Learn more about Search Results RLHF - Page 10

- You may be interested
- 「クレジットカードの不履行データセット...
- CDCデータレプリケーション:技術、トレー...
- スターリング-7B AIフィードバックからの...
- 「HaystackパイプラインとAmazon SageMake...
- 自動車産業における生成AIの画期的な影響
- 「みんなのためのLLM:ランニングLangChai...
- 「クリス・サレンス氏、CentralReachのCEO...
- アップルとEquall AIによる新しいAI研究が...
- トロント大学の研究者たちは、3300万以上...
- 世界のデータを処理できるアーキテクチャ...
- 「パンダとPythonでデータの整理をマスタ...
- KAIST(韓国科学技術院)からの新しいAI研...
- 🐶セーフテンソルは、本当に安全であり、...
- 音から視覚へ:音声から画像を合成するAud...
- マイクロソフトリサーチがBatteryMLを紹介...
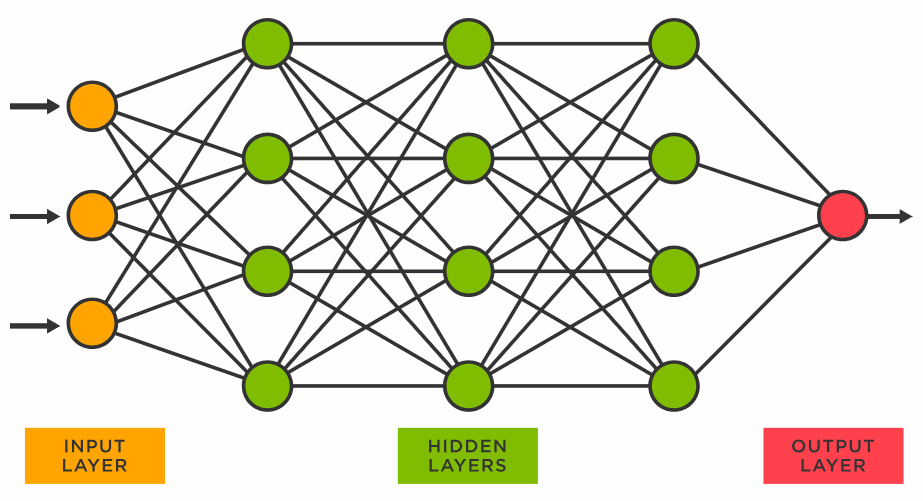
「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
「たぶん私だけじゃないと思いますが、1月のツイートで明らかになっていなかったとしても、私は最初にChatGPTに出会ったときに完全に驚きましたその体験は他のどんなものとも違いました…」

