Learn more about Search Results ImageNet - Page 11

- You may be interested
- 「大規模言語モデル:現実世界のCXアプリ...
- 「Googleが最新のAIモデルGeminiを発表」
- マイクロソフトAIは、高度なマルチモーダ...
- 2023年5月のVoAGIトップ記事:Mojo Lang:...
- AIと資金調達:資金調達には人間の要素が...
- 「18/9から24/9までの週のトップ重要コン...
- iOSアプリの自然言語処理:機能、Siriの使...
- ChatDev ソフトウェア開発のためのコミュ...
- 韓国の研究者がVITS2を提案:自然さと効率...
- 「ダレ恵3の翻訳に迷い込んで」
- オープンソースのベクトルデータベースChr...
- マシンラーニングに取り組むため、プライ...
- 「受賞者たちは創造的AIのハイプを超えて...
- クエリを劇的に改善できる2つの高度なSQL...
- 芝浦工業大学の研究者たちは、深層学習を...

「セマンティック-SAMに会ってください:ユーザーの入力に基づいて任意の粒度でオブジェクトをセグメント化および認識する、万能な画像セグメンテーションモデル」
人工知能は近年大きく進化しています。現在の開発である大規模言語モデルの導入により、その人間をまねた驚くべき能力が注目されています。これらのモデルは、自然言語処理だけでなく、コンピュータビジョンの分野でも成功を収めています。AIシステムが自然言語処理や制御可能な画像生成で成功を収めている一方、ユニバーサルな画像セグメンテーションを含むピクセルレベルの画像理解の分野にはまだ制限があります。 画像セグメンテーションは、画像を異なるセクションに分割する技術であり、大きな進展が見られていますが、異なる粒度のさまざまな画像を処理できる汎用の画像セグメンテーションモデルの作成はまだ議論中です。この分野での進歩のための主な課題は、適切なトレーニングデータの入手可能性とモデル設計の柔軟性の制約です。既存の手法では、異なる粒度でセグメンテーションマスクを予測し、細部のレベルを処理することができない単一入力、単一出力のパイプラインが頻繁に使用されています。また、セマンティックな情報と粒度の知識を兼ね備えたセグメンテーションデータセットの拡大は高コストです。 これらの制限に対処するため、研究チームはSemantic-SAMという汎用の画像セグメンテーションモデルを開発しました。このモデルは、ユーザーの入力に基づいて任意の粒度でオブジェクトをセグメンテーションし、認識します。モデルはオブジェクトとピースの両方にセマンティックなラベルを提供し、ユーザーのクリックに応じて異なる粒度でマスクを予測することができます。Semantic-SAMのデコーダーアーキテクチャには、複数の選択肢学習戦略が組み込まれており、モデルにさまざまな粒度を処理する能力を与えています。各クリックは複数のクエリで表され、それぞれが異なる埋め込みレベルを持ちます。クエリは異なる粒度の正解マスクから学習するようにトレーニングされます。 研究チームは、Semantic-SAMがパーツとオブジェクトのために分離されたカテゴリ化戦略を使用してセマンティックな認識の問題に取り組む方法を共有しています。モデルは、共有のテキストエンコーダを使用してオブジェクトとパーツを個別にエンコードし、入力タイプに応じて損失関数を変更することで、異なるセグメンテーション手法を可能にします。この戦略により、いくつかのカテゴリ化ラベルが欠落しているSAMデータセットのみならず、一般的なセグメンテーションデータからもデータを処理できるようになります。 チームは、セマンティックと粒度を高めるために、SA-1Bデータセット、PASCAL Part、PACO、PartImagenetなどのパートセグメンテーションデータセット、MSCOCO、Objects365などの一般的なセグメンテーションデータセットを含む7つのデータセットを組み合わせました。データ形式はSemantic-SAMのトレーニング目標に準拠するように再配置されました。 評価とテストの結果、Semantic-SAMは既存のモデルと比較して優れたパフォーマンスを示しました。