Learn more about Search Results Jam - Page 11

- You may be interested
- 「IBMが脳をモチーフにしたコンピュータチ...
- 会社独自のChatGPTを開発するには、技術の...
- 「13/11から19/11までの週のトップ重要なL...
- JPLは、マルウェア研究を支援するためのPD...
- 「グローバル人工知能市場は31%の急成長...
- 「粒子群最適化:探索手順、ビジュアライズ」
- 「マシンラーニングによるNBAの給与予測」
- 『リンゴールド・ティルフォードアルゴリ...
- テキストから画像合成を革新する:UCバー...
- 「チャンドラヤーン3の着陸:AIとセンサー...
- グーグルシートでChatGPTを利用する方法
- データサイエンティストのための必須ガイ...
- より小さく、より速い言語モデルのための...
- 「MLX対MPS対CUDA:ベンチマーク」
- 「AIがウクライナの戦場に参戦を望む!」

「ウォールストリートを打ち倒すと誓われた暗号通貨が、その代わりに飲み込まれつつある」
セクターが低迷しており、厳しい新しいSECの監視を受けている中、ウォールストリートの重要なプレイヤーの一部がそれを包み込もうとしています
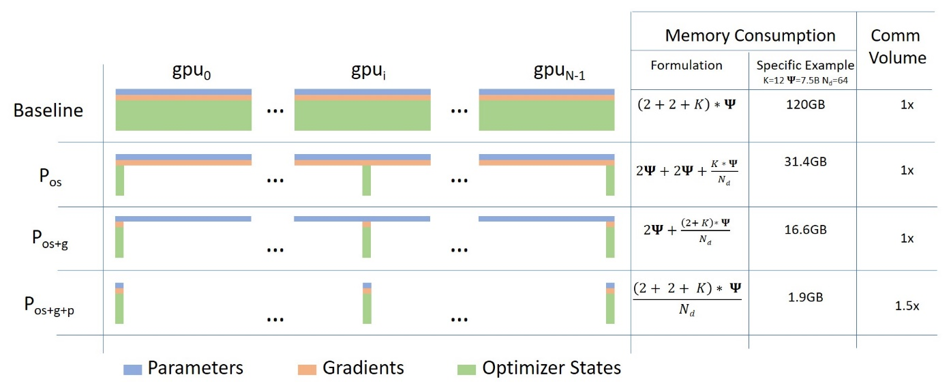
ZeROを使用して、DeepSpeedとFairScaleを介してより多くのフィットと高速なトレーニングを実現
Hugging FaceフェローであるStas Bekmanによるゲストブログ投稿 最近の機械学習モデルは、新しくリリースされたカードに追加されるGPUメモリ量よりもはるかに速く成長しているため、多くのユーザーはこれらの巨大なモデルを自分のハードウェアにトレーニングしたり、ロードしたりすることができません。これらの巨大なモデルをより管理しやすいサイズに縮小するための取り組みが進行中ですが、それらの努力は十分に早く小さなモデルを生み出すことはありません。 2019年の秋に、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong Heが「ZeRO: Memory Optimizations Toward Training Trillion Parameter Models」という論文を発表しました。この論文には、以前に考えられていたよりもハードウェアを遥かに高い性能で動作させるための、多くの独創的なアイデアが含まれています。その後しばらくして、DeepSpeedがリリースされ、その論文のアイデアのほとんどをオープンソースで実装しました(いくつかのアイデアはまだ進行中です)。同時に、FacebookのチームもZeROの論文のいくつかの核心的なアイデアを実装したFairScaleをリリースしました。 Hugging FaceのTrainerを使用している場合、transformers v4.2.0以降、DeepSpeedとFairScaleのZeRO機能の実験的なサポートが提供されています。新しい--sharded_ddpおよび--deepspeedコマンドラインのTrainer引数は、それぞれFairScaleとDeepSpeedの統合を提供します。こちらが完全なドキュメントです。 このブログ投稿では、単一のGPUを所有している場合でも、複数のGPUを所有している場合でも、ZeROの利点をどのように得るかについて説明します。 翻訳タスクの実験として、t5-largeモデルとtransformers GitHubリポジトリのexamples/seq2seq内にあるfinetune_trainer.pyスクリプトを使用して、小規模な微調整を行います。 テストには2つの24GB(Titan RTX)GPUを使用します。…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…

