Learn more about Search Results 6 - Page 11

- You may be interested
- KITE(キーポイントを視覚的な基盤と正確...
- 「IntelのOpenVINOツールキットを使用した...
- Googleの研究者たちは、AIによって生成さ...
- 「LangChainとOpenAI APIを使用した生成型...
- 「Voicemod AIで自分自身のAIボイスを作成...
- 研究者がCODES+ISSS最優秀論文賞を受賞し...
- 現実世界における機械学習エンジニアリング
- ODSC West 2023の基調講演:責任ある生成A...
- あなたのGen AIプロジェクトで活用するた...
- あなたのプロジェクトに最適な5つのデータ...
- 「Keras 3.0 すべてを知るために必要なこと」
- AI増強ソフトウェアエンジニアリング:知...
- ブランチアンドバウンド-ボーナス記事-ノ...
- 「ヒューメインのAIピンは、ウェアラブル...
- VQ-Diffusion

仕事を加速するAIツール16選
モーション モーションは、人々の会議、タスク、プロジェクトを考慮した日々のスケジュールを作成するためにAIを利用する賢いツールです。計画の手間を省き、生産性の高い生活を送るために、さようならを言いましょう。 BeforeSunset AI 効果的な時間管理を支援するために、BeforeSunset AIは人工知能を活用しています。手作業のやるべきことリストの頭痛や曖昧さを排除することで、計画プロセスを効率化します。ジョブを「実行可能な」アイテムに変換し、大きなプロジェクトを小さなものに分割し、チームミーティングのための時間を推奨するなど、ツールの機能はすべて、効率と秩序の向上に寄与しています。BeforeSunset AIは、計画能力を向上させるための個人の分析情報を提供します。ユーザーは週間や日々のカレンダーを確認して、自分の仕事の習慣と生産性について学ぶことができます。これにより、最も効果的に時間を使う方法について貴重な洞察を得ることができます。タイムモニタリング、ノートキープ、タスクの履歴、目標設定など、このプログラムが提供する機能はいくつかあります。ユーザーは自分が何をしてきたかを把握し、大きなプロジェクトを小さなものに分割し、自分がどれだけ進んできたかを確認することができます。BeforeSunset AIは、チームビルディングや調整などの将来の機能も提供します。 Notion Notionは、高度なAI技術を活用してユーザー数を増やすことを目指しています。最新の機能であるNotion AIは、ユーザーがノートの要約、ミーティングでのアクションアイテムの特定、テキストの作成と編集などのタスクを補助する強力な生成AIツールです。Notion AIは、退屈なタスクを自動化し、ユーザーに提案やテンプレートを提供することで、ワークフローを効率化し、ユーザーエクスペリエンスを簡素化し改善します。 AdCreative.ai AdCreative.aiは、究極の人工知能ソリューションであることで、広告とソーシャルメディアのゲームを向上させます。創造的な作業に数時間を費やすのにさようならを言いましょう。数秒で生成される高変換率の広告とソーシャルメディアの投稿を歓迎しましょう。AdCreative.aiを使って成功を最大化し、努力を最小限にしましょう。 Otter AI Otter.AIは、人工知能を利用して、共有可能で検索可能でアクセス可能で安全な会議のメモのリアルタイムな文字起こしを提供します。