SA-1Bのプロンプト可能なセグメンテーションやCOCOパノプティックセグメンテーションなどの対話型セグメンテーション技術と組み合わせてトレーニングすると、パフォーマンスが大幅に向上します。このモデルは、2.3のボックスAPゲインと1.2のマスクAPゲインを達成しています。また、粒度の完全性に関して、SAMよりも3.4以上の1-IoUで優れたパフォーマンスを発揮します。 Semantic-SAMは、画像セグメンテーションの分野における革新的な進歩です。このモデルは、ユニバーサルな表現、セマンティックな認識、粒度の豊富さを組み合わせることで、ピクセルレベルの画像分析の新たな可能性を創出します。

「トランスフォーマーを使用した音声からテキストへの完全な入門ガイド」
イントロダクション 私たちは、実際に気づかないうちにオーディオデータに関わっています。世界はオーディオデータと関連する解決すべき問題で溢れており、これらの問題の多くを機械学習を使って解決することができます。画像、テキスト、表形式のデータを使って機械学習モデルを訓練することや、これらのドメインの問題を解決するために機械学習を使うことにはお馴染みかもしれません。Transformerアーキテクチャの登場により、従来の方法よりもはるかに高い精度でオーディオ関連の問題を解決することが可能になりました。本講座では、トランスフォーマーを用いた音声テキスト変換を使用して、オーディオMLの基礎を学び、オーディオ関連の問題を機械学習を用いて解決するためのHuggingfaceライブラリの使用方法を学びます。 学習目標 オーディオ機械学習の基礎と関連する背景知識について学ぶ。 オーディオデータの収集、保存、処理方法について学ぶ。 機械学習を用いた一般的で価値のあるタスクである音声テキスト変換について学ぶ。 オーディオタスクにおいてデータセットやトレーニング済みモデルを探し、それらを使用してHuggingface Pythonライブラリを活用してオーディオ問題を解決する方法について学ぶ。 この記事はData Science Blogathonの一部として公開されました。 背景 Deep Learningの革命が2010年代初頭に起こり、AlexNetが物体認識において人間の専門知識を超えたことから、Transformerアーキテクチャはおそらくそれ以来の最も大きなブレークスルーです。Transformerは以前に解決不可能だったタスクを可能にし、多くの問題の解決を簡素化しました。最初は自然言語翻訳の結果を向上させるために開発されたものでしたが、その後は自然言語処理以外のタスクにも広く採用されるようになりました。例えば、画像に関連するタスクにはViT(Vision Transformers)が適用され、強化学習エージェントの意思決定にはDecision Transformersが使用され、最近の論文ではMagViTというTransformersをビデオに関連するさまざまなタスクに使用する方法が示されています。 これは、Attentionメカニズムを導入した有名な論文Attention is All You Needに始まり、Transformersのアーキテクチャの内部構造を既に知っているとは仮定しません。 一般の開発者やパブリックドメインでは、ChatGPTやGitHub Copilotといった名前が非常に有名ですが、Deep Learningはビジョン、強化学習、自然言語処理など、さまざまな分野で多くの実世界のユースケースで使用されています。…

‘Perceiver IO どんなモダリティにも対応するスケーラブルな完全注意モデル’
TLDR 私たちはPerceiver IOをTransformersに追加しました。これは、テキスト、画像、音声、ビデオ、ポイントクラウドなど、あらゆる種類のモダリティ(それらの組み合わせも含む)に対応した最初のTransformerベースのニューラルネットワークです。以下のスペースをご覧いただくと、いくつかの例をご覧いただけます。 画像間のオプティカルフローの予測 画像の分類。 また、いくつかのノートブックも提供しています。 以下に、モデルの技術的な説明をご覧いただけます。 はじめに Transformerは、元々Vaswaniらによって2017年に紹介され、機械翻訳の最先端(SOTA)の結果を改善するというAIコミュニティでの革命を引き起こしました。