事前学習済みの画像キャプションモデルと画像生成モデルが彼らの研究で使用されています。さまざまな生成モデルに対して、トレーニングフリーおよび微調整の状況の両方で彼らの提案されたフレームワークの利点が証明されました。特に、トレーニングフリーのパラダイムでは、キャプションと画像の作成が大幅に改善されました。一方、微調整では、両方の生成モデルに対してより良い結果が得られました。 以下は彼らの主な貢献の要点です: • フレームワーク:従来の単独の画像からテキストへの生成モデルとテキストから画像への生成モデルが、簡単に理解できるテキストと画像の表現を介して通信する方法について初めて調査したと彼らは最もよく知っています。一方、同様の研究ではテキストと画像の作成を埋め込み空間を介して暗黙的に統合します。 • 結果:彼らは、テキストから画像へのモデルによって作成された画像の再構成を評価することが、キャプションの品質を判断するのに役立つことを発見しました。元の画像の最も正確な再構成を可能にするキャプションが、その画像に使用すべきキャプションです。同様に、元のテキストの最も正確な再構成を可能にするキャプションが最良のキャプション画像です。 • 改善:彼らの研究に基づいて、テキストから画像へのモデルと画像からテキストへのモデルの両方を改善する包括的なフレームワークを提案しました。テキストから画像へのモデルによって計算された再構成損失は、画像からテキストへのモデルの微調整に正則化として使用され、画像からテキストへのモデルによって計算された再構成損失は、テキストから画像へのモデルの微調整に使用されます。彼らは自身のアプローチの有効性を調査し、確認しました。
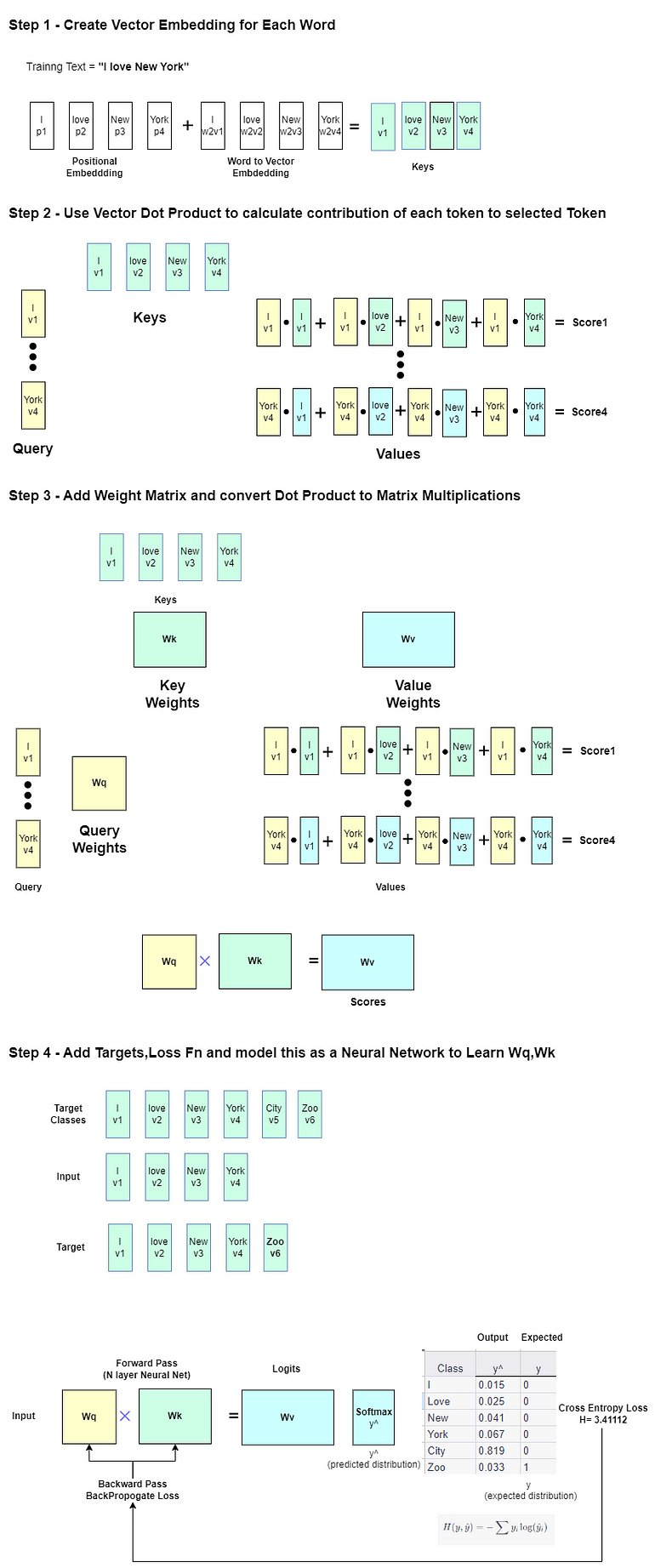
大規模言語モデルの探索 -Part 1
この記事は主に自己学習のために書かれていますそのため、広範囲かつ深い内容です興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に特定のセクションをスキップしてください以下にいくつかの…
「大規模な言語モデルの探索-パート3」
「この記事は主に自己学習のために書かれていますしたがって、広く深く展開されています興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に進めてください以下にはいくつかの...」

学生と機関のためのChatGPTプラグインで学習を向上させる
イントロダクション ChatGPTは、最も高度な会話型AIモデルの一つとして急速に注目を集めており、多様なトピックにわたって人間らしいテキストを生成する能力でユーザーを魅了しています。無料版のChatGPTは人気がありますが、学生や機関向けのChatGPTプラグインを利用することで、ユーザーは自分の体験をカスタマイズし、ウェブを閲覧し、特定の産業や興味に合わせた専門知識モジュールにアクセスすることができます。 ChatGPTプラグインは、大学や機関で学生の教育体験を向上させるためのプラットフォームを提供します。これらのプラグインは、専門ツールやリソースを取り入れることで、チャットボットの応答を特定の学術的要求に合わせることができます。プラグインによって、メインモデルの機能が拡張され、言語翻訳サービス、特定の科目に関する洞察、または難解な数学の問題の解決などが可能となります。さらに、学習の好みも異なるため、新しい改良された学習方法を促進することができます。 学習目標 ChatGPTプラグインの基本的な利用例を理解する。 学生や教育機関向けの人気で影響力のあるChatGPTプラグインのキュレートされたリストに深入りする。 学生が新しい概念を学び、問題を理解し、分析し、解決するためにこれらのプラグインを使用できる現実世界の利用例を分析する。 