Learn more about Search Results Discord - Page 11

- You may be interested
- 遺伝的アルゴリズムを使用したPythonによ...
- 「AIが研究論文内の問題のある画像を見つ...
- 「あなたの聴衆を知る:テクニカルプレゼ...
- 南開大学と字節跳動の研究者らが『ChatAny...
- 「このAI研究は微生物学者が細菌を識別す...
- 「AIシステムへの9つの一般的な攻撃のタイ...
- 「LLMsが幻覚を見るのを止めることはでき...
- AWS SageMaker JumpStart Foundation Mode...
- 何が合成データとは?その種類、機械学習...
- ChatGPTによるデータサイエンス面接チート...
- LLMOPS vs MLOPS AI開発における最良の選...
- データプロジェクトが現実的な影響をもた...
- このAI論文では、LLMsの既存のタスクの新...
- 「ゴミを入れればゴミが出る:AIにおける...
- 「DeepSeek:中国最新の言語モデルの支配」
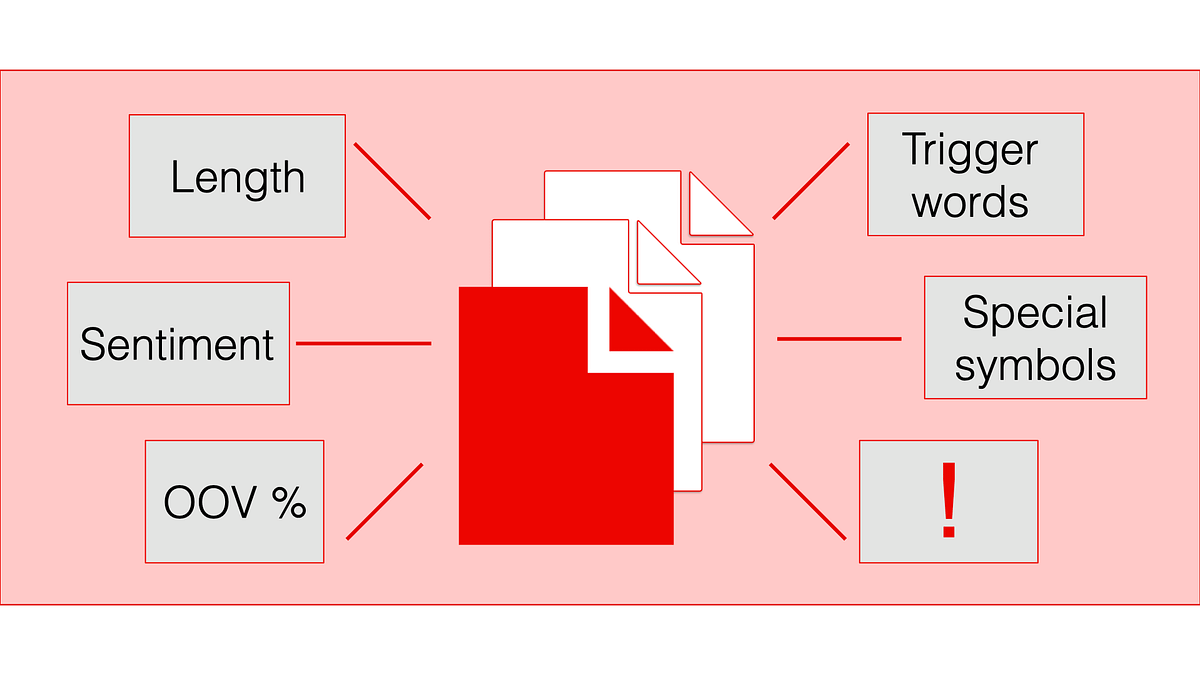
「LLMとNLPのための非構造化データの監視」
「NLPまたはLLMベースのソリューションを展開した後、それを追跡する方法が必要ですしかし、テキストの山を理解するために非構造化データを監視するにはどうすればよいでしょうか? ここではいくつかのアプローチがあります...」

