Learn more about Search Results analyticsvidhya - Page 11

- You may be interested
- ルーターLangchain:Langchainを使用して...
- 初期段階の企業や初めての創業者が経済的...
- 「ジェンAIができることとできないことの5...
- 「人間の知能の解読:スタンフォードの最...
- 生物学的な学習から人工ニューラルネット...
- 「AWSは、人工知能、機械学習、生成AIのガ...
- Eleuther AI Research Groupが、Classifie...
- NVIDIAのGPUはAWS上でOmniverse Isaac Sim...
- 「アマゾンベッドロックを使った商品説明...
- VoAGIニュース、9月20日:ExcelでのPython...
- データバックフィリングの謎を解く
- 「AIの進化と生成AIへの道のりとその仕組み」
- 機械学習モデルの説明可能性:AIシステム...
- 「ゲームの名門生(SoG)と呼ばれる、新し...
- グーグルのディープマインドリサーチは、F...

「当社の独占的なマークダウンチートシートをチェックしてください」
Markdownは、複雑なHTMLや他の書式言語の必要性なく、さまざまな目的でテキストを簡単に書式設定する方法を提供する軽量のマークアップ言語です。そのシンプルさと使いやすさから、ドキュメンテーション、ブログ、その他の執筆プラットフォームで広く使用されています。このMarkdownチートシートでは、さまざまな書式オプションとそれらを効果的に使用する方法について説明します。 Markdownファイル Markdownは、プレーンテキストの書式設定を使用して豊かに書式設定されたドキュメントを作成する軽量のマークアップ言語です。これらのファイルは通常、.mdまたは.markdownの拡張子を持っています。ドキュメンテーションの作成、ブログ投稿の執筆、Webページのテキストの書式設定に一般的に使用されます。 マークダウンファイルをオフラインで開く方法 マークダウンファイルをオフラインで開くには、テキストエディタまたは専用のマークダウンエディタを使用できます。マークダウンファイルをオフラインで開く手順は次のとおりです: コンピュータ上のマークダウンファイルを見つけます。 ファイルを右クリックし、「開く」を選択します。 使用可能なプログラムのリストからテキストエディタまたはマークダウンエディタを選択します。 選択したエディタでマークダウンファイルが開き、その内容を表示および編集できます。 オンラインマークダウンエディタ オンラインマークダウンエディタは、ウェブブラウザで直接マークダウンファイルを作成およびプレビューするためのWebベースのツールです。これらのエディタは通常、リアルタイムのプレビュー、シンタックスハイライト、その他のマークダウンの作業に役立つ機能を提供します。 Markdownファイルの利点 学習と使用が容易: Markdownは、理解しやすく書きやすいシンプルな構文を持っています。HTMLやCSSのような複雑な書式設定コードは必要ありません。 プラットフォームに依存しない: Markdownファイルは、互換性のあるテキストエディタやマークダウンビューアを使用して、どのデバイスやオペレーティングシステムでも開いて表示することができます。 軽量: Markdownファイルはプレーンテキストファイルであり、小さくて読み込みが速いです。重い書式設定やスタイル情報は含まれていません。 バージョン管理に対応: MarkdownファイルはGitなどのバージョン管理システムとうまく機能します。マークダウンファイルへの変更は簡単に追跡、比較、マージすることができます。 ポータブル: Markdownファイルはさまざまなツールやコンバータを使用してHTML、PDF、Wordなどの他の形式に簡単に変換できます。このポータビリティにより、コンテンツを異なるプラットフォームやアプリケーションで共有することができます。 広くサポートされています:多くのテキストエディタ、コンテンツ管理システム(CMS)、パブリッシングプラットフォームがMarkdownをサポートしています。Web上でのコンテンツ作成において人気のある選択肢となっています。 では、Markdownチートシートを見てみましょう!…

魅力的な生成型AIの進化