ChatGPTプラグインを使用したデータ分析のためのコードベースの入力と出力生成に深入りする。 この記事は、データサイエンスブログマラソンの一環として公開されました。 生成型AIとChatGPTプラグイン 生成型AIは、与えられた入力から新しい出力を生成することで、デジタルでの作成、分析、および対話を革新しました。ChatGPTは、一貫した文脈に基づいた応答を生成する能力で人気のあるプラットフォームとなっていますが、プラグインの統合により、より専門的な機能、他のソフトウェアとのシームレスな統合、そして教育機関や学生を含むさまざまな産業に対応したユーザーエクスペリエンスを提供することができます。 学生向け人気のあるChatGPTプラグイン 学生向けの人気のあるChatGPTプラグインの一部は以下の通りです: ダイアグラム:ChatGPT-4のダイアグラムプラグインは、ダイアグラムを使った視覚的な説明を容易にします。Mermaid、GraphViz、PlantUMLなどの異なる構文をサポートしています。ユーザーは説明や既存のダイアグラムへの変更を処理することができます。 ScholarAI:ScholarAIは、査読付きの学術論文や研究論文にアクセスするために使用できるプラグインです。このプラグインを使用することで、学生は関連する査読付きの研究を迅速にクエリでき、科学的な研究の改善や洞察を得るための信頼性のあるデータを確保することができます。 PDFでチャット:チャットウィズPDFは、ChatGPTを通じてインターネットからPDFファイルにアクセスし、クエリを行うことができるユーティリティです。この堅牢なユーティリティを使用すると、リンクを指定するだけでPDFから洞察を得るプロセスが簡素化されます。学生は文書の内容から質問をしたり、特定の詳細を求めることができます。 ウルフラム:ウルフラムプラグインは、ChatGPTの機能を強化し、計算ツール、数学関数、整理された情報、最新のデータ、視覚化機能に接続することで、数学の処理やデータの計算を含むさまざまな操作を行うことができます。これは、ダイアグラムなどの入力ダイアグラムから取得したデータを使用して数学を読み取り、処理、計算するといった操作と組み合わせることも可能です。 ビデオインサイト:ビデオインサイトプラグインは、リアルタイムでビデオコンテンツを分析し、価値ある洞察を得るのに役立ちます。学生は、長い講義ビデオからキーポイントの復習や要約を迅速に行い、メモを作成するためにこのプラグインを使用することができます。 オープンレクチャー:オープンレクチャープラグインは、大学レベルのコンテンツや講義にアクセスするために使用することができます。ポケットに大学の講義、書籍、学習ノートのデジタルアーカイブを所有することを目的としています。 コードインタプリタ:コードインタプリタは、AIチャットボットのデータのアップロード、コードの記述と編集、さまざまな操作と分析を行う能力を向上させるマルチ機能プラグインです。ChatGPTにデータの分析、チャートの作成、ファイルの編集、数学の計算を依頼することができます。データ分析などに使用することもできます。 ダイアグラムプラグイン Diagram Pluginとその使用方法について詳しく見てみましょう。Diagram Pluginは、複雑なアイデアやプロセスを表現するための可視化を作成するために使用できます。その機能を活用することで、学生はそれらを説明してデジタルダイアグラムを描くことができます。…
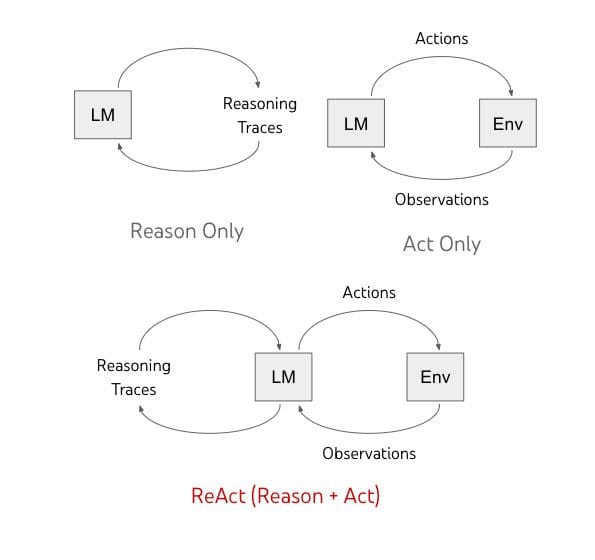
ReAct、Reasoning and Actingは、LLMをツールで拡張します!
「AIは推論と行動を融合させ、人間の知能を模倣するという大胆な新たな一歩を踏み出しています」

このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