単一のGPUでChatgptのようなチャットボットをROCmで実行する
はじめに ChatGPTは、OpenAIの画期的な言語モデルであり、人工知能の領域で影響力のある存在となり、様々なセクターでAIアプリケーションの多様な活用を可能にしています。その驚異的な人間のようなテキストの理解力と生成力により、ChatGPTは顧客サポートから創造的な文章作成まで、さまざまな産業を変革し、貴重な研究ツールとしても使われています。 OPT、LLAMA、Alpaca、Vicunaなど、大規模な言語モデルのオープンソース化にはさまざまな取り組みが行われていますが、その中でもVicunaはAMD GPU上でROCmを使用してVicuna 13Bモデルを実行する方法を説明します。 Vicunaとは何ですか? Vicunaは、UCバークレー、CMU、スタンフォード、UCサンディエゴのチームによって開発された13兆パラメータを持つオープンソースのチャットボットです。Vicunaは、LLAMAベースモデルを使用して、ShareGPT.comからの約70,000件のユーザー共有会話を収集し、公開APIを介してファインチューニングしました。GPT-4を参照とした初期の評価では、Vicuna-13BはOpenAI ChatGPTと比較して90%以上の品質を実現しています。 それはわずか数週間前の4月11日にGithubでリリースされました。Vicunaのデータセット、トレーニングコード、評価メトリック、トレーニングコストはすべて公開されており、一般のユーザーにとって費用対効果の高いソリューションとなっています。 Vicunaの詳細については、https://vicuna.lmsys.org をご覧ください。 なぜ量子化されたGPTモデルが必要なのですか? Vicuna-13Bモデルをfp16で実行するには、約28GBのGPU RAMが必要です。メモリの使用量をさらに減らすためには、最適化技術が必要です。最近発表された研究論文「GPTQ」では、低ビット精度を持つGPTモデルの正確な事後トレーニング量子化が提案されています。以下の図に示すように、パラメータが10Bを超えるモデルの場合、4ビットまたは3ビットのGPTQはfp16と同等の精度を実現することができます。 さらに、これらのモデルの大きなパラメータは、GPTトークン生成が計算(TFLOPsまたはTOPs)そのものよりもメモリ帯域幅(GB/s)によって制約されるため、GPTのレイテンシに深刻な影響を与えます。そのため、メモリに制約のある状況下では、量子化モデルはトークン生成のレイテンシを低下させません。GPTQの量子化の論文とGitHubリポジトリを参照してください。 この技術を活用することで、Hugging Faceからいくつかの4ビット量子化されたVicunaモデルが利用可能です。 ROCmを使用してAMD GPUでVicuna 13Bモデルを実行する AMD GPUでVicuna 13Bモデルを実行するには、AMD GPUの高速化のためのオープンソースソフトウェアプラットフォームであるROCm(Radeon…