オーディオを録音し、メモを書き、スライドを自動的にキャプチャし、要約を生成する会議アシスタントを手に入れましょう。 Aragon Aragonを使って努力をかけずに素晴らしいプロフェッショナルなヘッドショットを手に入れましょう。最新のAI技術を活用して、瞬時に自分自身の高品質なヘッドショットを作成しましょう!写真スタジオの予約や着飾る手間を省きましょう。写真の編集と修正を迅速に行いましょう。次の仕事を手に入れるための優位性を持つ40枚のHD写真を受け取りましょう。 Postfluencer Postfluencerは、自動的にLinkedInの更新を作成するAIパワードソフトウェアです。このソフトウェアは、プロフェッショナルなソーシャルメディアプラットフォームで魅力的なコンテンツを共有するための簡単で効率的な手段を提供します。ユーザーは簡単に素材を入力し、Matt BarkerのPCRフレームワーク、ClearPAIPS、Story、Hero’s Journey、Simpleなどのいくつかのオプションから好みのフレームワークを選択することができます。リスト形式や標準の段落など、他の投稿形式の選択肢もあります。ユーザーは簡単に投稿を変更して、さまざまなコンテンツガイドラインや対象読者の好みに合わせることができます。ツールによってハッシュタグも含めた完成した投稿が生成されます。Postfluencerの背後にあるテクノロジーは、人工知能のリーダーであるOpenAIが提供しています。OpenAIの最先端のAI技術のおかげで、Postfluencerの投稿生成能力は正確で効率的です。この機能を利用することで、LinkedInのユーザーはネットワーク向けに魅力的なコンテンツを開発する際に、膨大な時間と労力を節約することができます。 Parsio(OCR…

メタAIは、IMAGEBINDを紹介します:明示的な監督の必要性なく、一度に6つのモダリティからデータを結合できる最初のオープンソースAIプロジェクトです
人間はわずかなインスタンスにさらされた後で複雑なアイデアを理解することができます。ほとんどの場合、書かれた説明に基づいて動物を特定し、視覚に基づいて未知の自動車のエンジンの音を推測することができます。これは、単一の画像がそれ以外の感覚的な経験を「結びつける」ことができるためです。ペアデータに基づく標準的なマルチモーダル学習は、モダリティの数が増えるにつれて制約があります。 テキスト、音声などをイメージに合わせることは、最近のいくつかの手法の焦点となっています。これらの戦略は最大でも2つの感覚を使用します。ただし、最終的な埋め込みは、トレーニングモダリティとそれらに対応するペアのみを表すことができます。そのため、ビデオ-オーディオの埋め込みを直接的にイメージ-テキストの活動に転送したり、その逆を行うことはできません。すべてのモダリティが一緒に存在する巨大なマルチモーダルデータが欠けていることは、実際の共有埋め込みを学習するための重要な障壁です。 新しいメタリサーチは、複数の形式の画像ペアデータを使用して単一の共有表現空間を学習するためのIMAGEBINDというシステムを紹介しています。すべてのモダリティが同時に発生するデータセットを使用する必要はありません。代わりに、この研究では画像の結合特性を利用し、各モダリティの埋め込みを画像の埋め込みに合わせることで、すべてのモダリティ間での新たなアライメントが生じることを示しています。 ウェブ上の大量の画像と関連するテキストは、画像-テキストモデルのトレーニングに大きな影響を与えています。