Learn more about Search Results Pi - Page 11

- You may be interested
- 「AI を活用した脳手術が香港で現実化」
- 「関数をキャッシュしてPythonをより速く...
- 「生成型AI:CHATGPT、Dall-E、Midjourney...
- Amazon SageMaker Data WranglerのSnowfla...
- AIを活用したエネルギー効率:今日の電気...
- In Japanese ゼファー7Bベータ:必要な...
- このAIペーパーは、東京大学で深層学習を...
- AI(人工知能)はキッチンを乗っ取ってい...
- 「Juliaプログラミング言語の探索:アプリ...
- GPTエンジニア:1つのプロンプトで強力な...
- 「キャリアのために右にスワイプ:仕事の...
- 「IoT企業のインテリジェントビデオアナリ...
- 「あなたの学校の次のセキュリティガード...
- 「加速、効率的なAIシステムの新しいクラ...
- マウス用のVRゴーグル:ネズミの世界の秘...

「ToolLLMをご紹介します:大規模言語モデルのAPI利用を向上させるためのデータ構築とモデルトレーニングの一般的なツールユースフレームワーク」
多くのツール(API)と効率的に接続し、困難なタスクを完了するために、ツール学習は大規模な言語モデル(LLM)の潜在能力を活用しようとします。 LLMは、APIとの接続により、消費者と大規模なアプリケーションエコシステムとの効果的な仲介役としての価値を大幅に高めることができます。オープンソースのLLMであるLLaMAやVicunaなどの指示チューニングにより、さまざまな機能を持つことができましたが、ユーザーの指示を理解し、ツール(API)との効果的なインターフェースを実現するなど、より高度なタスクを処理する必要があります。これは、現在の指示チューニングが主に単純な言語タスク(例:カジュアルチャット)に焦点を当てているためです。 一方、ツールの使用に優れたスキルを持つGPT-4などの最新の状態-of-the-art(SOTA)LLMは、クローズドソースであり、内部動作に不透明です。そのため、コミュニティ主導のイノベーションやAI技術の民主化の幅が制約されます。このような観点では、オープンソースのLLMがさまざまなAPIを適切に理解できるようにすることが重要であると見なされています。以前の研究では、ツールの使用に対する指示チューニングデータの作成に取り組んでいましたが、内在的な制約により、LLM内のツールの使用能力を完全に刺激することはできませんでした。 (1) 制約されたAPI:現実のAPI(RESTAPIなど)を無視するか、十分な多様性を持たない狭い範囲のAPIのみを考慮しています。 (2) 制約されたシナリオ:既存の研究は、単一のツールのみを使用する指示に限定されています。一方、現実の設定では、多数のツールを組み合わせて多ラウンドのツール実行を行い、困難なタスクを完了する必要がある場合があります。 さらに、多数のAPIが提供されている場合、ユーザーが特定のコマンドに最適なAPIセットを事前に決定することを前提としていますが、これは不可能です。 (3) 低品質な計画と推論:既存の研究では、モデルの推論のために単純なプロンプトメカニズム(チェーンオブソートやReACTなど)が使用されており、完全にLLMにエンコードされた能力を引き出すことができず、複雑な指示を処理することができません。これは、オープンソースのLLMにとって特に深刻な問題であり、SOTAのLLMよりも推論能力がはるかに劣っています。