イントロダクション 人工知能の広がり続ける領域において、研究者、技術者、愛好家の想像力を捉えているのは、ジェネラティブAIという魅力的な分野です。これらの巧妙なアルゴリズムは、ロボットが日々できることや理解できる範囲の限界を em>押し広げ、新たな発明と創造性の時代を迎えています。このエッセイでは、ジェネラティブAIの進化の航海に乗り出し、その謙虚な起源、重要な転換点、そしてその進路に影響を与えた画期的な展開について探求します。 ジェネラティブAIが芸術や音楽、医療や金融などさまざまな分野を革新した方法について調べ、単純なパターンを作成しようとする初期の試みから、現在の息をのむような傑作まで進化してきたことを見ていきます。ジェネラティブAIの将来の可能性について深い洞察を得るためには、その誕生につながった歴史的な背景と革新を理解する必要があります。機械が創造、発明、想像力の能力を持つようになった経緯を探求しながら、人工知能と人間の創造性の分野を永遠に変えた過程をご一緒に見ていきましょう。 ジェネラティブAIの進化のタイムライン 人工知能の絶え間なく進化する景色の中で、ジェネラティブAIという分野は、他のどの分野よりも多くの魅力と好奇心を引き起こしました。初期の概念から最近の驚異的な業績まで、ジェネラティブAIの旅は非常に特異なものでした。 このセクションでは、時間をかけて魅力的な旅に乗り出し、ジェネラティブAIの発展を形作ったマイルストーンを解明していきます。我々は、重要なブレイクスルー、研究論文、進歩を探求し、その成長と進化を包括的に描写します。 革新的な概念の誕生、影響力のある人物の出現、ジェネラティブAIの産業への浸透を見ながら、我々と一緒に歴史の旅に出かけ、生活を豊かにし、私たちが知っているAIを革新するジェネラティブAIの誕生を目撃しましょう。 1805年:最初のニューラルネットワーク(NN)/ 線形回帰 1805年、アドリアン=マリー・ルジャンドルは、入力層と単一の出力ユニットを持つ線形ニューラルネットワーク(NN)を導入しました。ネットワークは、重み付け入力の合計として出力を計算します。これは、現代の線形NNの基礎となる最小二乗法を用いた重みの調整を行い、浅い学習とその後の複雑なアーキテクチャの基礎となりました。 1925年:最初のRNNアーキテクチャ 1920年代、物理学者のエルンスト・イージングとヴィルヘルム・レンツによって、最初の非学習RNNアーキテクチャ(イージングまたはレンツ・イージングモデル)が導入され、分析されました。これは、入力条件に応じて平衡状態に収束し、最初の学習RNNの基盤となりました。 1943年:ニューラルネットワークの導入 1943年、ウォーレン・マクカロックとウォルター・ピッツによって、ニューラルネットワークの概念が初めて紹介されました。生物のニューロンの働きがそのインスピレーションとなっています。ニューラルネットワークは、電気回路を用いてモデル化されました。 1958年:MLP(ディープラーニングなし) 1958年、フランク・ローゼンブラットが最初のMLPを導入しました。最初の層は学習しない非学習層であり、重みはランダムに設定され、適応的な出力層がありました。これはまだディープラーニングではありませんでしたが、最後の層のみが学習されるため、ローゼンブラットは正当な帰属なしに後にエクストリームラーニングマシン(ELM)として再ブランドされるものを基本的に持っていました。 1965年:最初のディープラーニング 1965年、アレクセイ・イヴァハネンコとヴァレンティン・ラパによって、複数の隠れ層を持つディープMLPのための最初の成功した学習アルゴリズムが紹介されました。 1967年:SGDによるディープラーニング 1967年、甘利俊一は、スクラッチから確率的勾配降下法(SGD)を用いて複数の層を持つマルチレイヤーパーセプトロン(MLP)を訓練する方法を提案しました。彼らは、高い計算コストにもかかわらず、非線形パターンを分類するために2つの変更可能な層を持つ5層のMLPを訓練しました。 1972年:人工RNNの発表 1972年、阿弥俊一はレンツ・イジング再帰型アーキテクチャを適応的に変更し、接続重みを変えることで入力パターンと出力パターンを関連付ける学習を可能にしました。10年後、阿弥ネットワークはホプフィールドネットワークとして再発表されました。 1979年:ディープコンボリューショナルNN…

2023年に知っておくべきトップ15のビッグデータソフトウェア
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の推進力となっているため、私たちは出会う膨大な情報を処理するための最先端のツールにアクセスすることが重要です。しかし、数多くのオプションがあるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかることがあります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の洞察力と厳選された必須のビッグデータツールのリストを提供することで、情報を基にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動型の世界の課題に取り組み、ビジネスの可能性を最大限に引き出すことができます。