ImageBindは、画像が他のモダリティと頻繁に共起するという事実を利用し、テキストと画像をオンラインデータでリンクしたり、モーションと動画をIMUセンサーを搭載したウェアラブルカメラから取得したビデオデータでリンクするなど、それらを接続する橋として機能することができます。 モダリティ間の特徴学習のターゲットは、ウェブデータから学習された視覚的表現です。これは、ImageBindが画像と頻繁に共起する他のモダリティもアライメントできることを意味します。ヒートや深さなどのモダリティのアライメントは、画像と高い相関関係を持つため、より簡単です。 ImageBindは、単にペアの画像を使用するだけで、すべての6つのモダリティを統合することができます。このモデルは、さまざまなモダリティ同士が「話し合い」、直接の観察を必要とせずに接続を見つけ出すことで、情報のより包括的な解釈を提供することができます。たとえば、ImageBindは、音とテキストをリンクさせることができますが、それらを一緒に見ることはできません。これにより、他のモデルは、広範な時間とエネルギーを必要とするトレーニングなしで新しいモダリティを「理解」することができます。ImageBindの堅牢なスケーリング動作により、以前は追加のモダリティを使用できなかった多くのAIモデルの代わりまたは追加として、このモデルを使用することが可能になります。 大規模な画像-テキストのペアデータと自己教師ありデータを組み合わせることで、音声、深度、熱、慣性計測装置(IMU)の読み取りなど、4つの新しいモダリティにわたる特徴学習の強力なエマージェントゼロショット分類および検索パフォーマンスが示されています。チームは、基礎となる画像表現の強化がこれらのエマージェントフィーチャーを向上させることを示しています。 調査結果は、IMAGEBINDのエマージェントゼロショット分類が、ESC、Clotho、AudioCapsなどのオーディオ分類および検索ベンチマークで専門家モデルと同等または優れていることを示しています。フューショット評価ベンチマークでは、IMAGEBINDの表現も専門家指導モデルよりも優れたパフォーマンスを発揮します。最後に、IMAGEBINDの共有埋め込みの多様な構成タスクでの汎用性を示すために、クロスモーダル検索、埋め込みの算術組み合わせ、画像への音声入力からの画像生成などを行います。 これらの埋め込みは特定のアプリケーションに対してトレーニングされていないため、ドメイン固有のモデルの効率には及びません。チームは、汎用的な埋め込みを特定の目的に合わせる方法についてさらに学ぶことが有益だと考えています。たとえば、検出などの構造化予測タスクに対して。
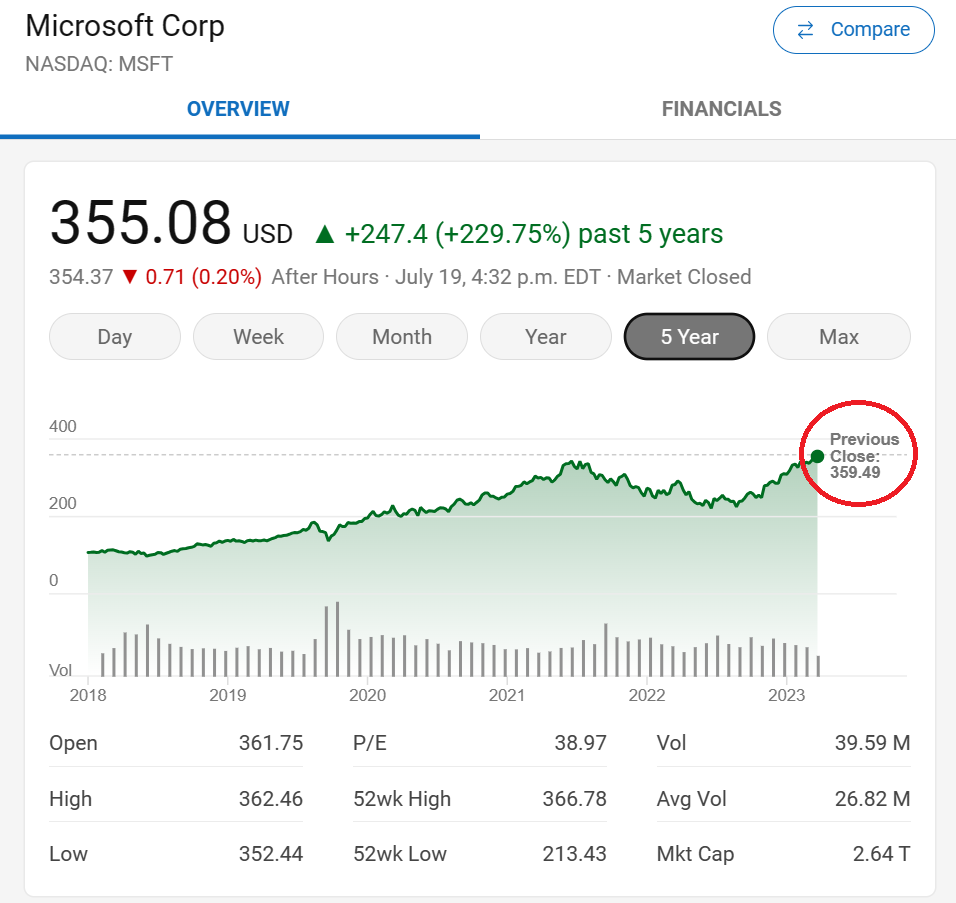
生産性のパラノイアを打破する:Microsoft 365コパイロットには賛成ですか?
Microsoft 365 Copilotは30ドルで価格設定されていますこれは多くの企業にとって、Microsoftのサブスクリプションに対する現在の支出を倍増、あるいは3倍にする可能性があります(The Verge、2023年7月18日)あなたは…
類似検索、パート6:LSHフォレストによるランダム射影
「類似検索」とは、クエリが与えられた場合に、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目指す問題ですデータサイエンスにおいては、類似検索はしばしばNLP(自然言語処理)で現れます...