さらに、一部の研究では、後続のモデル開発において重要なデータである真の応答を取得するためにさえAPIを使用していません。彼らは、オープンソースのLLM内でツールの使用能力を刺激するためのデータ生成、モデルトレーニング、評価のための一般的なツール使用フレームワークであるToolLLMを提案します。 図1は、APIリトリーバーとToolLLaMAのトレーニングを3つのステップで行い、ToolBenchを構築する方法を示しています。 指示の推論中にAPIリトリーバーが関連するAPIをToolLLaMAに提案し、ToolLLaMAは最終結果に到達するために多くのAPI呼び出しを行います。ToolEvalは審議の全体プロセスを評価します。 彼らはまず、図1に示すような高品質の指示チューニングデータセットであるToolBenchを収集します。最新のChatGPT(gpt-3.5-turbo-16k)を使用して、自動的に生成されます。表1には、ToolBenchと以前の取り組みの比較が示されています。特に、ToolBenchの作成には3つのステージがあります: • APIの収集:RapidAPI2から16,464のREST(表現状態転送)APIを収集します。このプラットフォームには、開発者によって提供される実世界のAPIが多数あります。これらのAPIは、eコマース、ソーシャルネットワーキング、天気など、49の異なる領域をカバーしています。各APIの包括的なAPIドキュメントをRapidAPIからスクレイプし、機能の要約、必要な入力、API呼び出しのためのコードサンプルなどを含めます。モデルがトレーニング中に遭遇しなかったAPIにも汎化するために、LLMがこれらのドキュメントを理解することでAPIを利用することを学ぶことを期待しています。 • Instruction Generation(指示生成):彼らはまず、全体のAPIコレクションからいくつかのAPIを選び、ChatGPTにこれらのAPIに関するさまざまな指示を開発するように依頼します。シングルツールとマルチツールのシナリオをカバーする指示を選択し、実世界の状況をカバーします。これにより、モデルはさまざまなツールを個別に扱う方法と、それらを組み合わせて難しいタスクを完了する方法を学ぶことができます。 • Solution Path Annotation(解決経路の注釈):彼らはこれらの指示に対する優れた回答をハイライトします。各応答には、モデルの推論とリアルタイムのAPIリクエストの複数のイテレーションが含まれる場合があります。最も高度なLLMであるGPT-4ですら、複雑なコマンドの成功率が低いため、ツールの学習の固有の難しさにより、データ収集が効果的でなくなります。このため、彼らはユニークな深さ優先探索ベースの意思決定木(DFSDT)を作成し、LLMsの計画と推論の能力を向上させることでこれに対処します。従来の思考の連鎖(CoT)やReACTに比べて、DFSDTはLLMsがさまざまな論理を評価し、戻るか続行するかを判断する能力を持たせます。研究では、DFSDTはCoTやReACTを使用して返答できない難しい指示を効果的に完了し、注釈の効率を大幅に向上させます。 清華大学、ModelBest社、中国人民大学、イェール大学、WeChat AI、テンセント社、知乎社の研究者たちは、ChatGPTをサポートする自動評価システムであるToolEvalを作成し、LLMsのツール使用能力を評価しました。ToolEvalには2つの重要なメトリックが含まれています:(1)勝率(win…