一緒にこの旅に乗り出し、意思決定を革新する可能性のあるビッグデータ科学ツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さにより、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化における高い効率と技術を示しています。それは、数多くのソースから得られた構造化、半構造化、非構造化データで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム 価値 速度 なぜビッグデータソフトウェアと分析を使用するのですか? 以下は、ビッグデータソフトウェアと分析を使用する一般的な理由です: 記述的、予測的、規定的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータ型の処理を容易にするため 組織に対する費用効果のあるソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客エクスペリエンスの向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…
「2023年に知っておくべきトップ15のビッグデータソフトウェア」
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の原動力となるため、私たちは出会う膨大な情報を処理するための最新のツールにアクセスすることが重要です。しかし、数多くの選択肢があるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかる場合があります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の情報と厳選された必須のビッグデータツールのリストを提供し、情報を元にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動の世界の課題に取り組み、ビジネスのフルポテンシャルを引き出すことができます。一緒にこの旅に出かけて、意思決定を革新することができるビッグデータサイエンスツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さから、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化のための高効率な技術を備えています。様々なソースから得られる構造化、半構造化、非構造化のデータで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム バリュー 速度 なぜビッグデータソフトウェアと分析が必要なのですか? ビッグデータソフトウェアと分析を使用する一般的な理由は以下の通りです: 記述的、予測的、指示的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータタイプの処理を容易にするため 組織に費用対効果の高いソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客体験の向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…
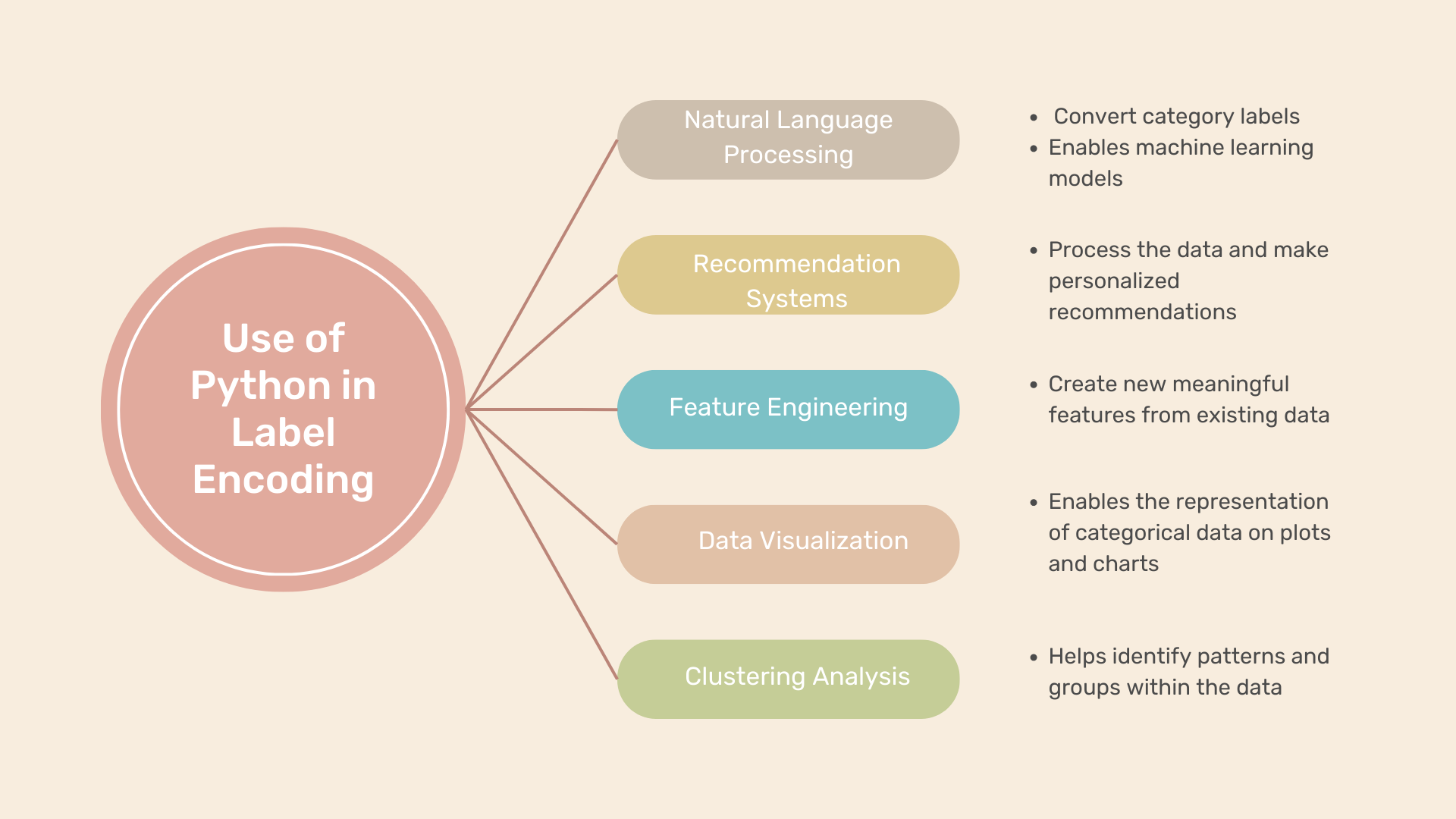
「Pythonでのラベルエンコーディングの実行方法」
データ分析や機械学習では、しばしばカテゴリカル変数を含むデータセットに遭遇します。これらの変数は数値ではなく、質的属性を表します。しかし、多くの機械学習アルゴリズムでは数値の入力が必要です。ここでラベルエンコーディングが重要な役割を果たします。カテゴリデータを数値のラベルに変換することで、ラベルエンコーディングはさまざまなアルゴリズムで使用することができます。この投稿では、ラベルエンコーディングの説明と、Pythonでの応用例、そして人気のあるsci-kit-learnモジュールを使用したラベルエンコーディングの適用方法の例を示します。 Pythonにおけるラベルエンコーディングとは何ですか? Pythonでは、カテゴリカル変数をラベルエンコーディング技術を使用して数値のラベルに変換することができます。これにより、機械学習アルゴリズムがデータを効果的に解釈して分析することができます。ラベルエンコーディングの関数の使い方を学ぶために、いくつかの例を見てみましょう。 Pythonでのラベルエンコーディングの例 例1:顧客セグメンテーション 顧客セグメンテーションのデータセットを想定してみましょう。このデータセットには、顧客の人口統計的特徴に関するデータが含まれています。