Learn more about Search Results こちらの - Page 11

- You may be interested
- 「QLORAとは:効率的なファインチューニン...
- GPTエンジニア:1つのプロンプトで強力な...
- 「データ分析のためのトップ10のSQLプロジ...
- 「LinkedInプロフィールでコールバック率...
- 「シリコンバレーの大胆なSFの賭け:スマ...
- 「データの必要量はどのくらいですか? 機...
- AIの闇面──クリエイターはどのように助け...
- Amazon SageMaker 上で MPT-7B を微調整する
- 公的機関によるAI調達のための標準契約条...
- 「OpenAIのAI検出ツールは、AIによって生...
- 「Pythonでの日付と時刻の効果的なコーデ...
- 「LangChain、Google Maps API、およびGra...
- スタンフォード大学の研究者が『FlashFFTC...
- このAI研究は、DISC-MedLLMという包括的な...
- ディープラーニングのマスタリング:分岐...

「知識グラフの力を利用する:構造化データでLLMを豊かにする」
近年、大規模な言語モデル(LLM)が広まってきていますおそらく最も有名なLLMはChatGPTで、それはOpenAIによって2022年11月にリリースされましたChatGPTはアイデアを生成し、提供することができます...
学習トランスフォーマーコード第2部 – GPTを間近で観察
私のプロジェクトの第2部へようこそここでは、TinyStoriesデータセットとnanoGPTを使用して、トランスフォーマーとGPTベースのモデルの複雑さについて探求しますこれらはすべて、古いゲーミングラップトップで訓練されました
「LLMとNLPのための非構造化データの監視」
「NLPまたはLLMベースのソリューションを展開した後、それを追跡する方法が必要ですしかし、テキストの山を理解するために非構造化データを監視するにはどうすればよいでしょうか? ここではいくつかのアプローチがあります...」

画像をプロンプトに変換する方法:Img2Prompt AIモデルによるステップバイステップガイド
シンプルなAPIコールと少しのNode.jsで画像からプロンプトを収集する
「Img2Prompt AI モデルを使用して画像をプロンプトに変換する方法:ステップバイステップガイド」
「シンプルなAPI呼び出しと少しのNode.jsで画像からプロンプトを収集します」