DeepMindの研究者が、成長するバッチ強化学習(RL)に触発されて、人間の好みに合わせたLLMを整列させるためのシンプルなアルゴリズムであるReinforced Self-Training(ReST)を提案しました
大規模言語モデル(LLM)は、優れた文章を生成し、さまざまな言語的な問題を解決するのに優れています。これらのモデルは、膨大な量のテキストと計算を使用してトークンを自己回帰的に予測する確率を高めるためにトレーニングされます。しかし、先行研究は、高確率でテキストを生成することが、異なるタスクにおける人間の好みと一致することは稀であることを示しています。言語モデルは、適切に整列されていない場合、有害な効果をもたらす危険な素材を生成する可能性があります。また、LLMの整列は、他の下流操作のパフォーマンスを向上させます。フィードバックからの強化学習は、整列の問題を解決するために人間の好みを利用します。 報酬モデルは通常、人間の入力によって学習され、その後、強化学習(RL)の目標として使用されるため、LLMを微調整するために使用されます。RLHF技術では、PPOやA2CのようなオンラインRL技術が頻繁に使用されます。オンライントレーニング中に変更されたポリシーをサンプリングする必要があり、サンプルは報酬モデルを使用して繰り返しスコアリングする必要があります。オンラインアプローチは、ポリシーと報酬ネットワークのサイズが拡大するにつれて、新鮮なデータの一定のストリームを処理するための計算費用に制約を受けます。また、これらのアプローチが攻撃を受けやすい「ハッキング」の問題に対処するために、以前の研究ではモデルの正規化を検討しています。代わりに、オフラインRLアルゴリズムは計算効率が高く、報酬ハッキングに対して脆弱性が低いため、事前に定義されたサンプルのデータセットから学習します。 ただし、オフラインデータセットの特性は、オフラインで学習されるポリシーの品質に密接に関連しています。そのため、適切に選択されたデータセットは、オフラインRLの成功には重要です。そうでない場合、教師あり学習よりも性能の向上はわずかかもしれません。彼らはまた、DPO(Direct Preference Optimisation)という手法を提案しています。これは、オフラインデータを使用してLMを人間の好みに合わせることができます。Googleの研究者は、言語モデルの整列の問題を逐次的なRL問題として提示し、彼らのリンフォースドセルフトレーニング(ReST)技術は、2つのループから成り立っています。内側のループ(Improve)は、与えられたデータセット上でポリシーを改善します。一方、外側のループ(Grow)は、最新のポリシーからサンプルを取得してデータセットを拡張します(図1参照)。 図1:ReSTアプローチ。ポリシーはGrowステップでデータセットを作成します。フィルタリングされたデータセットは、Improveステージで言語モデルを微調整するために使用されます。データセットの作成費用を分散するために、Improveフェーズは他の2つのプロセスよりも頻繁に行われます。 この研究では、条件付き言語モデリングを考慮した後、ReSTのフェーズは次のようになります:1. Grow(G):言語モデルポリシー(最初は教師付きポリシー)を使用して、各シナリオごとに数多くの出力予測を生成し、トレーニングデータセットを補完します。2. Improve(I):学習報酬モデルで訓練されたスコアリング関数を使用して、エンリッチドデータセットをランク付けおよびフィルタリングします。フィルタリングされたデータセットは、オフラインRLの目標を持つ言語モデルを調整します。このプロセスをフィルタリングの閾値を増やすことで繰り返します。その後、次のGrowステップでは最終的なポリシーが使用されます。 ReSTは、Improveステップを実行する際に、内側のループでさまざまなオフラインRL損失を使用することを可能にする一般的なアプローチです。 実践するためには、モデルから効果的にサンプリングする能力と、モデルのサンプルをスコアリングする能力が必要です。オンラインまたはオフラインのRLを使用する標準的なRLHFアプローチよりも、ReSTにはいくつかの利点があります: • Growフェーズの出力は、複数のImproveステージで使用されるため、オンラインRLと比較して計算コストが大幅に削減されます。 • Growステップ中に改善されたポリシーから新しいトレーニングデータがサンプリングされるため、ポリシーの品質は元のデータセットの品質に制約されません(オフラインRLとは異なります)。 • データ品質の検査や報酬のハッキングなど、成長と改善のステップが切り離されているため、アラインメントの問題を診断することが簡単です。 • 調整するハイパーパラメータはほとんどなく、技術は直感的で信頼性があります。 機械翻訳は、通常、条件付き言語モデリングとして表現されるシーケンス・トゥ・シーケンス学習の問題であり、外国語のフレーズが条件付けコンテキスト(ソース)として使用されます。彼らは機械翻訳を選択する理由として、(a)堅実なベースラインと明確な評価プロセスを持つ有用なアプリケーションであること、および(b)信頼できるいくつかの現在のスコアリングおよび評価方法を報酬モデルとして使用できることを挙げています。彼らは、IWSLT 2014およびWMT 2020のベンチマーク、およびWebドメインのより難解な内部ベンチマークで、いくつかのオフラインRLアルゴリズムを比較します。ReSTは、試行中のテストセットと検証セットで報酬モデルの結果を劇的に向上させます。人間の評価者によれば、ReSTは教師あり学習のベースラインよりも品質の高い翻訳を生成します。

「機械に学習させ、そして彼らが私たちに再学習をさせる:AIの構築の再帰的性質」
「建築デザインの選択が集団の規範にどのように影響を与えるかを探索し、トレーニング技術がAIシステムを形作り、それが再帰的に人間の行動に影響を与える様子を見てください」