最近、機械学習の検索分野において、深層ニューラルネットワークを応用することで大きな進歩がありました。特に、バイエンコーダーアーキテクチャ内の表現学習に重点を置いています。このフレームワークでは、クエリ、パッセージ、さらには画像などのマルチメディアなど、さまざまな種類のコンテンツが、密なベクトルとして表されるコンパクトで意味のある「埋め込み」として変換されます。このアーキテクチャに基づいて構築されたこれらの密な検索モデルは、大規模な言語モデル(LLM)内の検索プロセスの強化の基盤として機能します。このアプローチは人気があり、現在の生成的AIの広い範囲でLLMの全体的な能力を高めるのに非常に効果的であることが証明されています。 この論文では、多くの密なベクトルを処理する必要があるため、企業は「AIスタック」に専用の「ベクトルストア」または「ベクトルデータベース」を組み込むべきだと示唆しています。一部のスタートアップ企業は、これらのベクトルストアを革新的で不可欠な現代の企業アーキテクチャの要素として積極的に推進しています。有名な例には、Pinecone、Weaviate、Chroma、Milvus、Qdrantなどがあります。一部の支持者は、これらのベクトルデータベースが従来のリレーショナルデータベースをいずれ置き換える可能性さえ示しています。 この論文では、この説に対して反論を示しています。その議論は、既存の多くの組織で存在し、これらの機能に大きな投資がなされているという点を考慮した、簡単なコスト対効果分析を中心に展開されています。生産インフラストラクチャは、Elasticsearch、OpenSearch、Solrなどのプラットフォームによって主導されている、オープンソースのLucene検索ライブラリを中心とした広範なエコシステムによって支配されています。 https://arxiv.org/abs/2308.14963 上記の画像は、標準的なバイエンコーダーアーキテクチャを示しており、エンコーダーがクエリとドキュメント(パッセージ)から密なベクトル表現(埋め込み)を生成します。検索はベクトル空間内のk最近傍探索としてフレーム化されています。実験は、ウェブから抽出された約880万のパッセージから構成されるMS MARCOパッセージランキングテストコレクションに焦点を当てて行われました。評価には、標準の開発クエリとTREC 2019およびTREC 2020 Deep Learning Tracksのクエリが使用されました。 調査結果は、今日ではLuceneを直接使用してOpenAIの埋め込みを使用したベクトル検索のプロトタイプを構築することが可能であることを示唆しています。埋め込みAPIの人気の増加は、私たちの主張を支持しています。これらのAPIは、コンテンツから密なベクトルを生成する複雑なプロセスを簡素化し、実践者にとってよりアクセスしやすくしています。実際には、今日の検索エコシステムを構築する際に必要なのはLuceneだけです。しかし、時間が経って初めて正しいかどうかがわかります。最後に、これはコストと利益を比較することが主要な考え方であり続けることを思い起こさせてくれるものです。急速に進化するAIの世界でも同様です。

「ChatGPTをより優れたソフトウェア開発者にする:SoTaNaはソフトウェア開発のためのオープンソースAIアシスタントです」
