Learn more about Search Results OPT - Page 111

- You may be interested
- 3Dプリンターは郵便局の迅速かつ手頃な配...
- 「PyTorch入門 – 最初の線形モデル...
- 「GoogleがニュースライターAI ‘Gen...
- 「数値処理者がクジラが奇妙な行動をして...
- 「バイオインスパイアードハードウェアシ...
- ZeROを使用して、DeepSpeedとFairScaleを...
- 「教室外での、オンライン試験による無指...
- 「データを分析するためにOpenAIのコード...
- マイクロソフトAIは、高度なマルチモーダ...
- 「Samet氏がACM SIGSPATIAL生涯影響力賞を...
- トレンドのAI GitHubリポジトリ:2023年11...
- ロボットウナギが魚の効率的な泳ぎ方を明...
- スタンフォードの研究者たちは、「EquivAc...
- LoftQをご紹介します:大規模言語モデルの...
- コース開始コミュニティイベント

ExcelとPower BI – 意思決定においてどちらが優れているか?
現代の急速なビジネス環境においては、組織の成功のためには情報をもとにした意思決定が不可欠です。人気のあるビジネスインテリジェンスツールとそのユニークな機能を理解することが、真のポテンシャルを引き出す上で重要です。MS ExcelとPower BIの両方は、データ分析と意思決定に関する印象的な機能を提供しています。ただし、最適な選択を決定するには、具体的な要件に応じて決定する必要があります。この記事では、MS ExcelとPower BIの強みと特定のユースケースについて掘り下げ、ビジネスニーズに合わせてどちらのツールを選択するかをお手伝いします。 MS Excelとは? Microsoft Excelは、データの整理、操作、分析、可視化が可能な強力かつ使いやすいツールです。データ処理、クリーニング、変換などの重要な機能を提供しています。データ分析と可視化には、データ分析ツール、ピボットテーブル、グラフなどの組み込み機能があります。また、Goal Seek、Solver、Decision Trees、Sensitivity analysisなどの機能により、要約されたデータに基づいて情報をもとにした意思決定が可能です。Power PivotやQueryは、データモデリングや変換を容易にすることで、意思決定に重要な役割を果たしています。Excelは、データを分析し、効果的な意思決定を行うための多目的なツールです。 Power BIとは? Power BIは、Excelと同等の性能を持ち、データ変換、意思決定、さまざまなデータソースへの接続、統合、可視化、プレゼンテーションなどの機能を提供するMicrosoftが提供する別の意思決定テーブルです。Power BIには、動的でインタラクティブなレポートやリアルタイムダッシュボードを作成する機能など、独自の特徴があります。また、データモデリング、異なるデータ間の関係の形成、データ内の依存関係の検索なども含まれます。 さらに、Power Queryを介したデータクエリは、直感的なグラフィカルインターフェースを使用して、クリーニング、整形、および変換などのデータ処理アクションを実行する興味深い機能です。Microsoftの製品として、包括的で使いやすいビジネスインテリジェンスツールとしてのコア機能とサービスを提供します。 Excelの最良の機能 1. データの整理に使用できるスプレッドシート ソートおよびフィルタリング:ソートおよびフィルタリング機能を使用して、データを簡単に整理できます。…