2018年には、BERTがリリースされ、トランスフォーマーエンコーダ専用のモデルで、自然言語処理(NLP)のベンチマーク(特にGLUEベンチマーク)を圧倒的に上回りました。 その後まもなくして、AI研究者たちはBERTのアイデアを他の領域にも適用し始めました。以下にいくつかの例を挙げます。 Facebook AIのWav2Vec2は、このアーキテクチャをオーディオに拡張できることを示しました。 Google AIのVision Transformer(ViT)は、このアーキテクチャがビジョンに非常に適していることを示しました。 最近では、Google AIのVideo Vision Transformer(ViViT)もこのアーキテクチャをビデオに適用しました。 これらのすべての領域で、大規模な事前トレーニングとこの強力なアーキテクチャの組み合わせにより、最先端の結果が劇的に改善されました。 ただし、Transformerのアーキテクチャには重要な制約があります。自己注意機構により、計算およびメモリの両方でスケーリングが非常に悪くなります。各レイヤーでは、すべての入力をクエリとキーの生成に使用し、ペアごとのドット積を計算します。したがって、高次元データに自己注意を適用するには、ある形式の前処理が必要です。たとえば、Wav2Vec2では、生の波形を時間ベースの特徴のシーケンスに変換するために、特徴エンコーダを使用してこの問題を解決しています。Vision Transformer(ViT)は、画像を重ならないパッチのシーケンスに分割し、「トークン」として使用します。Video Vision Transformer(ViViT)は、ビデオから重ならない時空間の「チューブ」を抽出し、「トークン」として使用します。Transformerを特定のモダリティで動作させるためには、通常はトークンのシーケンスに離散化する必要があります。…

Gradioを使用して、Spacesで自分のプロジェクトをショーケースしましょう
Gradioを利用することで、機械学習プロジェクトを簡単にデモンストレーションすることができます。 このブログ記事では、以下の内容について説明します: 最近のGradioの統合により、Inference APIを活用してHubからモデルをシームレスにデモンストレーションする方法 Hugging Face Spacesを使用して、独自のモデルのデモをホストする方法 GradioでのHugging Face Hub統合 Hubでモデルを簡単にデモンストレーションすることができます。以下を含むインターフェースを定義するだけでOKです: 推論を行いたいモデルのリポジトリID 説明とタイトル オーディエンスをガイドするための入力例 インターフェースを定義したら、.launch()を呼び出すだけでデモが開始されます。これはColabで行うこともできますが、コミュニティと共有する場合はSpacesを使用するのがおすすめです! SpacesはPythonでMLデモアプリを簡単にホストするための無料の方法です。Spacesを使用するには、https://huggingface.co/new-space にリポジトリを作成し、SDKとしてGradioを選択します。作業が完了すると、app.pyというファイルを作成し、下のコードをコピーするだけで、数秒でアプリを起動できます! import gradio as gr description = "GPT-2によるストーリー生成"…
機械学習の時代がコードとして到来しました
2021年版のState of AIレポートが先週発表されました。そして、Kaggle State of Machine Learning and Data Science Surveyも同様です。これらのレポートには学びや議論の余地がたくさんありますが、いくつかのポイントが私の注意を引きました。 「AIはますます国家の電力網やパンデミック中の自動スーパーマーケットの倉庫計算など、ミッションクリティカルなインフラに適用されています。しかし、成熟度が急速に成長する展開の巨大さに追いついているかどうかについては疑問があります。」 機械学習を活用したアプリケーションがITのあらゆる分野に広がっていることは否定できません。しかし、それは企業や組織にとってどういう意味を持つのでしょうか?