Learn more about Search Results RoPE - Page 10

- You may be interested
- AIと資金調達:資金調達には人間の要素が...
- AI記事スキャンダルがアリーナグループに...
- (LLMを活用した こきゃくセグメンテーショ...
- 他人のPythonコードを簡単に理解する方法は?
- 「GBMとXGBoostの違いって何だ?」
- Midjourney 5.2 を発表:AI画像生成におけ...
- 「プログラムの速度を上げるための5つのコ...
- マイクロソフトの研究者が、言語AIを活用...
- 計算機の進歩により、研究者はより高い信...
- Mojo | 新しいプログラミング言語
- 「キナラがAra-2プロセッサを発表:パフォ...
- NMFを使用した製品の推薦
- 「デバイス内AIの強化 QualcommとMetaがLl...
- 通貨為替レートの予測のためのSARIMAモデル
- このAIニュースレターは、あなたが必要と...

「AIとブロックチェーンの交差点を探る:機会と課題」
今日私たちが見ている世界を変えるAIをブロックチェーンに統合することに関連する機会と課題を探索してください

「野心的なAI規制に対する力強いプロセス:オックスフォード研究からの3ステップソリューション」
「もしアカウンタブルマネージャーやプロダクトオーナー、プロジェクトマネージャー、もしくはデータサイエンティストで、AIプロジェクトに関与している場合、Oxford ResearchはあなたをAI規制の重要な関係者として特定しました先行スタートを切りましょう…」

キュービットマジック:量子コンピューティングで神話の生物を創造する
しかし、少しの創造力を持つことで、私たちは多くの印象的な偉業を成し遂げることができますその一つに、魅力的な能力であるイメージや音楽の生成がありますそして、この記事では—神話上の生物の可視化が含まれます!

アマゾンのSageMakerジオスペーシャル機能を使用して、アラップで強靭な都市の設計をする
この投稿は、ArupのRichard AlexanderとMark Hallowsとの共著ですArupは、持続可能な開発に専念するデザイナー、コンサルタント、専門家のグローバルな集団ですデータは、世界クラスの収集と分析を通じて、インパクトを生み出すための洞察を提供するために、Arupのコンサルタント業務を支えていますここで提示されている解決策は、強靭な都市の意思決定プロセスを導くものです

「Amazon SageMakerを使用して、Rayベースの機械学習ワークフローをオーケストレーションする」
機械学習(ML)は、お客様がより困難な問題を解決しようとするにつれて、ますます複雑になっていますこの複雑さはしばしば、複数のマシンを使用して単一のモデルをトレーニングする必要性を引き起こしますこれにより、複数のノード間でタスクを並列化することが可能になり、トレーニング時間の短縮、スケーラビリティの向上、[…] などがもたらされます

「プロダクションでのあなたのLLMの最適化」
注意: このブログ投稿は、Transformersのドキュメンテーションページとしても利用可能です。 GPT3/4、Falcon、LLamaなどの大規模言語モデル(LLM)は、人間中心のタスクに取り組む能力を急速に向上させており、現代の知識ベース産業で不可欠なツールとして確立しています。しかし、これらのモデルを実世界のタスクに展開することは依然として課題が残っています: ほぼ人間のテキスト理解と生成能力を持つために、LLMは現在数十億のパラメータから構成される必要があります(Kaplanら、Weiら参照)。これにより、推論時のメモリ要件が増大します。 多くの実世界のタスクでは、LLMには豊富な文脈情報が必要です。これにより、推論中に非常に長い入力シーケンスを処理する能力が求められます。 これらの課題の核心は、特に広範な入力シーケンスを扱う場合に、LLMの計算およびメモリ能力を拡張することにあります。 このブログ投稿では、効率的なLLMの展開のために、現時点で最も効果的な技術について説明します: 低精度: 研究により、8ビットおよび4ビットの数値精度で動作することが、モデルのパフォーマンスに大幅な低下を伴わずに計算上の利点をもたらすことが示されています。 Flash Attention: Flash Attentionは、よりメモリ効率の高いアテンションアルゴリズムのバリエーションであり、最適化されたGPUメモリの利用により、高い効率を実現します。 アーキテクチャのイノベーション: LLMは常に同じ方法で展開されるため、つまり長い入力コンテキストを持つ自己回帰的なテキスト生成として、より効率的な推論を可能にする専用のモデルアーキテクチャが提案されています。モデルアーキテクチャの中で最も重要な進歩は、Alibi、Rotary embeddings、Multi-Query Attention(MQA)、Grouped-Query-Attention(GQA)です。 このノートブックでは、テンソルの視点から自己回帰的な生成の分析を提供し、低精度の採用の利点と欠点について包括的な探索を行い、最新のアテンションアルゴリズムの詳細な調査を行い、改良されたLLMアーキテクチャについて議論します。これを行う過程で、各機能の改善を示す実用的な例を実行します。 1. 低精度の活用 LLMのメモリ要件は、LLMを重み行列とベクトルのセット、およびテキスト入力をベクトルのシーケンスとして見ることで最も理解できます。以下では、重みの定義はすべてのモデルの重み行列とベクトルを意味するために使用されます。 この投稿の執筆時点では、LLMは少なくとも数十億のパラメータから構成されています。各パラメータは通常、float32、bfloat16、またはfloat16形式で保存される10進数の数値で構成されています。これにより、LLMをメモリにロードするためのメモリ要件を簡単に計算できます: X十億のパラメータを持つモデルの重みをロードするには、おおよそ4 *…
「紙からピクセルへ:手書きテキストのデジタル化のための最良の技術の評価」
「組織は、歴史的な手書き文書をデジタル化するという煩雑で高額な作業に長い間取り組んできました以前は、AWS Textractなどの光学文字認識(OCR)技術を使用していましたが…」
「ギザギザしたCOVIDチャートの謎を解決する」
COVID-19パンデミックの最初の年において、この病気の死亡者数は多くの論争の的となりました問題の中には、テストの不足による早期の過小評価や死亡者数の…

「ワードエンベディング:より良い回答のためにチャットボットに文脈を与える」
ワードエンベディングとChatGPTを使用してエキスパートボットを構築する方法を学びましょうワードベクトルの力を活用して、チャットボットの応答を向上させましょう
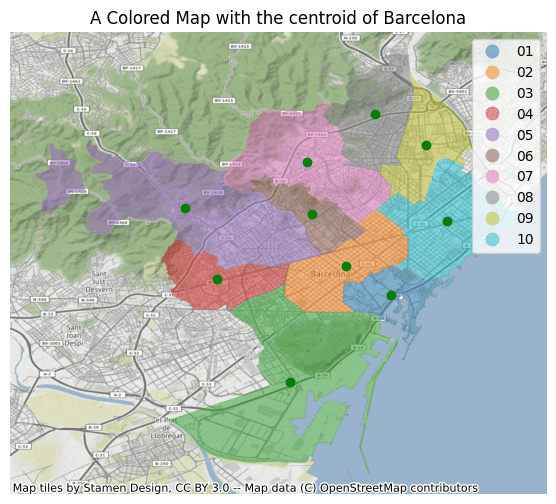
「GeoPandasを使ったPythonにおける地理空間データの活用」
GeoPandasを使用した地理空間データ分析の包括的な紹介
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.