Learn more about Search Results Seaborn - Page 10

- You may be interested
- 「生データから洗練されたデータへ:デー...
- 「Pythonによる3D地理空間データ統合:究...
- AutoNLPとProdigyを使用したアクティブラ...
- 「RAGを忘れて、未来はRAG-Fusionです」
- ZenMLとStreamlitを使用した従業員離職率予測
- 「声AIがLLVCを発表:効率と速度に優れた...
- あなたのデータが適切にモデル化されてい...
- 拡散モデルの謎を解き明かす:詳細な探求
- 「Langchain Agentsを使用して、独自のデ...
- 「プライバシーを保護しながらジェネラテ...
- ユーロトリップの最適化:遺伝的アルゴリ...
- AI技術はリサイクルをどのように変革して...
- データ駆動型のディスパッチ
- あなたのオープンソースのLLMプロジェクト...
- 生産性向上のための10の最高のAIツール(...

「PythonとMatplotlibを使用して極座標ヒストグラムを作成する方法」
こんにちは、そしてこのPython + Matplotlibチュートリアルへようこそここでは、上記で見た美しい極座標ヒストグラムの作り方を紹介します極座標ヒストグラムは、値が多すぎる場合に便利です...
「このテクニックでより良い棒グラフを作成する」
「効果的なビジュアライゼーションのためにインスピレーションが必要な時は、The Economist、Visual Capitalist、またはThe Washington Postを閲覧しますその中で興味深いインフォグラフィックに偶然出会いました...」

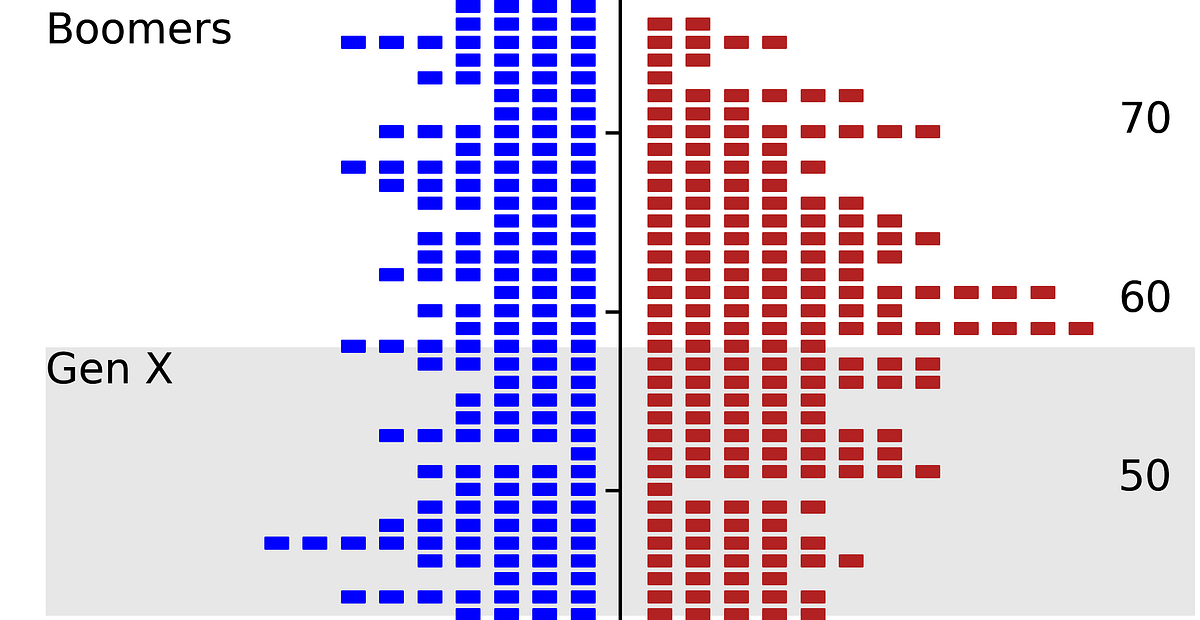
「作曲家はいつ最も成功するのか?」
「シンガーソングライターは、どの年齢で最も成功するのか?先日、古いスティービー・ワンダーの曲を聴いた時に、私はこれについて考えました私の印象では、数学者のように、シンガーソングライターは彼らの...」