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…
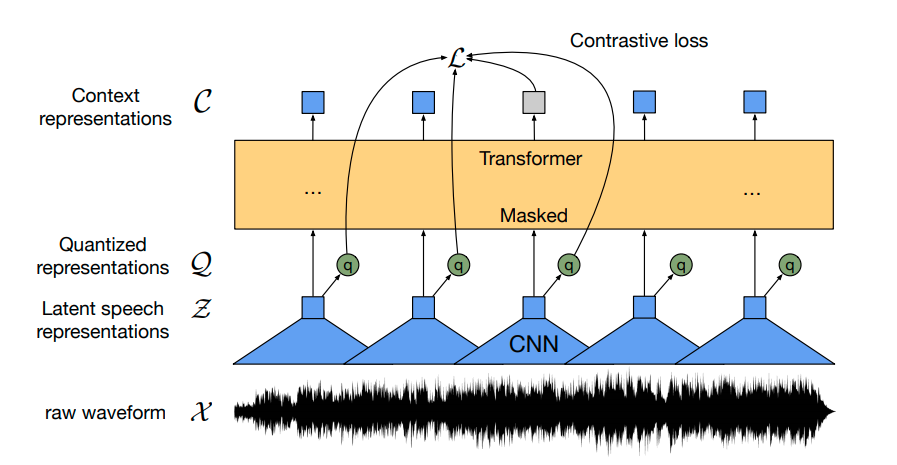
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…
~自分自身を~ 繰り返さない
🤗 Transformersのデザイン哲学 「Don’t repeat yourself(同じことを繰り返さない)」、またはDRY(Don’t Repeat Yourself)は、ソフトウェア開発のよく知られた原則です。この原則は、「The pragmatic programmer」というコードデザインに関する最も読まれた本の1つから生まれました。この原則のシンプルなメッセージは明らかな意味を持っています。既に他の場所で存在するロジックを再書きする必要はありません。これにより、コードは同期され、メンテナンスが容易になり、より堅牢になります。この論理パターンへの変更は、依存関係のすべてに一様に影響を与えます。 Hugging FaceのTransformersライブラリの設計は、DRY原則とはまったく逆のものに見えるかもしれません。注意機構のコードは、異なるモデルファイルに50回以上もコピーされています。時にはBERTモデル全体のコードが他のモデルファイルにコピーされています。既存のモデルとほぼ同じ新しいモデルの貢献を強制的に行うことがよくありますが、それにはわずかな論理的な調整以外にも、すべての既存のコードをコピーする必要があります。なぜこれをやるのでしょうか?私たちは単に怠惰であるか、あるいは中心化された場所にすべての論理的な要素を集めることに圧倒されているのでしょうか? いいえ、私たちは怠惰ではありません。TransformersライブラリにDRYデザイン原則を適用しないというのは、非常に意識的な決定です。その代わりに、私たちは「シングルモデルファイル」ポリシーと呼ぶ別のデザイン原則を採用することにしました。シングルモデルファイルポリシーは、モデルの順方向パスに必要なすべてのコードが1つのファイル、つまりモデルファイルに含まれているというものです。推論でBERTがどのように機能するかを理解するためには、BERTのmodeling_bert.pyファイルを見ればよいだけです。異なるモデルの同一のサブコンポーネントを新しい中央集権化された場所に抽象化しようとする試みを通常は拒否します。すべての可能な注意メカニズムが含まれたattention_layer.pyを持つことはしたくありません。再び、なぜこれをやるのでしょうか? 短く言えば、その理由は次のとおりです: 1. Transformersはオープンソースコミュニティによって作られました。 2. 私たちの製品はモデルであり、顧客はモデルコードを読んだり調整したりするユーザーです。 3. 機械学習の世界は非常に速く進化しています。 4. 機械学習モデルは静的です。 1. オープンソースコミュニティによって作られました Transformersは、外部の貢献を積極的に促進するために作られています。貢献は通常、バグ修正または新しいモデルの貢献です。モデルファイルの1つでバグが見つかった場合、見つけた人が修正するのができるだけ簡単にすることを望んでいます。他のモデルの100のエラーを引き起こすことを見るのは、非常にやる気を削ぐことです。…
プルリクエストとディスカッションの紹介 🥳
私たちは、Hugging Face Hubでの最新の共同作業機能、プルリクエストとディスカッションのリリースを大いに喜んでお知らせします! プルリクエストとディスカッションは、モデル、データセット、およびスペースのすべてのリポジトリタイプのコミュニティタブの下で今日から利用可能です。コミュニティのメンバーは、ディスカッションとプルリクエストを作成し、参加することができます。これにより、チーム内だけでなく、コミュニティの他のすべての人とも協力が可能になります! これは、Hubで行われた最大のアップデートであり、コミュニティメンバーがそれを使って協力を始めるのを楽しみにしています 🤩。 新しい「コミュニティ」タブは、これまでの倫理的な機械学習の提案とも一致しています。フィードバックとイテレーションは、倫理的な機械学習ソフトウェアの開発において中心的な役割を果たします。私たちは、それをコミュニティのツールセットに持っていることで、ML、コラボレーション、進歩に新しい種類のポジティブなパターンが生まれると本当に信じています。 ディスカッションとプルリクエストの例としては、次のようなものがあります: 倫理的なバイアスの開示を改善するためのモデルカードへの提案を行う。 特定のスペースデモの懸念を引き起こす生成物をユーザーがフラグする。 モデルとデータセットの作成者がコミュニティメンバーと直接ディスカッションできる場を提供する。 他の人がリポジトリを改善できるようにする!例えば、ユーザーはTensorFlowのウェイトを提供したいかもしれません! ディスカッション ディスカッションでは、コミュニティメンバーが質問をしたり回答したり、アイデアや提案をリポジトリの所有者やコミュニティと直接共有したりすることができます。誰でもリポジトリのコミュニティタブでディスカッションを作成したり参加したりできます。 プルリクエスト プルリクエストでは、コミュニティメンバーがウェブサイトから直接プルリクエストを開いたりコメントしたりマージしたり閉じたりすることができます。プルリクエストを開く最も簡単な方法は、「ファイルとバージョン」タブの「共同作業」ボタンを使用することです。これにより、単一のファイルの貢献が非常に簡単に行えます。 裏側では、プルリクエストではフォークやブランチを使用せず、ソースリポジトリに直接保存されるカスタムの「ブランチ」であるrefsを使用しています。このアプローチにより、モデル/データセットの新バージョンごとにフォークを作成する必要がなくなります。 他のGitホストとの違いは何ですか 大まかに言うと、私たちは他のGitホスト(GitHubなど)のPRやIssueのよりシンプルなバージョンを構築することを目指しています: フォークは関与しません:投稿者はソースリポジトリに直接特別なrefブランチにプッシュします IssueとPRの明確な区別はありません:本質的に同じなので、同じリストに表示されます MLに最適化されています(つまり、モデル/データセット/スペースのリポジトリ)で、任意のリポジトリではありません 次は何ですか もちろん、これは始まりに過ぎません。私たちはコミュニティのフィードバックを聞きながら、将来的に新機能を追加し、コミュニティタブを改善していく予定です。フィードバックがあれば、こちらのディスカッションに参加することができます。今日が初めてディスカッションに参加し、プルリクエストを開く最高のタイミングです!…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.