「シエラディビジョンがNVIDIA Omniverseを使用して作成した3つのエピックなプロジェクトを紹介します」
エディター注:この投稿は、毎週のNVIDIAスタジオシリーズの一部であり、注目のアーティストを称え、クリエイティブのヒントやトリックを提供し、NVIDIAスタジオテクノロジーがクリエイティブのワークフローを改善する方法を示しています。また、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて詳しく説明し、コンテンツ作成を劇的に加速する方法について詳しく説明します。 Jacob Norrisは、3Dアーティストであり、Sierra Division Studiosの社長、共同創設者、クリエイティブディレクターです。Sierra Division Studiosは、デジタル3Dコンテンツ作成に特化したアウトソーススタジオです。このスタジオは、最高水準で画期的なアートワークを作り出すことを目標に設立されました。 彼のチームは完全にリモートであり、従業員は世界中のどこからでも柔軟に働くことができます。これにより、スタジオが利用できる経験とスキルセットを持つ潜在的なアーティストのプールが増えます。 ノリス氏は、場所や時間、さらには言語に関係なく、信じられないほどの3Dコンテンツが作成される未来を想像していると述べています。それは、3Dツールとメタバースアプリケーションを接続し、カスタム3Dツールとメタバースアプリケーションを構築するためのプラットフォームであるNVIDIA Omniverseが重要な役割を果たす未来です。 Omniverseは、SimReadyアセットを作成するための強力なツールでもあります。SimReadyアセットとは、正確な物理特性を持つ3Dオブジェクトのことです。これらのアセットを合成データと組み合わせることで、AIパワードの3Dアーティストを含むシミュレーションの現実世界の問題を解決するのに役立ちます。NVIDIAスタジオのクリエイティブなサイドハッスルページで、AIについて詳しく学び、クリエイティブなリソースにアクセスして情熱プロジェクトをレベルアップさせる方法について詳しく説明します。 さらに、新しいコミュニティチャレンジ「#StartToFinish」もチェックしてください。このハッシュタグを使用して、お気に入りのプロジェクトの始まりと終わりのスクリーンショットを投稿し、@NVIDIAStudioと@NVIDIAOmniverseのソーシャルチャネルで紹介されるチャンスを得ることができます。 新しい「#StartToFinish」チャレンジへようこそ。 あなたのアートプロジェクトの始まりと最終結果の写真/ビデオを投稿し、#StartToFinishタグを付けて参加してください。 @rafianimatesが@NVIDIAOmniverseで作成したこれらの素晴らしい例をチェックしてください。 pic.twitter.com/z9v656oQ2Q — NVIDIA Studio(@NVIDIAStudio)2023年7月10日 Omniverseを活用した普遍的な作業 「Omniverseは、協力プロセスにおいて私たちのチームにとって非常に強力なツールです」とノリス氏は語ります。彼は、Universal Scene…
「Sierra DivisionがNVIDIA Omniverseを使用して開発した3つの壮大なプロジェクトを紹介します」
編集者コメント:この投稿は、毎週のNVIDIA Studioシリーズの一部であり、注目のアーティストを称え、クリエイティブなヒントやトリックを提供し、NVIDIA Studioテクノロジーがクリエイティブなワークフローを向上させる方法を実証します。さらに、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて詳しく調査し、コンテンツ作成を劇的に加速する方法について深く掘り下げます。 Jacob Norrisは、3Dアーティストであり、Sierra Division Studiosの社長、共同創設者、クリエイティブディレクターでもあります。Sierra Division Studiosは、デジタル3Dコンテンツ作成に特化したアウトソーススタジオです。このスタジオは、最高レベルで画期的なアートを作るという目標を持って設立されました。 彼のチームは完全にリモートであり、従業員は世界中のどこからでも柔軟に働くことができます。これにより、スタジオが利用できる様々な経験とスキルを持つ見込みのあるアーティストのプールが増えます。 ノリスは、NVIDIA Omniverseが重要な役割を果たす未来を想像しています。NVIDIA Omniverseは、3Dツールとメタバースアプリケーションを接続および構築するプラットフォームです。彼は、場所や時間、さらには言語に関係なく、信じられないほどの3Dコンテンツが作成される未来を描いています。 Omniverseは、SimReadyアセットの作成にも強力なツールです。SimReadyアセットとは、正確な物理特性を持つ3Dオブジェクトのことです。これらのアセットは、合成データと組み合わせることで、AIによる3Dアーティストのシミュレーションを含む現実世界の問題を解決するのに役立ちます。NVIDIA StudioのクリエイティブなサイドハッスルページでAIについて詳しく学び、創造的なリソースにアクセスして情熱のプロジェクトを次のレベルに引き上げる方法についてもっと知りましょう。 さらに、新しいコミュニティチャレンジ「#StartToFinish」もチェックしてください。このハッシュタグを使用して、お気に入りのプロジェクトの始まりと終わりのステージを両方フィーチャーしたスクリーンショットを投稿し、@NVIDIAStudioと@NVIDIAOmniverseのソーシャルチャンネルにショーケースされるチャンスを得ることができます。 新しい「#StartToFinish」チャレンジへようこそ。 アートプロジェクトの始まりと最終結果の写真/動画を投稿し、#StartToFinishをタグ付けして参加してください。 @NVIDIAOmniverseの#OpenUSDで作成された、@rafianimatesによる素晴らしい例をご覧ください。 pic.twitter.com/z9v656oQ2Q — NVIDIA…
シエラディビジョンは、NVIDIA Omniverseを使用して作成された3つの壮大なプロジェクトを発表します
編集者の注:この投稿は、私たちの週刊「NVIDIA Studio」シリーズの一部であり、注目のアーティストを称え、クリエイティブなヒントやトリックを提供し、NVIDIA Studioテクノロジーがクリエイティブなワークフローを改善する方法を実証しています。また、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて詳しく説明し、それらがコンテンツの作成を劇的に加速する方法についても深く掘り下げます。 Jacob Norrisは、3Dアーティストであり、Sierra Division Studiosの社長、共同創設者、クリエイティブディレクターでもあります。Sierra Division Studiosは、デジタル3Dコンテンツの制作に特化した外注スタジオです。このスタジオは、最高レベルで画期的なアートワークを作り出すことを目標に設立されました。 彼のチームは完全にリモートで働いており、従業員にはどこからでも働く柔軟性があります。これにより、スタジオが利用できる経験やスキルセットの広範な範囲を持つ見込みのアーティストのプールが増えます。 ノリスは、場所や時間、さらには言語に関係なく、信じられないほどの3Dコンテンツが作成される未来を想像しています。これは、カスタムな3Dツールやメタバースアプリケーションを接続および構築するためのプラットフォームであるNVIDIA Omniverseが重要な役割を果たす未来です。 Omniverseは、SimReadyアセットの作成にも強力なツールです。SimReadyアセットとは、正確な物理的特性を持つ3Dオブジェクトのことです。これらのアセットは、合成データと組み合わせることで、AIを搭載した3Dアーティストのためのシミュレーションを含む現実世界の問題の解決に役立ちます。NVIDIA Studioのクリエイティブな一面の副業ページで、AIについての詳細を学び、情熱的なプロジェクトのレベルアップに役立つクリエイティブリソースにアクセスしてください。 さらに、新しいコミュニティチャレンジ「#StartToFinish」もチェックしてください。このハッシュタグを使用して、お気に入りのプロジェクトの始まりと終わりのステージを示すスクリーンショットを投稿し、@NVIDIAStudioと@NVIDIAOmniverseのソーシャルチャンネルで紹介されるチャンスを得ることができます。 新しい「#StartToFinish」チャレンジへようこそ。 アートプロジェクトの始まりと最終結果の写真/ビデオを表示して、#StartToFinishをタグ付けして参加してください。 次は、@rafianimatesが@NVIDIAOmniverseで#OpenUSDを使用して作成した素晴らしい例です。 pic.twitter.com/z9v656oQ2Q — NVIDIA Studio…
このAIニュースレターは、あなたが必要とするすべてです #55
今週、私たちはついにOpen AIのCode Interpreterをテストすることができ、ChatGPT内のGPT-4の新機能に興奮していましたOpenAIは他の発表も行い、その計画を明らかにしました...
このAIニュースレターは、あなたが必要な全てです #55
今週は、ついにOpen AIのCode Interpreterをテストする機会を得て、とても興奮しましたこれは、ChatGPT内のGPT-4の新しい機能ですOpenAIは他にも発表があり、その中で...