「このAI論文は、ChatGPTにペルソナを割り当てると、毒性が最大6倍に増加することを示しています」
最近の技術の進歩により、GPT-3やPaLMなどの大規模言語モデル(LLM)は、教育、コンテンツ制作、医療、研究などの様々な領域で驚くべき生成能力を発揮しています。これらの大規模言語モデルは、ライターが執筆スタイルを向上させるのに特に役立ち、新人開発者がひな型のコードを生成するのを支援するのにも役立ちます。さらに、いくつかのサードパーティAPIの利用可能性と組み合わせることで、LLMの普及は、学生や病院で使用される医療システムなど、複数の顧客向けシステムでさらに増加しています。しかし、このようなシナリオでは、これらのシステムの安全性が個人情報を頼りに信頼される基本的な問題となります。これにより、LLMの異なる能力と制約についてより明確な情報を得る必要があります。 しかし、以前の多くの研究は、より高度で洗練されたアーキテクチャを採用することで、LLMをより強力にすることに焦点を当ててきました。この研究はNLPコミュニティを大きく超越していますが、これによりこれらのシステムの安全性が脇に追いやられています。そのため、プリンストン大学とジョージア工科大学のポストドクトラル研究員が、AI研究所の研究者と協力して、OpenAIの革新的なAIチャットボットChatGPTの毒性分析を行い、このギャップを埋めることにしました。研究者たちは、ChatGPTの約50万回の生成で毒性を評価し、その調査の結果、ChatGPTのシステムパラメータがパーソナリティを割り当てられた場合、様々なトピックに対して毒性が多倍に増加することが明らかになりました。たとえば、ChatGPTのパーソナリティがボクサーの「Muhammad Ali」に設定された場合、デフォルト設定と比較して毒性が約3倍に増加します。これは特に深刻な問題であり、ChatGPTは現在、同じレベルの毒性を生成することができる他のいくつかの技術を構築する基盤として使用されています。したがって、A2Iの研究者と大学生が行った研究は、異なるパーソナリティが割り当てられた場合のChatGPTの毒性生成についてより深い洞察を得ることに焦点を当てています。 ChatGPT APIは、ユーザーがシステムパラメータを設定することでパーソナリティを割り当てる機能を提供しており、パーソナリティはChatGPTの会話のトーンを設定し、ChatGPTの会話方法に影響を与えます。研究者たちは、起業家、政治家、ジャーナリストなどの異なるバックグラウンドや国からなる90人のパーソナリティリストを編集し、ChatGPTに割り当てて、性別、宗教、職業など約128の重要なエンティティについての応答を分析しました。チームはまた、ChatGPTにこれらのエンティティに関する特定の不完全なフレーズを続けるように依頼して、さらなる洞察を集めました。最終的な調査結果は、ChatGPTにパーソナリティを割り当てることで、その毒性が最大で6倍に増加することを示し、ChatGPTが頻繁に厳しい出力を生成し、否定的なステレオタイプや信念に傾倒することを示しました。 チームの研究は、ChatGPTが与えられたパーソナリティに応じて出力の毒性が大きく異なることを示しました。これは、ChatGPTがそのトレーニングデータに基づいて人物を理解しているためだと研究者たちは推測しています。たとえば、ジャーナリストは実際のケースではなくても、ビジネスパーソンよりも2倍毒性があるという発見がありました。この研究はまた、特定の人口やエンティティが他よりも頻繁に(約3倍)標的にされることを示し、モデルの差別的な振る舞いを示しています。たとえば、毒性は人物の性別によって異なり、人種に基づく毒性よりも約50%高いです。これらの変動傾向は、ユーザーにとって損害を与え、対象となる個人にとって侮辱的なものになり得ます。さらに、悪意のあるユーザーはChatGPT上に技術を構築することができ、無疑の観客に害を及ぼす可能性のあるコンテンツを生成することができます。 この研究のChatGPTの毒性分析は主に次の3つのことを明らかにしました:パーソナリティが割り当てられた場合、モデルは著しく毒性が増加する(デフォルトの場合と比較して最大6倍も毒性が増加する)、モデルの毒性はパーソナリティのアイデンティティによって大きく異なり、ChatGPTのパーソナリティに対する意見が重要な役割を果たす。さらに、ChatGPTは、特定のエンティティに対してより毒性が高くなりながらコンテンツを作成することで、差別的にターゲットを絞ることがあります。研究者たちは、自分たちの実験に使用したLLMがChatGPTであったとしても、彼らの手法は他のどのLLMにも拡張できると指摘しています。チームは、彼らの研究がAIコミュニティに倫理的で安全かつ信頼性のあるAIシステムを提供する技術の開発を促進することを望んでいます。
このAIニュースレターは、あなたが必要とするすべてです #56
今週、オープンソースとクローズドモデルの両方で、LLMの世界にいくつかの新しい競合他社が登場しました印象的な機能を持つにもかかわらず、LLaMAモデルの最初のバージョンにはライセンスの問題がありました...