「性別」、「年齢層」、「婚姻状況」などの変数があります。これらの変数内の各カテゴリに複数のラベルを付けることで、ラベルエンコーディングを実行することができます。例えば: カテゴリカル変数にラベルエンコーディングを適用することで、顧客セグメンテーション分析に適した数値形式でデータを表現することができます。 例2:製品カテゴリ 製品カテゴリのデータセットを考えてみましょう。このデータセットには、「製品名」や「カテゴリ」などの変数が含まれています。ラベルエンコーディングを行うために、各カテゴリに数値のラベルを割り当てます: ラベルエンコーディングにより、製品カテゴリを数値のラベルで表現することができます。これにより、さらなる分析やモデリングのタスクが可能になります。 例3:感情分析 感情分析のデータセットでは、「感情」という変数があります。この変数は、テキストドキュメントに関連付けられた感情(例:positive、negative、neutral)を表します。この変数にラベルエンコーディングを適用することで、各感情カテゴリに数値のラベルを割り当てることができます: ラベルエンコーディングにより、感情カテゴリを数値のラベルに変換することができます。これにより、感情分析のタスクをより簡単に実行することができます。 これらの例は、ラベルエンコーディングが異なるデータセットと変数に適用され、カテゴリ情報を数値のラベルに変換することで、さまざまな分析および機械学習のタスクを可能にすることを示しています。 Pythonでのラベルエンコーディングの使用例 ラベルエンコーディングは、カテゴリデータを扱う際にさまざまなシナリオで使用することができます。以下にいくつかの例を示します: 自然言語処理(NLP): ラベルエンコーディングは、テキストの分類や感情分析などのNLPアプリケーションで、positive、negative、neutralなどのカテゴリラベルを数値表現に変換することができます。これにより、機械学習モデルがテキストデータを正しく理解して分析することができます。 レコメンデーションシステム: レコメンデーションシステムでは、ユーザの好みやアイテムのカテゴリを表すためにカテゴリカル変数を使用することがよくあります。これらの変数にラベルエンコーディングを行うことで、レコメンデーションアルゴリズムはデータを処理し、ユーザの好みに基づいて個別の推薦を行うことができます。 特徴エンジニアリング: ラベルエンコーディングは特徴エンジニアリングの重要なステップです。ここでは既存のデータから新しい意味のある特徴を作成します。カテゴリカル変数を数値のラベルにエンコードすることで、異なるカテゴリ間の関係を捉えた新しい特徴を作成し、モデルの予測力を向上させることができます。 データの可視化: ラベルエンコーディングはデータの可視化のためにも使用することができます。カテゴリカル変数をエンコードすることで、数値入力が必要なプロットやチャート上でカテゴリデータを表現することができます。カテゴリ変数をエンコードすることで、データに対する洞察を提供する意味のある可視化を作成することができます。…

Googleのアナリティクスとデータサイエンスの領域を旅していく
イントロダクション Googleでアナリティクスとデータサイエンスの分野で優れた成果を挙げるプロフェッショナル、リシャブ・ディンドラに会いましょう。リシャブはデータを効果的に活用するための広範な専門知識と情熱を持っています。彼は先進技術を活用してイノベーションを推進し、価値ある洞察を抽出し、データに基づく意思決定を革新しています。リシャブのGoogleでのキャリアは素晴らしく、アナリティクスとデータサイエンスの分野を変革しました。彼の成果と貢献を探求して、Googleの成功を新たな高みに押し上げましょう。 リシャブから学びましょう! AV: Googleでデータサイエンティストになるまでの経歴を教えていただけますか?今の立場に至るためにどのようなステップを踏みましたか? リシャブ氏: 私は2011年にThorogood AssociatesでBIコンサルタントとしてキャリアをスタートし、それ以来データスペースで働いてきました。そのため、SQLやPythonなどの言語、データモデリング、プレゼンテーションスキル、およびTableauなどのツールの学習は、この旅の最初の必要なステップです。そして、数学と理論に深く入り込んでプロジェクトを行う人もいますが、私は実際にやってみてから概念を理解する方が最も効果的だと感じています。私にとって役立ったいくつかの重要なステップは次のとおりです: Analytics Vidhyaなどのプラットフォームでの素晴らしいコースを受講する Data Scienceのスキルを活用できる役割での機会を見つける 自分の情熱のあるテーマでプロジェクトを行う ビジネスとの緊密な連携とビジネスの理解 自分の知識を他の人と共有することで概念をより良く理解する ネットワーキングと他の人から学ぶこと Google Cloudの技術のスキルを獲得する データサイエンティストを目指すためのスキル AV: 成功したデータサイエンティストとして、データサイエンティストを目指す人にとって最も重要なスキルは何ですか?これらのスキルをどのように磨きましたか? ****リシャブ氏: 成功したデータサイエンティストとして、私はデータサイエンティストを目指す人にとって最も重要なスキルは次のとおりだと考えています: テクニカルスキル:…