どのように堅牢な機械学習ワークフローを構築すれば良いのでしょうか?私たちは皆、100人のデータサイエンティストを採用すべきなのでしょうか?それとも100人のDevOpsエンジニアを採用すべきなのでしょうか? 「トランスフォーマーは、自然言語処理だけでなく、音声、コンピュータビジョン、さらにはタンパク質の構造予測など、機械学習の一般的なアーキテクチャとして登場しています。」 古参の人々は、ITには銀の弾丸はないということを痛感してきました。それでも、トランスフォーマーのアーキテクチャは、さまざまな機械学習タスクにおいて非常に効率的です。しかし、機械学習の革新の猛烈なペースにどうやってついていけば良いのでしょうか?これらの最先端モデルを活用するためには、本当に専門的なスキルが必要なのでしょうか?それとももっと短い道でビジネス価値を創出する方法があるのでしょうか? さて、私の考えはこうです。 マス向け機械学習! 機械学習はどこにでもあります、少なくともそうしようとしています。数年前、Forbesは「ソフトウェアが世界を食べた、今度はAIがソフトウェアを食べる」と書きましたが、これは実際にはどういう意味なのでしょうか?もし、それが機械学習モデルが何千行もの化石化した旧式のコードを置き換えるべきだという意味なら、私は全面賛成です。邪悪なビジネスルールよ、死ね! では、機械学習が実際にソフトウェアエンジニアリングを置き換えるということでしょうか?現在、AIが生成したコードについて幻想が広がっており、バグやパフォーマンスの問題を見つけるなど、いくつかの技術は確かに興味深いものです。しかし、開発者を廃止することは考えるべきではありませんし、むしろ多くの開発者を力強くサポートするために取り組むべきです。そうすれば、機械学習はただの別の退屈なITのワークロードになるでしょう(退屈なテクノロジーは素晴らしいです)。言い換えれば、私たちが本当に必要としているのは、ソフトウェアが機械学習を食べることなのです! 今回も変わらない 私は長年にわたり、ソフトウェアエンジニアリングの10年以上前のベストプラクティスがデータサイエンスや機械学習にも適用されると主張してきました。バージョン管理、再利用性、テスト可能性、自動化、デプロイメント、モニタリング、パフォーマンス、最適化などです。しばらくは孤独だったのですが、予想外にGoogleの連携がありました: 「機械学習は、あなたが偉大な機械学習の専門家ではなく、偉大なエンジニアとして機械学習を行うべきです。」- 『機械学習のルール』、Google また、車輪を再発明する必要はありません。DevOpsの運動はこれらの問題を10年以上前に解決しました。今や、データサイエンスと機械学習コミュニティは、これらの実証済みのツールとプロセスを遅延なく採用し、適応させるべきです。これが唯一の方法であり、本番環境で堅牢でスケーラブルかつ繰り返し可能な機械学習システムを構築することができます。もしMLOpsと呼ぶことが助けになるのなら、それも構いません:別のバズワードについて議論するつもりはありません。…

カスタムデータセットでセマンティックセグメンテーションモデルを微調整する
このガイドでは、最先端のセマンティックセグメンテーションモデルであるSegformerのファインチューニング方法を紹介します。私たちの目標は、ピザ配達ロボットのためのモデルを構築することで、それによってロボットがどこに進むべきかを見ることができ、障害物を認識できるようにすることです 🍕🤖。最初に、Segments.aiで一連の歩道の画像にラベルを付けます。次に、🤗 transformersというオープンソースのライブラリを使用して、事前学習済みのSegFormerモデルをファインチューニングします。このライブラリは、最先端のモデルの簡単な実装を提供しています。このプロセスで、最大のオープンソースのモデルとデータセットのカタログであるHugging Face Hubの使用方法も学びます。 セマンティックセグメンテーションは、画像内の各ピクセルを分類するタスクです。これはより正確な画像の分類方法と見なすことができます。医療画像や自動運転など、さまざまな分野で幅広い用途があります。例えば、ピザ配達ロボットの場合、画像内の歩道がどこにあるか正確に知ることが重要です。 