「あらゆるプロジェクトに適した機械学習ライブラリ」
「機械学習プロジェクトで使用できる多くのライブラリが存在しますプロジェクトで使用するライブラリについての包括的なガイドを探索してください」

「OpenAIのChatGPTコードインタプリタの探索:その機能に深く潜る」
OpenAIの自然言語処理(NLP)における進展は、大規模言語モデル(LLM)の台頭によって特徴付けられていますこれらのモデルは、GitHub CopilotやBing検索エンジンなど、数百万人に利用される製品の基盤となっていますこれらのモデルは、情報を記憶し統合するという独自の能力を持つことにより、コードやテキストなどのタスクにおいて前例のないベンチマークを設定しています

Pythonによる地理空間データの分析
地理空間データサイエンスは私の興味の一つですデータを地図上で可視化し、そしてどれだけ多くの場合にデータポイント間の関係が素晴らしいものであるかについて、私は魅了されています…
ニューヨーク市の可視化
「PythonとPlotlyを使用して、NYCのオープンデータプラットフォームからデータを活用するジオデータの構築、Wifiヒートマップ、そしてセントラルパークの住人について学びましょう」
「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
はじめに Pandasとは、名前だけではありません – それは「パネルデータ」の略です。では、それが具体的に何を意味するのでしょうか?経済学や統計学におけるPandasのデータ形式を使用します。それは、異なるエンティティや主体に対して複数の期間にわたる観察を保持する構造化されたデータセットを指します。 現代では、人々はさまざまなファイル形式でデータを保存し、アクセス可能な形式に変換する必要があります。これは、データサイエンスプロジェクトの最初のステップであり、この記事の主な話題になります。 この記事は、データサイエンスブログマラソンの一環として公開されました。 Pandasのデータサイエンスの成功の要素 簡単なデータ処理: pandasの特筆すべき機能の一つは、複雑なデータタスクを簡単に処理できることです。以前は複雑なコードだったものが、pandasの簡潔な関数によってスムーズに処理されるようになりました。 完璧なデータの調和: pandasは、NumPy、Matplotlib、SciPy、Scikit Learnなどの高度なライブラリとシームレスに組み合わさり、より大規模なデータサイエンスの一部として効率的に機能します。 データ収集の適応性: pandasは、さまざまなソースからデータを収集する柔軟性を持っています。CSVファイル、Excelシート、JSON、またはSQLデータベースであっても、pandasはすべて対応します。この適応性により、データのインポートが簡素化され、形式変換の頭痛から解放されます。 要するに、pandasの成功は、ユーザーフレンドリーな構造、データの管理能力、他のツールとの統合、さまざまなデータソースの処理能力から生まれています。これにより、データ愛好家はデータセットに隠された潜在能力を引き出し、データサイエンスの景観を再構築することができます。 Pandasはデータをきれいに整理する方法 pandasをデータ整理のオーガナイザーとして想像してみてください。pandasは、「Series」と「DataFrame」という2つのすばらしい構造を使用してデータを処理します。それらはデータストレージのスーパーヒーローのようなものです! Series: Seriesは、データが配置される直線のようなものです。それは数字から単語まで、あらゆるものを保持することができます。各データには、インデックスと呼ばれる特別なラベルが付いています。それは名札のようなものです – データを簡単に見つけるのに役立ちます。Seriesは、単一の列のデータを扱うときに非常に便利です。計算や分析などのトリックを実行することができます。 DataFrame: DataFrameは、ミニスプレッドシートまたはファンシーテーブルのようなものです。Excelで見るような行と列があります。各列はSeriesです。したがって、「Numbers」列、 「Names」列などが持てます。DataFrameは完全なパッケージのようなものです。数値、単語など、さまざまなデータを処理するのに非常に優れています。さらに、探索やデータの整理、データの変更などの便利な機能を備えています。DataFrameの各列はSeriesです!…
「PythonとSklearnを使用して4つのセントロイドベースのクラスタリングアルゴリズムを示すアニメーションの作成」
クラスタリング分析は、データをその類似点や相違点に基づいてグループ化する効果的な機械学習技術です得られたデータグループは、セグメンテーションなど様々な目的に使用することができます
カーネル密度推定器のステップバイステップの説明
KDEは、基礎となるプロセスについての仮定をすることなく、任意のデータから視覚的に魅力的なPDFを作成することができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.