「Googleのアナリティクスとデータサイエンスの領域を旅する」
紹介 Googleでアナリティクスとデータサイエンスの分野で優れたプロフェッショナルとして活躍するリシャブ・ディングラに会いましょう。リシャブはデータを効果的に活用するための幅広い専門知識と情熱を持っています。彼は先進技術を活用して革新を起こし、貴重な洞察を抽出し、データに基づく意思決定を革新しています。リシャブのGoogleでのキャリアは素晴らしいものであり、アナリティクスとデータサイエンスの分野を変革してきました。彼の功績と貢献を探ってみましょう。それがGoogleの成功を新たな高みに導いたものです。 リシャブから学ぼう! AV:Googleでデータサイエンティストになるまでの道のりを共有していただけますか?今の地位に至るまでにどのようなステップを踏みましたか? リシャブ氏:私は2011年にThorogood AssociatesでBIコンサルタントとしてキャリアをスタートさせ、それ以来データの分野で働いてきました。ですので、SQL、Python、データモデリング、プレゼンテーションスキル、そしてTableauのようなツールなど、最初に必要なステップはこれらの言語やスキルを学ぶことです。そしてその後、数学や理論の学習に深く入り込んでプロジェクトを行う人もいますが、私は実践して理解するという方法が最も効果的だと感じます。私が取ったいくつかの重要なステップは以下です: Analytics Vidhyaのようなプラットフォームでの素晴らしいコースを受講すること 自分の役割でデータサイエンスのスキルを活かせる機会を見つけること 情熱を持ってプロジェクトに取り組むこと ビジネスとの緊密な連携を図り、ビジネスについて学ぶこと 自分の知識を他の人と共有することで、概念をより良く理解すること ネットワーキングを通じて他の人から学ぶこと Google Cloudの技術を習得すること データサイエンティストを目指す人のためのスキル AV:成功したデータサイエンティストとして、データサイエンティストを目指す人にとって最も重要なスキルは何ですか?これらのスキルをどのように開発しましたか? リシャブ氏:成功したデータサイエンティストとして、私は次のスキルがデータサイエンティストを目指す人にとって最も重要だと考えています: 技術的スキル:これには強固な数学、統計学、プログラミングの基礎が含まれます。データサイエンティストはデータを収集、クリーニング、分析、可視化する能力が必要です。また、機械学習やディープラーニングの技術にも精通している必要があります。 問題解決スキル:データサイエンティストはデータを用いて問題を特定し、解決する能力が必要です。彼らは批判的かつ創造的に考え、新しい革新的な解決策を提案する必要があります。 コミュニケーションスキル:データサイエンティストは技術的、非技術的な双方のオーディエンスに対して自分の発見を伝えることができる必要があります。複雑な概念を明確かつ簡潔に説明する能力が求められます。 チームワークスキル:データサイエンティストはしばしば他のデータサイエンティスト、エンジニア、ビジネスプロフェッショナルと共同でプロジェクトに取り組みます。彼らは効果的に協力し、共通の目標に向かって働く必要があります。 私はこれらのスキルをコースを受講したり、個人プロジェクトに取り組んだり、他のデータサイエンティストとネットワーキングを行ったり、彼らの経験から学んだりすることで開発しました。 データサイエンティストを目指す人は避けるべき間違い…

DataHour プライベートデータと効果的な評価を備えたLlamaIndex QAシステム