セマンティックセグメンテーションは分類の一種であるため、画像分類とセマンティックセグメンテーションに使用されるネットワークアーキテクチャは非常に似ています。2014年、Longらによる画像セグメンテーションのための異彩を放つ論文では、畳み込みニューラルネットワークが使用されています。最近では、画像分類にTransformers(例:ViT)が使用されており、最新のセマンティックセグメンテーションにも使用されており、最先端の技術をさらに押し上げています。 SegFormerは、2021年にXieらによって提案されたセマンティックセグメンテーションのモデルです。ポジションエンコーディングを使用しない階層的なトランスフォーマーエンコーダと、単純な多層パーセプトロンデコーダを持っています。SegFormerは、複数の一般的なデータセットで最先端の性能を実現しています。さあ、ピザ配達ロボットが歩道の画像でどのようにパフォーマンスを発揮するか見てみましょう。 必要な依存関係をインストールして始めましょう。データセットとモデルをHugging Face Hubにプッシュするために、Git LFSをインストールし、Hugging Faceにログインする必要があります。 git-lfsのインストール方法は、お使いのシステムによって異なる場合があります。Google ColabにはGit LFSが事前にインストールされていることに注意してください。 pip install -q transformers datasets evaluate segments-ai apt-get…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

TF Servingを使用してHugging FaceでTensorFlow Visionモデルを展開する
過去数ヶ月間、Hugging Faceチームと外部の貢献者は、TransformersにさまざまなビジョンモデルをTensorFlowで追加しました。このリストは包括的に拡大しており、ビジョントランスフォーマー、マスク付きオートエンコーダー、RegNet、ConvNeXtなど、最先端の事前学習モデルがすでに含まれています! TensorFlowモデルを展開する際には、さまざまな選択肢があります。使用ケースに応じて、モデルをエンドポイントとして公開するか、アプリケーション自体にパッケージ化するかを選択できます。TensorFlowには、これらの異なるシナリオに対応するツールが用意されています。 この投稿では、TensorFlow Serving(TF Serving)を使用してローカルでビジョントランスフォーマーモデル(画像分類用)を展開する方法を紹介します。これにより、開発者はモデルをRESTエンドポイントまたはgRPCエンドポイントとして公開できます。さらに、TF Servingはモデルのウォームアップ、サーバーサイドバッチ処理など、多くの展開固有の機能を提供しています。 この投稿全体で示される完全な動作するコードを取得するには、冒頭に示されているColabノートブックを参照してください。 🤗 TransformersのすべてのTensorFlowモデルには、save_pretrained()というメソッドがあります。このメソッドを使用すると、モデルの重みをh5形式およびスタンドアロンのSavedModel形式でシリアライズできます。TF Servingでは、モデルをSavedModel形式で提供する必要があります。そこで、まずビジョントランスフォーマーモデルをロードして保存します。 from transformers import TFViTForImageClassification temp_model_dir = "vit" ckpt = "google/vit-base-patch16-224" model = TFViTForImageClassification.from_pretrained(ckpt)…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…
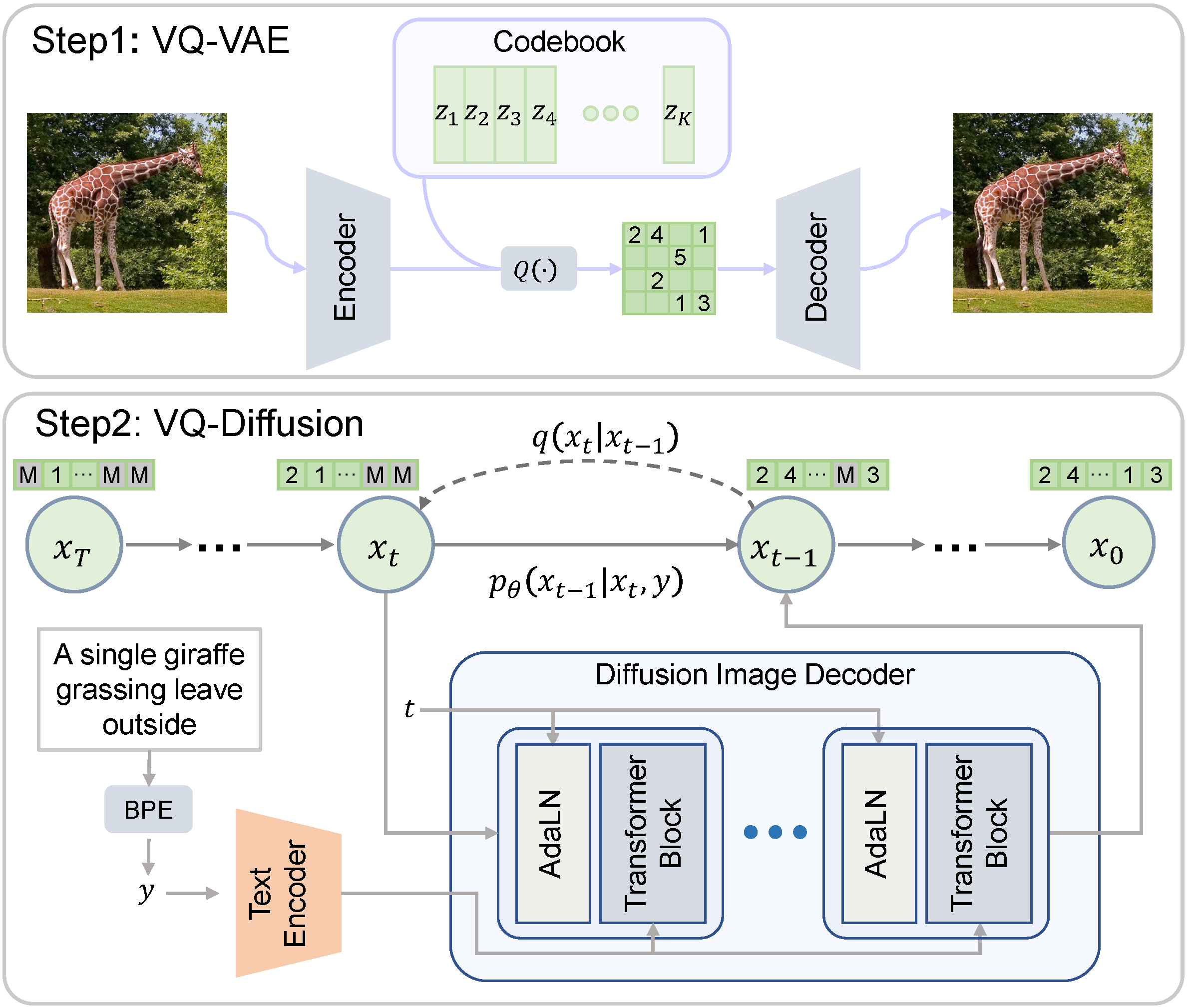
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.