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…

「ドメイン特化LLMの潜在能力の解放」
イントロダクション 大規模言語モデル(LLM)は世界を変えました。特にAIコミュニティにおいて、これは大きな進歩です。テキストを理解し、返信することができるシステムを構築することは、数年前には考えられなかったことでした。しかし、これらの機能は深さの欠如と引き換えに得られます。一般的なLLMは何でも屋ですが、どれも専門家ではありません。深さと精度が必要な領域では、幻覚のような欠陥は高価なものになる可能性があります。それは医学、金融、エンジニアリング、法律などのような領域がLLMの恩恵を受けることができないことを意味するのでしょうか?専門家たちは、既に同じ自己教師あり学習とRLHFという基礎的な技術を活用した、これらの領域に特化したLLMの構築を始めています。この記事では、領域特化のLLMとその能力について、より良い結果を生み出すことを探求します。 学習目標 技術的な詳細に入る前に、この記事の学習目標を概説しましょう: 大規模言語モデル(LLM)とその強みと利点について学びます。 一般的なLLMの制限についてさらに詳しく知ります。 領域特化のLLMとは何か、一般的なLLMの制限を解決するためにどのように役立つのかを見つけます。 法律、コード補完、金融、バイオ医学などの分野におけるパフォーマンスにおけるその利点を示すためのさまざまな領域特化言語モデルの構築について、例を交えて探求します。 この記事はData Science Blogathonの一部として公開されました。 LLMとは何ですか? 大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ人工知能システムであり、テキストを理解し生成するために構築されます。トレーニングでは、モデルにインターネットのテキスト、書籍、記事、ウェブサイトなどからの多数の文を提示し、マスクされた単語または文の続きを予測するように教えます。これにより、モデルはトレーニングされたテキストの統計パターンと言語的関係を学びます。LLMは、言語翻訳、テキスト要約、質問応答、コンテンツ生成など、さまざまなタスクに使用することができます。トランスフォーマーの発明以来、無数のLLMが構築され、公開されてきました。最近人気のあるLLMの例には、Chat GPT、GPT-4、LLAMA、およびStanford Alpacaなどがあり、画期的なパフォーマンスを達成しています。 LLMの強み LLMは、言語理解、エンティティ認識、言語生成の問題など、言語に関するさまざまな課題のためのソリューションとして選ばれるようになりました。GLUE、Super GLUE、SQuAD、BIGベンチマークなどの標準的な評価データセットでの優れたパフォーマンスは、この成果を反映しています。BERT、T5、GPT-3、PALM、GPT-4などが公開された時、それらはすべてこれらの標準テストで最新の結果を示しました。GPT-4は、BARやSATのスコアで平均的な人間よりも高得点を獲得しました。以下の図1は、大規模言語モデルの登場以来、GLUEベンチマークでの大幅な改善を示しています。 大規模言語モデルのもう一つの大きな利点は、改良された多言語対応の能力です。たとえば、104の言語でトレーニングされたマルチリンガルBERTモデルは、さまざまな言語で優れたゼロショットおよびフューショットの結果を示しています。さらに、LLMの活用コストは比較的低くなっています。プロンプトデザインやプロンプトチューニングなどの低コストの方法が登場し、エンジニアはわずかなコストで既存のLLMを簡単に活用することができます。そのため、大規模言語モデルは、言語理解、エンティティ認識、翻訳などの言語に基づくタスクにおけるデフォルトの選択肢となっています。 一般的なLLMの制限 Web、書籍、Wikipediaなどからのさまざまなテキストリソースでトレーニングされた上記のような一般的なLLMは、一般的なLLMと呼ばれています。これらのLLMには、Bing ChatのGPT-4、PALMのBARDなどの検索アシスタント、マーケティングメール、マーケティングコンテンツ、セールスピッチなどのコンテンツ生成タスク、個人チャットボット、カスタマーサービスチャットボットなど、さまざまなアプリケーションがあります。 一般的なAIモデルは、さまざまなトピックにわたるテキストの理解と生成において優れたスキルを示していますが、専門分野にはさらなる深さとニュアンスが必要な場合があります。たとえば、「債券」とは金融業界での借入の形態ですが、一般的な言語モデルはこの独特なフレーズを理解せず、化学や人間同士の債券と混同してしまうかもしれません。一方、領域特化のLLMは、特定のユースケースに関連する専門用語を専門的に理解し、業界固有のアイデアを適切に解釈する能力があります。 また、一般的なLLMには複数のプライバシーの課題があります。たとえば、医療LLMの場合、患者データは非常に重要であり、一般的なLLMに機械学習強化学習(RLHF)などの技術が使用されることで、機密データの公開がプライバシー契約に違反する可能性があります。一方、特定のドメインに特化したLLMは、データの漏洩を防ぐために閉じたフレームワークを確保します。…