イントロダクション Datahourは、データサイエンスと人工知能の分野で業界の専門家が知識と経験を共有するオンラインの1時間のウェブシリーズです。このセッションでは、Glance-Inmobiの優れたデータサイエンティストであるRavi Thejaが、推薦システム、NLPアプリケーション、生成モデルにおける先端的な機械学習モデルの構築と展開についての専門知識を共有しました。RaviはIIIT-Bangaloreでコンピュータサイエンスの修士号を取得し、データサイエンスと人工知能の基礎を確立しています。このセッションでは、LlamaIndexと、そのプライベートデータを使用してQAシステムを構築し、QAシステムを評価する方法について取り上げます。このブログ投稿では、セッションから得られた主なポイントと、Llama Indexとその応用について詳しく説明します。 Llama Indexとは何ですか? Llama Indexは、外部データソースとクエリエンジンの間のインターフェースとして機能するソリューションです。データエンジン、インデックスまたはデータサクセス、およびクエリインターフェースの3つのコンポーネントから構成されています。Llama Indexが提供するデータコネクタは、PDF、音声ファイル、CRMシステムなど、さまざまなソースから簡単にデータを取り込むことができます。インデックスは、異なるユースケースのためにデータを格納し、インデックスを作成します。クエリインターフェースは、必要な情報を取得して質問に答えるために使用されます。Llama Indexは、営業、マーケティング、採用、法務、財務など、さまざまなアプリケーションに役立ちます。 大量のテキストデータを処理する際の課題 このセッションでは、大量のテキストデータを処理する際の課題と、与えられた質問に適切な情報を抽出する方法について説明しています。さまざまなソースからプライベートデータが利用でき、それを使用する方法の1つは、データをトレーニングしてLLMを微調整することです。ただし、これには多くのデータの準備作業が必要であり、透明性に欠ける場合があります。もう1つの方法は、コンテキストを持つプロンプトを使用して質問に答えることですが、トークンの制限があります。 Llama Indexの構造 Llama Indexの構造は、ドキュメントをインデックス化することによってデータの概要を作成することを含みます。インデックス作成のプロセスでは、テキストドキュメントを異なるノードにチャンキングし、各ノードに埋め込みを持たせます。レトリーバは、指定されたクエリに対してドキュメントを取得し、クエリエンジンは取得と集計を管理します。Llama Indexには、ベクターストアインデックスなど、さまざまなタイプのインデックスがあります。セールスモデルを使用して応答を生成するために、システムはドキュメントをノードに分割し、各ノードに埋め込みを作成して格納します。クエリングでは、クエリの埋め込みとクエリに類似したトップノードを取得します。セールスモデルはこれらのノードを利用して応答を生成します。Llamaは無料であり、統合が可能です。 インデックス上のクエリに応じた応答の生成 講演者は、インデックス上のクエリに応じた応答の生成について説明しています。著者は、テストストアのインデクシングのデフォルト値が1に設定されていることを説明し、インデックス化にベクターを使用すると、回答を生成するために最初のノードのみが使用されることを意味すると述べています。ただし、すべてのノードを反復処理して応答を生成する場合は、リストインデックスを使用します。著者はまた、前の回答、クエリ、およびノード情報に基づいて回答を再生成するために使用される作成および改善フレームワークについても説明しています。講演者は、このプロセスが意味検索に役立ち、わずか数行のコードで達成できると述べています。 特定の応答モードを使用したドキュメントのクエリと要約 講演者は、Mindexツールが提供する「3要約」という特定の応答モードを使用して、ドキュメントのクエリと要約について説明しています。このプロセスでは、必要なライブラリをインポートし、ウェブページ、PDF、Google Driveなどのさまざまなソースからデータを読み込み、ドキュメントからベクターストアインデックスを作成します。テキストでは、ツールを使用して作成できるシンプルなUIシステムについても言及されています。応答モードでは、ドキュメントのクエリと記事の要約を行うことができます。講演者はまた、質問に答えるためのソースノートと類似性のサポートの使用についても言及しています。 CSVファイルのインデックス作成とクエリでの取得方法 テキストでは、CSVファイルのインデックス作成とクエリでの取得方法について説明しています。CSVファイルがインデックス化されると、クエリで取得することができますが、1つの行に異なる列に1つのデータポイントがある場合、一部の情報が失われる可能性があります。CSVファイルの場合、データをWSLデータベースに取り込み、任意のSQLデータベースの上にラッパーを使用してテキストU…
DataHour ラマインデックス QA システムにおけるプライベートデータと効果的な評価