予測API:DjangoとGoogle Trendsの例
Djangoは高水準のPythonウェブフレームワークです速く、安全で、スケーラブルに設計されており、複雑さが増すことが予想される堅牢なウェブアプリケーションの開発に人気の選択肢です...
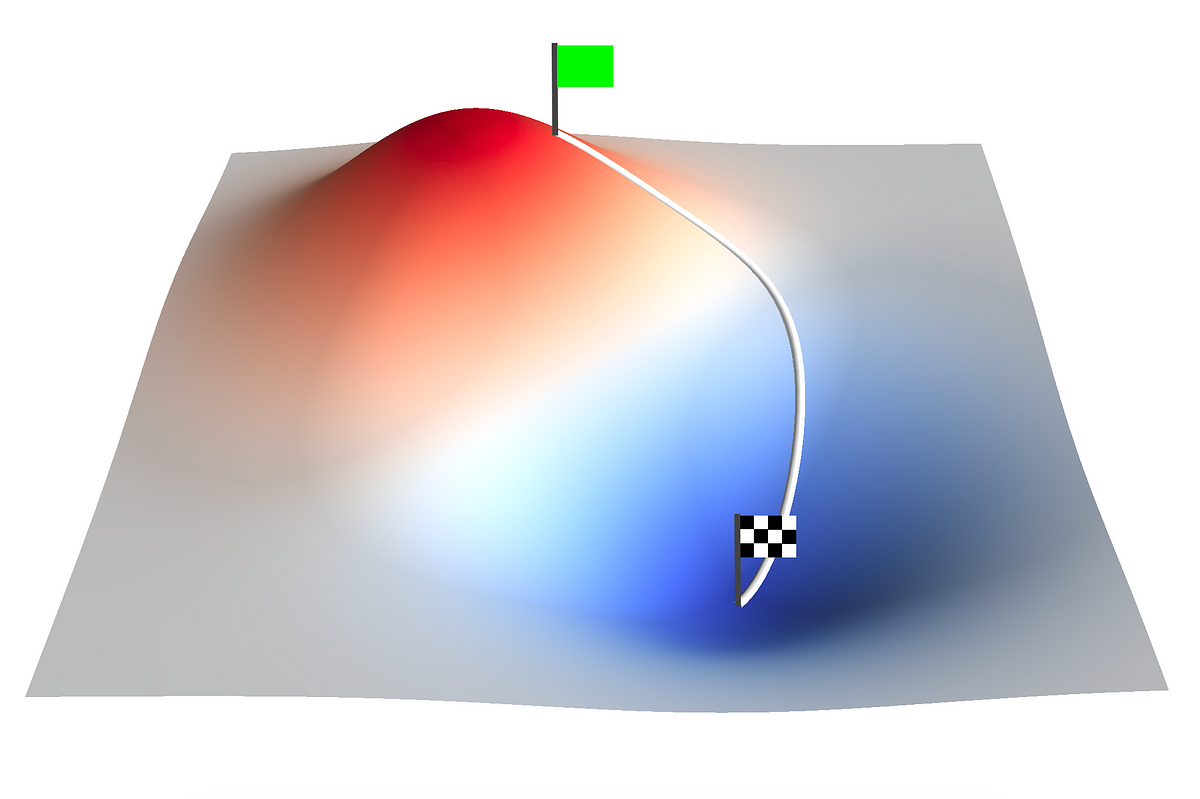
PIDコントローラの最適化:勾配降下法のアプローチ
「機械学習ディープラーニングAIこれらの技術を日々利用する人々がますます増えていますこれは、ChatGPTやBardなどによって展開された大規模言語モデルの台頭によって大いに推進されています...」