私たちが行っている方法は、近年急速に変化しています。私たちはほとんどのタスクに仮想アシスタントを使用し、自分たちがタスクをAIエージェントに委任し続ける必要性を感じるようになっています。 これらの進歩をすべて推進する鍵となるのは、ソフトウェアです。ますます技術主導の世界で、ソフトウェア開発は、医療からエンターテイメントまで、さまざまなセクターでのイノベーションの鍵となります。ただし、ソフトウェア開発の道のりはしばしば複雑さと課題に満ちており、開発者に迅速な問題解決と創造的な思考を求めます。 そのため、AIアプリケーションはソフトウェア開発の領域で急速に広まっています。それらはプロセスを容易にし、開発者にコーディングに関するタイムリーな回答を提供し、彼らの努力をサポートします。つまり、おそらくあなたも使っているでしょう。ChatGPTの代わりにStackOverflowに行ったのはいつですか?また、GitHubのコパイロットをインストールしているときにTabキーを何回押しますか? ChatGPTとCopilotは素晴らしいですが、ソフトウェア開発でより良く機能するためには、適切に指示する必要があります。今日は、新しいプレイヤー、SoTaNaに会いましょう。 SoTaNaは、LLMsの能力を活用してソフトウェア開発の効率を向上させるソフトウェア開発アシスタントです。ChatGPTやGPT4などのLLMsは、人間の意図を理解し、人間らしい応答を生成する能力を示しています。テキストの要約やコード生成など、さまざまなドメインで価値を持っています。ただし、特定の制約のためにアクセシビリティが制限されていましたが、SoTaNaはこれに対処することを目指しています。 SoTaNaは、開発者とLLMsの広大な潜在能力とのギャップを埋めることを目指すオープンソースのソフトウェア開発アシスタントとして中心的な役割を果たします。この取り組みの主な目的は、限られた計算リソースを使用しながら、基礎となるLLMsが開発者の意図を理解する能力を高めることです。この研究では、ChatGPTを使用してソフトウェアエンジニアリングのタスクに基づいた高品質な指示ベースのデータを生成するための多段階のアプローチを取ります。 SoTaNaの概要。出典:https://arxiv.org/pdf/2308.13416.pdf プロセスは、新しいインスタンスを生成するための要件を詳細に説明する特定のプロンプトを使用してChatGPTをガイドすることから始まります。正確さと所望の出力との整合性を確保するために、ソフトウェアエンジニアリングに関連するインスタンスの手動で注釈付けされたシードプールが参照として機能します。このプールはさまざまなソフトウェアエンジニアリングのタスクを網羅し、新しいデータの生成の基盤となります。巧妙なサンプリング技術を使用することで、このアプローチはデモンストレーションのインスタンスを効果的に多様化し、要件を満たす高品質なデータの作成を確保します。 人間の意図をよりよく理解するために、SoTaNaは、限られた計算リソースを使用して、オープンソースの基礎モデルであるLLaMAを強化するために、パラメータ効率の良いファインチューニング手法であるLoraを採用しています。このファインチューニングプロセスにより、モデルはソフトウェアエンジニアリングのドメイン内での人間の意図の理解が洗練されます。 データ生成に使用されるプロンプト。出典:https://arxiv.org/pdf/2308.13416.pdf SoTaNa(ソータナ)の機能は、Stack Overflowの質問応答データセットを使用して評価され、人間の評価を含めて、開発者の支援におけるモデルの効果を強調しています。 SoTaNa(ソータナ)は、開発者の意図を理解し、関連する回答を生成することができるLLMをベースにしたオープンソースソフトウェア開発アシスタントを世界に紹介します。さらに、ソフトウェアエンジニアリングに特化した高品質の指示ベースのデータセットとモデルの重みを公開することで、コミュニティへの重要な貢献を行っています。これらのリソースは、将来の研究とイノベーションを加速する可能性を秘めています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.