「10/7から16/7までのトップコンピュータビジョン論文」
コンピュータビジョンは、機械に視覚世界を解釈し理解させることに焦点を当てた人工知能の分野であり、画期的な研究と技術の進化により急速に進化しています

「PolyLM(Polyglot Large Language Model)に会ってください:640BトークンでトレーニングされたオープンソースのマルチリンガルLLMで、2つのモデルサイズ1.7Bと13Bが利用可能です」
最近、大規模言語モデル(LLM)の導入により、その多様性と能力が人工知能の分野で注目されています。これらのモデルは、膨大な量のデータで訓練され、自然言語の指示に基づいてテキストを理解し、推論し、生成するという、人間に近い能力を持っています。これらのモデルは、ゼロショットおよびフューショットのタスクで優れたパフォーマンスを発揮し、さまざまなタスクセットで微調整することで、自然言語で与えられた指示に基づいて予期しない課題に対応することができます。 現在のLLMとその開発は、英語やリソース豊富な言語に焦点を当てています。既存のLLMのほとんどは、英語のために特別に設計され、訓練されており、これらのモデルの研究と開発において英語に対する優位性が顕著です。この制限に対処するために、DAMO AcademyとAlibaba Groupの研究者チームは、POLYLM(Polyglot Large Language Model)と呼ばれるマルチリンガルLLMを提案しました。既存のマルチリンガルLLMには13Bモデルが欠けているという特徴があり、チームはPOLYLM-13BとPOLYLM-1.7Bをリリースして使用を容易にしました。 POLYLMは、Wikipedia、mC4、CC-100などの一般にアクセス可能なソースからの640Bトークンの巨大なデータセットを使用して構築されました。チームはまた、低資源言語の不十分なデータの問題に対処するために、カリキュラム学習技術を提案しています。この方法は、トレーニング中に高品質な低資源言語の割合を徐々に増やすことを含みますが、最初は英語に重点を置いています。英語から他の言語への一般的な知識の転送に焦点が当てられています。 チームはまた、教師付き微調整(SFT)フェーズのためのマルチリンガルな指示データセットであるMULTIALPACAを開発しました。既存のマルチリンガルSFTデータセットは、手動注釈によって取得されるか、機械翻訳によって取得されるが、手間と費用がかかるか、翻訳エラーが発生し、文化的なニュアンスが欠ける可能性があります。このマルチリンガル自己指示アプローチは、これらの制約を克服するために高品質なマルチリンガルな指示データを自動的に提供し、英語のシード、多言語への翻訳、指示の生成、およびフィルタリングシステムを活用します。 評価とLLMの多言語能力の評価のために、チームは既存のマルチリンガルタスクから派生したベンチマークを開発しました。これには、質問応答、言語理解、テキスト生成、クロスリンガル機械翻訳などのタスクを含みます。チームは広範な実験により、彼らの事前学習済みモデルが、非英語圏の言語において、同等のサイズのオープンソースモデルよりも優れたパフォーマンスを発揮することを示しました。提案されたカリキュラムトレーニング戦略は、英語の習熟度を維持しながら、多言語のパフォーマンスを向上させます。マルチリンガルな指示データの使用は、さらにPOLYLMの多言語ゼロショットタスクの処理能力を大幅に向上させます。 チームは以下の貢献をまとめています。 スペイン語、ロシア語、アラビア語、日本語、韓国語、タイ語、インドネシア語、中国語など、主要な非英語圏の言語で優れたパフォーマンスを発揮する13Bスケールのモデルが実現されました。このモデルは、これらの言語の習熟度が不足しているか、同等の能力を持つより小さなバージョンがない既存のオープンソースモデルを補完します。 英語で主に獲得された一般的な知識を多様な非英語圏の言語や機械翻訳などの特定の自然言語処理タスクに効果的に転送するための高度なカリキュラム学習アプローチが提案されました。 既存の指示データセットを補完するMULTIALPACAというデータセットが提案されました。これにより、LLMは非英語圏の英語を母国語としない話者からのマルチリンガルな指示をより良く理解することができます。