イントロダクション Datahourは、データサイエンスと人工知能の分野で業界の専門家が知識と経験を共有するAnalytics Vidhyaのオンライン1時間のウェブシリーズです。Ravi ThejaというGlance-Inmobiの熟練したデータサイエンティストが、レコメンダーシステム、NLPアプリケーション、ジェネレーティブAIのための最新の機械学習モデルの構築と展開における専門知識を共有しました。RaviはIIIT-Bangaloreでコンピュータサイエンスの修士号を取得し、データサイエンスと人工知能の基礎を確固たるものにしました。このセッションは、LlamaIndexと、それがプライベートデータでQAシステムを構築し、QAシステムを評価する方法について取り上げています。このブログ投稿では、セッションからのキーポイントとLlama Indexの詳細な説明について説明します。 Llama Indexとは何ですか? Llama Indexは、外部データソースとクエリエンジンの間のインターフェースとして機能するソリューションです。データエンジン、インデックスまたはデータサクセス、クエリインターフェースの3つのコンポーネントから構成されています。Llama Indexが提供するデータコネクタにより、PDF、音声ファイル、CRMシステムなど、さまざまなソースからのデータの簡単な取り込みが可能です。インデックスは、さまざまなユースケースのデータを格納し、インデックス化し、クエリインターフェースは必要な情報を取得して質問に答えるためのものです。Llama Indexは、営業、マーケティング、採用、法律、財務など、さまざまなアプリケーションに役立ちます。 大量のテキストデータを扱う際の課題 このセッションでは、大量のテキストデータを扱う際の課題と、与えられた質問に適切な情報を抽出する方法について議論されています。さまざまなソースからプライベートデータが利用でき、それを使用する方法の1つは、データをトレーニングしてLLMを微調整することです。ただし、これには多くのデータの準備作業が必要であり、透明性に欠けます。別の方法は、コンテキストを持つプロンプトを使用して質問に答えることですが、トークンの制限があります。 Llama Indexの構造 Llama Indexの構造は、ドキュメントのインデックスを作成することによってデータの概要を作成することを含みます。インデックス作成のプロセスでは、テキストドキュメントを異なるノードにチャンク分割し、各ノードに埋め込みが付いた形で行われます。リトリーバーは、指定されたクエリに対してドキュメントを取得し、クエリエンジンはリトリーバーとセンサスの管理を行います。Llama Indexにはさまざまなタイプのインデックスがあり、ベクトルストアインデックスが最も単純です。営業モデルを使用して応答を生成するために、システムはドキュメントをノードに分割し、各ノードに埋め込みを作成して保存します。クエリングでは、クエリの埋め込みとクエリに類似したトップノードを取得します。営業モデルは、これらのノードを使用して応答を生成します。Llamaは無料であり、collapseと統合されます。 インデックス上のクエリに応じたレスポンスの生成 スピーカーは、インデックス上のクエリに応じたレスポンスの生成について話し合います。著者は、テストストアのインデックスのデフォルト値が1に設定されており、インデックス用のベクトルを使用すると、回答を生成するために最初のノードのみが使用されることを説明しています。ただし、LLMが応答を生成するためにすべてのノードを繰り返す場合は、リストインデックスを使用します。著者はまた、前の回答、クエリ、およびノードの情報に基づいて回答を再生成するために使用される「create and refine」フレームワークについても説明しています。スピーカーは、このプロセスがセマンティックサーチに役立ち、わずかなコードで実現できることを述べています。 特定のレスポンスモードを使用したドキュメントのクエリと要約 スピーカーは、Mindexツールが提供する「3要約」と呼ばれる特定のレスポンスモードを使用して、ドキュメントのクエリと要約の方法について説明しています。このプロセスでは、必要なライブラリをインポートし、Webページ、PDF、Googleドライブなどからデータをロードし、ドキュメントからベクトルストアインデックスを作成します。テキストには、ツールを使用して作成できるシンプルなUIシステムについても言及されています。レスポンスモードでは、ドキュメントのクエリと記事の要約が可能です。スピーカーはまた、質問に答えるためのソースノートと類似性のサポートを使用する方法についても言及しています。…

「マイクロソフトのシニアデータサイエンティストの成功ストーリー」