AutoML – 機械学習モデルを構築するための No Code ソリューション
はじめに AutoMLは自動機械学習としても知られています。2018年、GoogleはクラウドAutoMLを発表し、大きな関心を集め、機械学習と人工知能の分野で最も重要なツールの1つとなりました。この記事では、「Google Cloud AutoML」を使った機械学習モデルを構築するためのノーコードソリューションである「AutoML」について学びます。 AutoMLは、Google Cloud Platform上のVertex AIの一部です。Vertex AIは、クラウド上で機械学習パイプラインを構築および作成するためのエンドツーエンドソリューションです。ただし、Vertex AIの詳細については、別の記事で説明します。AutoMLは、主に転移学習とニューラルサーチアーキテクチャに依存しています。データを提供するだけで、AutoMLはユースケースに最適なカスタムモデルを構築します。 この記事では、Pythonコードを使ったGoogle Cloud Platform上でのAutoMLの利点、使用方法、実践的な実装について説明します。 学習目標 コードを使ったAutoMLの使用方法を読者に知らせること AutoMLの利点を理解すること クライアントライブラリを使用してMLパイプラインを作成する方法 この記事は、Data Science Blogathonの一部として公開されました。 問題の説明 機械学習モデルを構築することは時間がかかり、プログラミング言語の熟練度、数学と統計の良い知識、および機械学習アルゴリズムの理解などの専門知識が必要です。過去には、技術的なスキルを持つ人々だけがデータサイエンスで働き、モデルを構築できました。非技術的な人々にとっては、機械学習モデルを構築することは最も困難なタスクでした。ただし、モデルを構築した技術的な人々にとっても道のりは容易ではありませんでした。モデルを構築した後、メンテナンス、展開、および自動スケーリングには追加の努力、労働時間、およびわずかに異なるスキルセットが必要です。これらの課題を克服するために、グローバル検索大手のGoogleは、2014年にAutoMLを発表しましたが、後に一般に公開されました。 AutoMLの利点 AutoMLは手動の介入を減らし、少しの機械学習の専門知識が必要となります。…

ChatGPTを使った効率的なデバッグ
大規模言語モデルの力を借りて、デバッグ体験を向上させ、より速く学習する

AIによる光通信の加速化
通信効率の向上は、光フォトニクス技術を人工知能に導入するのに役立ちます

AWSにおけるマルチモデルエンドポイントのためのCI/CD
生産用機械学習ソリューションの再トレーニングと展開を自動化することは、モデルが共変量シフトを考慮しながら、誤りや不要な人間の介入を制限するための重要なステップです
ランダムフォレストと欠損値
オンラインで見つかる過剰にクリーンされたデータセット以外に、欠損値はどこにでもあります実際、データセットが複雑で大きいほど、欠損値がより多く存在する可能性があります...

「Kingsletter」で3Dで楽しむシェルの祝賀を今週の「NVIDIA Studio」で
エディター注:この記事は、弊社の毎週のNVIDIA Studioシリーズの一部であり、注目のアーティストを紹介し、創造的なヒントとトリックを提供し、NVIDIA Studioテクノロジーが創造的なワークフローを改善する方法を示しています。また、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて、コンテンツ作成を劇的に加速する方法についても詳しく説明しています。 キングスレターという名前の実力のある3DアーティストであるAmir Anbarestani氏は、今週NVIDIA Studioで彼のスペースタートルのシーンを作成するのを「シェル・オブ・ア・グッド・タイム」と語っています。 キングスレター氏は、常に3Dアートに魅了されていたと言います。幼少期から、没入型の環境を探求したり、作り出したりすることが好きでした。プラスチシン(プラスチックのような粘土)で遊んだり、鉛筆画を描いたりすることで、自己表現の本能は常に広大な3Dの領域で共感を見出していました。 MSIクリエイターZ17HXと共にスペースタートルを@AustraliaMSI & @NVIDIAStudioから提供 NVIDIA Studioドライバーで創造力を解き放ちましょう! こちらから入手できます:https://t.co/idJlWgb8UX pic.twitter.com/Ff6Y6RfQp4 — King’s Letter (@TheKingsletter) April 28, 2023 以下では、彼がZBrush、Adobe…

AIの仕事を見つけるための最高のプラットフォーム
あなたのキャリアの目標、好みの仕事スタイル、およびAIの専門分野に依存するAIの仕事に最適なプラットフォームについてもっと学びましょう