「Tiktokenを使用して、OpenAI APIのコストを簡単に見積もることができます」
「tiktokenを使用してテキスト内のトークンをトークン化し、トークンの数を計算してOpenAI APIのコストを算出する方法」

「LangChain、Activeloop、およびDeepInfraを使用したTwitterアルゴリズムのリバースエンジニアリングのためのプレーンな英語ガイド」
このガイドでは、Twitterの推奨アルゴリズムを逆解析して、コードベースをより理解し、より良いコンテンツを作成するための洞察を提供します

「LangChainとOpenAI APIを使用した生成型AIアプリケーションの構築」
イントロダクション 生成AIは、現在の技術の最先端をリードしています。画像生成、テキスト生成、要約、質疑応答ボットなど、生成AIアプリケーションが急速に拡大しています。OpenAIが最近大規模な言語モデルの波を牽引したことで、多くのスタートアップがLLMを使用した革新的なアプリケーションの開発を可能にするツールやフレームワークを開発しました。そのようなツールの一つがLangChainです。LangChainは、LLMによるアプリケーションの構築を可能にする柔軟性と信頼性を備えたフレームワークです。LangChainは、世界中のAI開発者が生成AIアプリケーションを構築するための定番ツールとなっています。LangChainは、外部データソースと市場で利用可能な多くのLLMとの統合も可能にします。また、LLMを利用したアプリケーションは、後で取得するデータを格納するためのベクトルストレージデータベースが必要です。この記事では、OpenAI APIとChromaDBを使用してアプリケーションパイプラインを構築することで、LangChainとその機能について学びます。 学習目標: LangChainの基礎を学んで生成AIパイプラインを構築する方法を学ぶ オープンソースモデルやChromadbなどのベクトルストレージデータベースを使用したテキスト埋め込み LangChainを使用してOpenAI APIを統合し、LLMをアプリケーションに組み込む方法を学ぶ この記事は、データサイエンスブログマラソンの一環として公開されました。 LangChainの概要 LangChainは、最近大規模言語モデルアプリケーションのための人気のあるフレームワークになりました。LangChainは、LLM、外部データソース、プロンプト、およびユーザーインターフェースとの対話を提供する洗練されたフレームワークを提供しています。 LangChainの価値提案 LangChainの主な価値提案は次のとおりです: コンポーネント:これらは言語モデルで作業するために必要な抽象化です。コンポーネントはモジュール化されており、多くのLLMの使用例に簡単に適用できます。 既製のチェーン:特定のタスク(要約、Q&Aなど)を達成するためのさまざまなコンポーネントとモジュールの構造化された組み立てです。 プロジェクトの詳細 LangChainはオープンソースプロジェクトであり、ローンチ以来、54K+のGithubスターを集めています。これは、プロジェクトの人気と受け入れられ方を示しています。 プロジェクトのreadmeファイルでは、次のようにフレームワークを説明しています: 大規模言語モデル(LLM)は、以前は開発者ができなかったアプリケーションを作成するための変革的な技術として現れつつあります。ただし、これらのLLMを単独で使用するだけでは、本当に強力なアプリを作成するには不十分なことがしばしばあります。真のパワーは、他の計算ソースや知識と組み合わせるときに発揮されます。 出典:プロジェクトリポジトリ 明らかに、フレームワークの目的を定義し、ユーザーの知識を活用したアプリケーションの開発を支援することを目指しています。 LangChainコンポーネント(出典:ByteByteGo) LangChainには、LLMアプリケーションを構築するための6つの主要なコンポーネントがあります:モデルI/O、データ接続、チェーン、メモリ、エージェント、およびコールバック。このフレームワークは、OpenAI、Huggingface Transformers、Pineconeやchromadbなどのベクトルストアなど、多くのツールとの統合も可能にします。…