「DPOを使用してLlama 2を微調整する」
はじめに 人間のフィードバックからの強化学習(RLHF)は、GPT-4やクロードなどのLLMの最終トレーニングステップとして採用され、言語モデルの出力が人間の期待に合致するようにするために使われます。しかし、これによってRLの複雑さがNLPにもたらされます。良い報酬関数を構築し、モデルに状態の価値を推定するように訓練し、同時に元のモデルからあまり逸脱せずに意味のあるテキストを生成するように注意する必要があります。このようなプロセスは非常に複雑で、正しく行うのは常に簡単ではありません。 最近の論文「Direct Preference Optimization」(Rafailov、Sharma、Mitchell他)では、既存の方法で使用されるRLベースの目的を、シンプルなバイナリクロスエントロピー損失を直接最適化できる目的に変換することを提案しており、これによりLLMの改善プロセスが大幅に簡素化されます。 このブログ記事では、TRLライブラリで利用可能なDirect Preference Optimization(DPO)メソッドを紹介し、さまざまなスタックエクスチェンジポータルの質問に対するランク付けされた回答を含むスタックエクスチェンジのデータセットで最近のLlama v2 7Bパラメータモデルを微調整する方法を示します。 DPO vs PPO 人間の派生した好みをRLを通じて最適化する従来のモデルでは、補助的な報酬モデルを使用し、興味のあるモデルを微調整して、この報酬をRLの仕組みを利用して最大化するようにします。直感的には、報酬モデルを使用して最適化するモデルにフィードバックを提供し、ハイリワードのサンプルをより頻繁に生成し、ローリワードのサンプルをより少なく生成するようにします。同時に、フリーズされた参照モデルを使用して、生成物があまり逸脱せずに生成の多様性を維持し続けるようにします。これは通常、参照モデルを介した全報酬最大化の目的にKLペナルティを追加することで行われ、モデルが報酬モデルをごまかしたり利用したりすることを防ぐ役割を果たします。 DPOの定式化は、報酬モデリングのステップをバイパスし、報酬関数から最適なRLポリシーへの解析的なマッピングを使用して、言語モデルを好みのデータに最適化します。このマッピングは、与えられた報酬関数が与えられた好みのデータとどれだけ合致するかを直感的に測定します。したがって、DPOはRLHFの損失の最適解から始まり、変数の変換を介して参照モデルに対する損失を導出することで、参照モデルのみに対する損失を得ることができます。 したがって、この直接的な尤度目的は、報酬モデルやポテンシャルに煩雑なRLベースの最適化を必要とせずに最適化することができます。 TRLのトレーニング方法 前述のように、通常、RLHFパイプラインは次の異なるパーツで構成されています: 教師あり微調整(SFT)ステップ データに好みのラベルを付けるプロセス 好みのデータで報酬モデルをトレーニングする そして、RL最適化ステップ TRLライブラリには、これらのパーツのためのヘルパーが付属していますが、DPOトレーニングでは報酬モデリングとRL(ステップ3と4)のタスクは必要ありません。代わりに、TRLのDPOTrainerにステップ2の好みのデータを提供する必要があります。このデータは非常に特定の形式を持ちます。具体的には、次の3つのキーを持つ辞書です: prompt:テキスト生成の際にモデルに与えられるコンテキストプロンプトです…

「生成型AI:CHATGPT、Dall-E、Midjourneyなどの背後にあるアイデア」
芸術、コミュニケーション、そして現実の認識の世界は急速に変化しています人間のイノベーションの歴史を振り返ると、車輪の発明や電気の発見などを画期的な飛躍と考えることがあります今日、人間の創造性と機械の計算との間に溝を埋める新たな革命が起こっていますそれは[…]

『nnU-Netの究極ガイド』
「画像セグメンテーションの主要なツールであるnnU-Netについて、詳細なガイドに深く入り込んでください最先端の結果を得るための知識を獲得しましょう」