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。
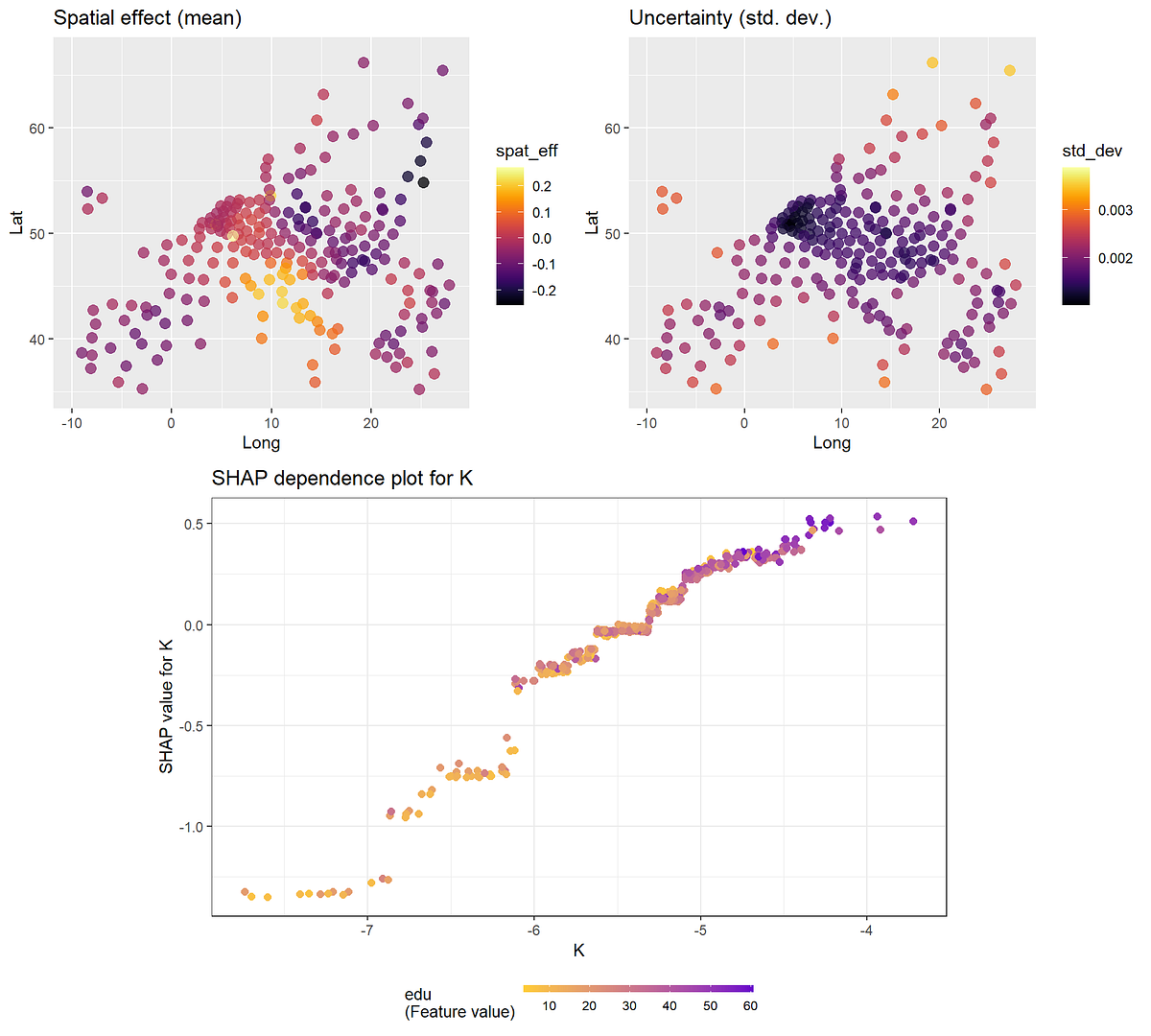
グループ化および空間計量データの混合効果機械学習におけるGPBoost
GPBoostを用いたグループ化されたおよび地域空間計量データの混合効果機械学習 - ヨーロッパのGDPデータを用いたデモ
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.