イントロダクション 現代のデジタル時代において、データの力は否応なく認められており、その潜在能力を引き出すスキルを持つ人々が技術の未来を形作る中でリードしています。その中でも、データサイエンスの領域において卓越した人物、ニルマル氏は、世界でも屈指のテクノロジー企業であるマイクロソフトでシニアデータサイエンティストとして活躍しているビジョンを持つ人物です。 運命に挑み、才能と献身の結晶であるニルマル氏は、謙虚な出自から始まる変革の旅に乗り出し、マイクロソフトでシニアデータサイエンティストとしてのキャリアの頂点に上り詰めました。彼の急速な昇進は、データサイエンティスト志望者だけでなく、夢と偉大さを実現するための決意を持つすべての人々にとっても、インスピレーションを与える成功物語となっています。 この成功物語の記事では、ニルマル氏のキャリアに焦点を当て、彼の非凡なキャリアを形作った重要なマイルストーン、課題、勝利を追跡します。彼が主導した画期的なプロジェクト、もたらした変革の影響、そして彼が学んだ貴重な教訓を探求します。ニルマル氏の物語を通じて、データサイエンスの絶えず進化する世界で成功するために必要な特性とマインドセットを発見します。 会話を始めましょう! AV: キャリアの軌跡、教育の背景を強調し、最初のデータサイエンティストの仕事を得るのにどのように役立ちましたか? ニルマル氏: 私のキャリアの軌跡は常に一直線ではありませんでした。私たち一人ひとりにはそれぞれの物語があり、それらがすべて興味深いことでしょう。私の物語はこちらです。私はネパールでITエンジニアの学士号を取得しました。2007年にアメリカ合衆国に移住し、修士号を取得しました。修士課程を修了した後、私は米国陸軍に参加しました。はい、非常に普通ではないと思われるかもしれません。2009年ごろのアメリカでの大不況(ちょうど私の卒業年でもありました)により、特に留学生にとっては就職市場が非常に悪い状況でした。米国陸軍による特別なパイロットプログラムがあり、私は必要な手続きをすべて経て軍務員になることができました。子供の頃から軍に入隊することに対する情熱がありました。それを実現する方法です。 軍務中、私はMBAを取得しました。2014年、最初の兵役契約が終了した後、私は米国陸軍を退役しました。同年、私は初めてのデータ役職として、海軍省の連邦政府職員としてサイバーセキュリティアナリストとしての仕事を得ました。この仕事をしている間にデータサイエンスの修士号を取得しました。データアナリストとしての経験を積み、学術的な資格とデータサイエンスのスキルを身につけた後、2018年にウェルズ・ファーゴ銀行でデータサイエンティストの役職で私の最初の役職に就きました。それ以来、データサイエンスに従事しており、現在はマイクロソフトのシニアデータサイエンティストとして働いています。 AV: データを使用して実世界の問題を解決し、ビジネスや製品戦略に与えた影響について教えていただけますか? ニルマル氏: たくさんの例があります。まず、私たちはデータサイエンティストの役職に就かなくても、データの問題を解決するために取り組むことができます。そんな誤解があります。私たちはデータアナリスト、データエンジニア、ビジネスアナリストなど、データを扱うさまざまな役職で働くことができます。 私は主にサイバーセキュリティの領域で働いています。私たちの主な焦点の2つは、調査と検出です。サイバーセキュリティの問題に取り組む際に非常にポピュラーな問題の1つは、異常検知です。私はデータサイエンスチームで異常検知システムを構築し、セキュリティアナリストが注目すべきイベント/アラートに費やす時間を節約するのを助けました。その影響は彼らの時間とリソースの節約にあります。 AV: データサイエンスを使用して解決した最も困難な問題は何でしたか?問題にどのように取り組みましたか?結果はどうでしたか? ミスター・ニルマル: 私が一番難しいと感じる問題はまだ解決されていないと言ってもいいでしょう。私たちは非常に革新的なAIの世界に生きているため、敵対者が今まで以上に最先端のツールを持っていることを常に意識しなければなりません。しかし、興味深い問題をひとつ挙げるとすれば、ユーザーの行動分析、またはユーザーエンティティの行動分析とも呼ばれるもので、業界では広く知られているUEBAと呼ばれるものです。UEBAは、通常の基準から逸脱するユーザーのアクティビティを特定することで脅威を発見するタイプのサイバーセキュリティ機能です。 簡単な例: A地点からよくログインしているユーザーが、突然B地点からログインしているアクティビティが観測されます。これは旅行に関連するものかもしれませんが、それでも通常の行動から逸脱しているため、正常性対悪意性を確認するために調査する必要があります。UEBAの最も難しい部分は、基準を理解し作成することです。 データ駆動の洞察 AV: テクニカルでない利害関係者に複雑なデータ駆動の洞察を伝える必要があった場面のストーリーを共有していただけますか?彼らが洞察とビジネスへの影響を理解したことを確認するためにどのような工夫をしましたか?…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.