「4つのテック巨人 – OpenAI、Google、Microsoft、Anthropicが安全なAIのために結集」
人工知能の世界で最も有名な4社が、先進的なAIモデルの責任ある開発を確保するための強力な業界団体の設立を目指し、連携する画期的な動きを行っています。OpenAI、Microsoft、Google、Anthropicは、Frontier Model Forumの設立を発表しました。この連合は、公共の安全に重大なリスクをもたらすと考えられる高度なAIおよび機械学習システムである「フロンティアAI」モデルによって提起される独特の規制上の課題に取り組むことを目的としています。この画期的な取り組みとその将来のAI開発への潜在的な影響について詳しく見ていきましょう。 また読む:Google、AIモデルをより安全にするためにSAIFフレームワークを導入 フロンティアモデルフォーラムの誕生 AI技術の規制監督の需要が高まる中、フロンティアモデルフォーラムが誕生しました。チャットGPTプラットフォームの開発で有名なOpenAIは、テックジャイアントMicrosoftとGoogle、さらにはAnthropicの革新的なメンバーと連携して、AI開発の未来を形作るリーダーとなることを目指しています。彼らの共通の目標は、公共の安全を保護しながら革新の限界を押し進める「フロンティアAI」モデルの責任ある創造を確保することです。 また読む:Microsoftがリード:未来を守るためのAIルールの緊急呼びかけ フロンティアAIとその課題の理解 フロンティアAIモデルは、技術の最先端に位置し、社会に大きな影響を与える可能性を持っています。しかし、これらの能力ゆえに、効果的に規制することは困難です。危険なのは、AIモデルが予期しない危険な機能を獲得する可能性があることであり、これによって誤用や意図しない害を引き起こす可能性があります。この問題には、業界のリーダーや関係者の協力が必要です。 また読む:OpenAIがスーパーアライメントを導入:安全でアライメントされたAIの道を開拓 フロンティアモデルフォーラムの目標 フロンティアモデルフォーラムは、安全で責任あるAI開発を推進するための野心的な目標を設定しています。これらの目標には、以下が含まれます: AIセーフティ研究の推進:フォーラムは、フロンティアAIモデルの能力評価と安全対策の標準化につながる研究を推進することを目指しています。これにより、リスクを最小限に抑え、高度なAI技術の責任ある展開を確保します。 ベストプラクティスの特定:フォーラムは、集合的な専門知識を通じて、フロンティアAIモデルの開発と展開のためのベストプラクティスを確立することを目指しています。明確なガイドラインは、開発者がこの技術の複雑さに対処し、責任あるイノベーションを促進します。 知識共有と協力:フロンティアAIによって引き起こされる課題に取り組むためには、協力が重要です。フォーラムは、政策立案者、学者、市民社会、企業を結集し、AI技術に関連する信頼性と安全性のリスクについての知識と洞察を共有します。 社会的利益のためのAI:フロンティアAIには潜在的なリスクが伴いますが、気候変動、がん検出、サイバーセキュリティの脅威など、重要なグローバル課題に取り組むためのAIアプリケーションの開発をサポートすることをフォーラムは約束しています。 新しいメンバーを歓迎する包括的なフォーラム フロンティアモデルフォーラムは現在4つのメンバーで構成されていますが、拡大を歓迎しています。フロンティアAIモデルの開発と展開に積極的に関与し、安全性への強い取り組みを示す組織は、この革新的な取り組みに参加することを招待されています。フォーラムの包括的なアプローチは、多様な視点を持ち込むことで、AI倫理と安全に関する議論を豊かにします。 また読む:MicrosoftとOpenAIがAIの統合を巡って対立 協力的な取り組みを前進させる フロンティアモデルフォーラムの創設メンバーは、イニシアチブの即時の将来に向けたロードマップを策定しています。具体的なステップには、戦略を指導する諮問委員会の設立、憲章とガバナンスの構築、資金の確保などが含まれます。企業はまた、市民社会や政府からの意見を求めることにも取り組んでおり、フォーラムの設計が社会全体の広い利益と一致するようにしています。 また読む:OpenAIとDeepMindが英国政府と協力し、AIの安全性と研究を前進させる 私たちの意見 フロンティアモデルフォーラムの設立は、AIの風景における画期的な瞬間を示しています。産業界のリーダーが安全で責任あるAIの開発をリードするために結集することは、安心感があります。OpenAI、Microsoft、Google、Anthropicによるこの連携は、フロンティアAIの未来を形作る可能性を秘めています。彼らは潜在的なリスクに対して保護しながら、AIの変革的な力を解き放つことができます。この協力の取り組みは、確かにAIコミュニティと社会全体に大きな影響を与えるでしょう。フォーラムが新しいメンバーを迎え、その使命に取り組むにつれて、世界はその良い結果を期待して注目しています。

「Amazon EC2 Inf1&Inf2インスタンス上のFastAPIとPyTorchモデルを使用して、AWS Inferentiaの利用を最適化する」
「ディープラーニングモデルを大規模に展開する際には、パフォーマンスとコストのメリットを最大限に引き出すために、基盤となるハードウェアを効果的に活用することが重要です高スループットと低レイテンシーを必要とするプロダクションワークロードでは、Amazon Elastic Compute Cloud(EC2)インスタンス、モデルの提供スタック、展開アーキテクチャの選択が非常に重要です効率の悪いアーキテクチャは[…]」
「Llama 2の機能を実世界のアプリケーションに活用する:FastAPI、Celery、Redis、およびDockerを使用したスケーラブルなチャットボットの構築」
「Llama 2を探索し、オープンソースの影響、プロンプトエンジニアリング、そしてスケーラブルなLLMアーキテクチャを探求してください」

ChatGPT モデレーション API 入力/出力制御
この記事では、OpenAIモデレーションAPIを使用してLLMパワードアプリケーションを構築する際に、モデルの入力と出力の両方を積極的にモデレートすることの重要性について探求します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.