Google Cloud上のサーバーレストランスフォーマーパイプラインへの私の旅
コミュニティメンバーのマクサンス・ドミニシによるゲストブログ投稿 この記事では、Google Cloudにtransformers感情分析パイプラインを展開するまでの道のりについて説明します。まず、transformersの簡単な紹介から始め、実装の技術的な部分に移ります。最後に、この実装をまとめ、私たちが達成したことについてレビューします。 目標 Discordに残された顧客のレビューがポジティブかネガティブかを自動的に検出するマイクロサービスを作成したかったです。これにより、コメントを適切に処理し、顧客の体験を向上させることができます。たとえば、レビューがネガティブな場合、顧客に連絡し、サービスの品質の低さを謝罪し、サポートチームができるだけ早く連絡し、問題を修正するためにサポートすることができる機能を作成できます。1か月あたり2,000件以上のリクエストは予定していないため、時間と拡張性に関してはパフォーマンスの制約を課しませんでした。 Transformersライブラリ 最初に.h5ファイルをダウンロードしたとき、少し混乱しました。このファイルはtensorflow.keras.models.load_modelと互換性があると思っていましたが、実際にはそうではありませんでした。数分の調査の後、ファイルがケラスモデルではなく重みのチェックポイントであることがわかりました。その後、Hugging Faceが提供するAPIを試して、彼らが提供するパイプライン機能についてもう少し調べました。APIおよびパイプラインの結果が素晴らしかったため、自分自身のサーバーでモデルをパイプラインを通じて提供することができると判断しました。 以下は、TransformersのGitHubページの公式の例です。 from transformers import pipeline # 感情分析のためのパイプラインを割り当てる classifier = pipeline('sentiment-analysis') classifier('We are very happy to include…

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

スノーボールファイト ☃️をご紹介しますこれは私たちの最初のML-Agents環境です
私たちは、初めてのカスタムDeep Reinforcement Learning環境:Snowball Fight 1vs1 🎉を共有できることを嬉しく思います。 Snowball Fightは、Unity ML-Agentsを使用して作成されたゲームで、Deep Reinforcement Learningエージェントに対して雪玉を撃つことができます。このゲームはHugging Face Spacesでホストされています。 👉オンラインでプレイすることができます この投稿では、Unity ML-Agentsを使用するDeep Reinforcement Learning研究者や愛好家向けのエコシステムについて説明します。 Hugging FaceのUnity ML-Agents Unity Machine Learning…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.