ライトオンAIは、Falcon-40Bをベースにした新しいオープンソースの言語モデル(LLM)であるAlfred-40B-0723をリリースしました
画期的な動きとして、LightOnは誇りを持って、Falcon-40Bに基づく革新的なオープンソースの言語モデル(LLM)であるAlfred-40B-0723のローンチを発表しました。この最先端のモデルは、ジェネレーティブAIをシームレスにワークフローに統合したい企業のニーズに特化して設計された、そのようなモデルとしては初めてのものです。エンタープライズは、Alfredとともに、ジェネレーティブAIのフルポテンシャルを引き出し、効率的に目標を達成するための頼れるパートナーを手に入れました。 Alfredは、そのコアとなる強力かつ多機能な言語モデルで、従来のLLMとは一線を画するさまざまなキーフィーチャーを提供しています。その1つの特徴的な機能は、「プロンプトエンジニアリング」であり、Alfredはユーザーが特定のニーズに合わせて効果的なプロンプトを構築し評価するのに優れています。このユニークな機能により、高い精度とパフォーマンスが保証され、企業は各自の産業で競争力を持つことができます。 さらに、Alfredの「ノーコードアプリケーション開発」機能を利用すると、コーディングの知識がなくてもアプリケーションを作成することができます。この時間の節約機能は、開発を加速するだけでなく、貴重なリソースを節約するため、ワークフローを最適化したい企業にとって理想的な選択肢です。 最先端の機能に加えて、Alfredは、コンテンツの要約、ドキュメントのクエリ応答、コンテンツの分類、およびキーワードの抽出など、言語モデルに期待されるすべての従来のタスクを実行することができます。その多様性により、さまざまな産業において広範な応用が可能な貴重なツールとなっています。 Alfred-40B-0723は、ジェネレーティブAIのコパイロットであるFalcon RLHFによってパワードされており、この分野での重要な進歩を表しています。人間のフィードバックからの強化学習を活用したAlfredは、LightOnの専任チームによって注釈が施された公開データセットと高度にキュレーションされたデータのミックスを用いて徹底的にトレーニングされています。この入念なトレーニングプロセスにより、Alfredは頑健でありながらも複雑なタスクに対して高品質な出力を理解し提供する能力を備えています。 エンタープライズ向けのジェネレーティブAIプラットフォームであるParadigmは、Alfred-40B-0723の真のポテンシャルを最大限に活用しています。Alfredは、ユーザーがタスクの成功基準を定義し、プロンプトを洗練させるのをサポートするジェネレーティブAIのコパイロットとして、この進化し続ける分野への進出を検討している人々にとって、すぐに使えるソリューションを提供します。ただし、LightOnはAlfredをオープンソースモデルとして提供していますが、Paradigmプラットフォームバージョンにはさらなる進化があり、ジェネレーティブAIの限界を押し広げることにLightOnが取り組んでいることを示しています。 Alfred-40B-0723のトレーニングには、スケーラブルなインフラストラクチャを提供するAWS SagemakerとのLightOnのパートナーシップが重要な役割を果たしています。このコラボレーションにより、モデルの効率性と信頼性が確保され、個々の開発者と大規模な組織の両方にアクセス可能となっています。ジェネレーティブAIコミュニティ内でのコラボレーションとイノベーションを促進するためのLightOnの取り組みの一環として、Alfredは現在HuggingFaceでも利用可能であり、Foundation Models向けのAWS Jumpstartでも近日中に利用可能となります。 オープンソースモデルとしてAlfred-40B-0723を共有することで、LightOnは開発者、研究者、組織に対して可能性を探求し、さらなる開発に貢献することを招待しています。ジェネレーティブAIコミュニティ内での協力は、その全ての可能性を解き放つために不可欠であり、さまざまな産業を変革するのに役立ちます。 まとめると、Alfred-40B-0723は、ジェネレーティブAIの世界での大きな進歩を表しています。その高度な機能と協力的でオープンなアプローチにより、ワークフローを向上させ、ジェネレーティブAIの変革力を活用することを求める企業にとって貴重な資産となっています。信頼できる味方としてのAlfredと共に、エンタープライズは革新の旅に乗り出し、最先端のテクノロジーによって支えられた未来を受け入れることができます。
大規模言語モデルの挙動を監視する7つの方法
自然言語処理の世界では、大規模言語モデル(LLM)の使用による急速な進化が見られています彼らの印象的なテキスト生成およびテキスト理解能力を通じて、LLMは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.