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…

オープンソースAIゲームジャムを発表します 🎮
AIツールを活用して創造力を解放し、週末にゲームを作ろう! 世界初のオープンソースAIゲームジャムをお知らせできることを大変嬉しく思います。このゲームジャムでは、AIツールを使用してゲームを作成します。 AIの可能性によって、ゲームの体験やワークフローが向上することに期待しています。例えば、Stable Diffusionなどの生成型AIツールをゲームやワークフローに取り入れて、新しい機能を開放し、開発プロセスを加速させることができます。 テクスチャ生成からリアルなNPC、現実的なテキスト読み上げまで、選択肢は無限です。 📆 ゲームジャムは7月7日から9日の金曜日から日曜日まで開催されます。 ゲームジャムの無料参加枠を確保しましょう 👉 https://itch.io/jam/open-source-ai-game-jam なぜこのイベントを開催しているのか 一部の人気ゲームジャムがAIツールの使用を制限している時代に、私たちはゲーム開発者がAIが提供する信じられない可能性を紹介するために、特にオープンで透明性のある利用可能なプラットフォームを提供することが重要だと考えています。 私たちはこれらのジャムが繁栄し、インディーゲーム開発者が生産性を向上させ、その可能性を最大限に引き出すためのツールを持つことを望んでいます。 AIツールとは何ですか 特にStable Diffusionなどの生成型AIツールは、ゲーム開発において全く新しい可能性を開拓します。 加速されたワークフローからゲーム内の機能まで、AIの力を使ってテクスチャ生成、リアルなAI非プレイヤーキャラクター(NPC)、現実的なテキスト読み上げ機能を活用することができます。 ゲームジャムの無料参加枠を確保しましょう 👉 https://itch.io/jam/open-source-ai-game-jam 誰が参加できますか オープンソースAIゲームジャムには、スキルレベルや場所に関係なく、誰でも参加できます。 一人で参加することも、任意の人数でチームを組むこともできます。 参加に必要なものは何ですか…

AI音声認識をUnityで
はじめに このチュートリアルでは、Hugging Face Unity APIを使用してUnityゲームに最先端の音声認識を実装する方法を案内します。この機能は、コマンドの実行、NPCへの話しかけ、アクセシビリティの向上、音声をテキストに変換する必要がある他の機能など、さまざまな用途で使用することができます。 自分自身でUnityで音声認識を試してみるには、itch.ioでライブデモをチェックしてください。 前提条件 このチュートリアルでは、Unityの基本的な知識があることを前提としています。また、Hugging Face Unity APIをインストールしている必要があります。APIの設定手順については、以前のブログ記事を参照してください。 手順 1. シーンの設定 このチュートリアルでは、プレイヤーが録音を開始および停止でき、その結果がテキストに変換される非常にシンプルなシーンを設定します。 まず、Unityプロジェクトを作成し、次の4つのUI要素を持つキャンバスを作成します。 開始ボタン:録音を開始します。 停止ボタン:録音を停止します。 テキスト(TextMeshPro):音声認識の結果が表示される場所です。 2. スクリプトの設定 SpeechRecognitionTestという名前のスクリプトを作成し、空のGameObjectにアタッチします。 スクリプト内で、UIコンポーネントへの参照を定義します。 [SerializeField]…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

Transformers.jsを使用してMLを搭載したウェブゲームの作成
このブログ記事では、ブラウザ上で完全に動作するリアルタイムのMLパワードWebゲーム「Doodle Dash」を作成した方法を紹介します(Transformers.jsのおかげで)。このチュートリアルの目的は、自分自身でMLパワードのWebゲームを作成するのがどれだけ簡単かを示すことです… ちょうどOpen Source AI Game Jam(2023年7月7日-9日)に間に合います。まだ参加していない場合は、ぜひゲームジャムに参加してください! ビデオ:Doodle Dashデモビデオ クイックリンク デモ:Doodle Dash ソースコード:doodle-dash ゲームジャムに参加:Open Source AI Game Jam 概要 始める前に、作成する内容について話しましょう。このゲームは、GoogleのQuick, Draw!ゲームに触発されており、単語とニューラルネットワークが20秒以内にあなたが描いているものを推測するというものです(6回繰り返し)。実際には、彼らのトレーニングデータを使用して独自のスケッチ検出モデルを訓練します!オープンソースは最高ですよね? 😍 このバージョンでは、1つのプロンプトずつできるだけ多くのアイテムを1分間で描くことができます。モデルが正しいラベルを予測した場合、キャンバスがクリアされ、新しい単語が与えられます。タイマーが切れるまでこれを続けてください!ゲームはブラウザ内でローカルに実行されるため、サーバーの遅延について心配する必要はありません。モデルはあなたが描くと同時にリアルタイムの予測を行うことができます… 🤯…

データサイエンスの求人探し:就職への道を導いてくれた5冊の本
大変だとわかっています!この困難な時期において、私たちは大きな苦難に直面していることは否定できませんCNNの2023年の解雇追跡データは、現在の状況を鮮明に示しています...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.