「コーヒーマシンを介して侵害された – 知っておくべき6つのスマートホームセキュリティの脅威」
「自宅のセキュリティには、キーレスのスマートロックの一つを考えたことはありますか?もう一度考えた方が良いかもしれません... スマートホームや「インターネット・オブ・シングス(IoT)」デバイスは、カーテンを開けたりコーヒーを淹れたりするなど、多くの日常プロセスを簡素化しますしかし、IoTデバイスは、セキュリティ上の脅威を持ち込む可能性がありますどのようなリスクがあるのでしょうか... コーヒーマシンを介して侵害される - 知っておくべき6つのスマートホームセキュリティの脅威 詳細を読む」

ジェネレーティブAIツールを使用する際にプライバシーを保護するための6つの手順
イントロダクション 生成型AIツールの出現は、興奮と懸念を引き起こしました。これらのツールは私たちの生活と仕事を革新する可能性がありますが、AIのプライバシーとセキュリティに関する重要な問題も提起しています。この記事では、個人情報を保護しながら生成型AIの世界を探索する方法について探求します。リスクを理解し、効果的なプライバシー対策を実施することで、これらの強力なツールを自信を持って活用することができます。 生成型AIツールを使用する際のプライバシー保護方法 1. 注意深い利用とプライバシー保護 生成型AIツールを責任を持って活用するための最初のステップは、プライバシーの影響を注意深く考えることです。多くのアプリケーションは、データやコンテンツへのアクセスを提供する必要があり、これがプライバシーを損なう可能性があります。積極的なアプローチを取ることで、これらのツールの利点を損なうことなく、個人情報を保護することができます。 2. 利用規約の理解 プライバシーを保護するための重要な側面の1つは、使用するAIツールの利用規約を注意深く調べることです。面倒に感じるかもしれませんが、このステップはデータの収集と処理方法を理解するために重要です。同意する内容を知ることで、情報に基づいた意思決定を行い、潜在的なプライバシーのリスクを緩和することができます。 3. データの利用とAIの学習 ChatGPTやDALL-Eなどの生成型AIツールは、パフォーマンス向上のために広範なデータを利用しています。これらのツールは、個人情報を悪意のある目的に使用しないことを保証していますが、データがどのように利用されるかを知ることは重要です。情報がAIの学習にどのように貢献するかを理解することで、共有する内容についての情報を正しく選択し、潜在的なデータ漏洩に対して警戒心を持つことができます。 4. プライバシーポリシーとユーザーの信頼 OpenAIやGoogleなどのAI開発者は、サービスを向上させるためにユーザーデータを収集しています。しかし、これらのAIツールを通じて収集されるデータが広告の個人化に使用される可能性があることを認識することが重要です。これらのプラットフォームのプライバシーポリシーに精通することで、情報が適切に扱われ、信頼が置かれていることを確認することができます。 5. 個人情報の慎重な扱い プライバシーを保護するためには、生成型AIツールとの間で個人的な情報、プライベートな情報、または機密情報を共有しないことが望ましいです。財務報告書や機密のやりとりなどの機密事項に関する支援を求めることは誘惑されるかもしれませんが、このような情報はこれらのエンジンからは切り離して保持することが最善です。AIのプロンプトは時折スタッフによってレビューされるため、不適切な行動や意図しないデータの露出を防ぐために慎重さが重要です。 6. 機密性とセキュリティのコントロール 生成型AIツールに関連するプライバシーポリシーや潜在的なリスクを評価した後は、これらのプラットフォームが提供するプライバシーとセキュリティのコントロールを探索する時です。多くの企業は、これらのコントロールをアクセスしやすく使いやすくすることを目指しており、ユーザーがデータとプライバシーに対してコントロールを維持することができます。 Google Bardとデータ管理 Google…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.