Learn more about Search Results Nature - Page 10

- You may be interested
- 予測API:DjangoとGoogle Trendsの例
- 「アメリカの機械学習エンジニアの給与」
- ミストラルAI オープンソースのラマ2を超...
- コーネル大学の研究者たちは、言語モデル...
- 「AIの使用を支持する俳優たちと、支持し...
- 「LangChainとChatGPTを使用してPythonコ...
- 「OpenAIの研究者たちは、敵対的なトレー...
- 創造力を解き放つ:ジェネレーティブAIとA...
- 「VAST DataのプラットフォームがAIイノベ...
- 「Amazon SageMakerの最新機能を使用する...
- LLMのトレーニングの異なる方法
- サイバーセキュリティが食品と農業を守る
- 「Amazon SageMakerを使用したフェデレー...
- 「単一細胞生物学のAIのフロンティアを探...
- 「OpenAI Pythonライブラリ&Pythonで実践...

ピンクのローバーが赤い惑星に取り組む、科学における女性の障壁
オーストラリアのチームは、ピンク色のロボットローバーを使用して、ユタ州ハンクスビルで開催されたUniversity Rover Challengeで2位に入りました
未来への進化-新しいウェーブガイドがデータの転送および操作方法を変えています
物理学者たちは、メタサーフェス上で電磁スピンをエンジニアリングする方法を開拓し、ますますデジタル化する世界のデータストレージと転送のニーズに対応しています

「経済成長を遅らせることなく、量子コンピュータを導入する方法」
「量子革命の進展をスムーズにするために、研究者や政府は先に待ち受ける障害を予測し、準備する必要があります」

「太陽エネルギーが新たな展開を迎える」
「太陽光葉技術を通じた人工光合成の利用に焦点を当てています」

「信頼性の高い医療用AIツールの開発」
「私たちはGoogle Researchとの共同論文をNature Medicineに掲載しましたこの論文では、CoDoC(Complementarity-driven Deferral-to-Clinical Workflow)というAIシステムを提案していますこのシステムは、医療画像の最も正確な解釈について、予測AIツールに頼るべきか、臨床医に委ねるべきかを学習します」

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…

TF Servingを使用してHugging FaceでTensorFlow Visionモデルを展開する
過去数ヶ月間、Hugging Faceチームと外部の貢献者は、TransformersにさまざまなビジョンモデルをTensorFlowで追加しました。このリストは包括的に拡大しており、ビジョントランスフォーマー、マスク付きオートエンコーダー、RegNet、ConvNeXtなど、最先端の事前学習モデルがすでに含まれています! TensorFlowモデルを展開する際には、さまざまな選択肢があります。使用ケースに応じて、モデルをエンドポイントとして公開するか、アプリケーション自体にパッケージ化するかを選択できます。TensorFlowには、これらの異なるシナリオに対応するツールが用意されています。 この投稿では、TensorFlow Serving(TF Serving)を使用してローカルでビジョントランスフォーマーモデル(画像分類用)を展開する方法を紹介します。これにより、開発者はモデルをRESTエンドポイントまたはgRPCエンドポイントとして公開できます。さらに、TF Servingはモデルのウォームアップ、サーバーサイドバッチ処理など、多くの展開固有の機能を提供しています。 この投稿全体で示される完全な動作するコードを取得するには、冒頭に示されているColabノートブックを参照してください。 🤗 TransformersのすべてのTensorFlowモデルには、save_pretrained()というメソッドがあります。このメソッドを使用すると、モデルの重みをh5形式およびスタンドアロンのSavedModel形式でシリアライズできます。TF Servingでは、モデルをSavedModel形式で提供する必要があります。そこで、まずビジョントランスフォーマーモデルをロードして保存します。 from transformers import TFViTForImageClassification temp_model_dir = "vit" ckpt = "google/vit-base-patch16-224" model = TFViTForImageClassification.from_pretrained(ckpt)…
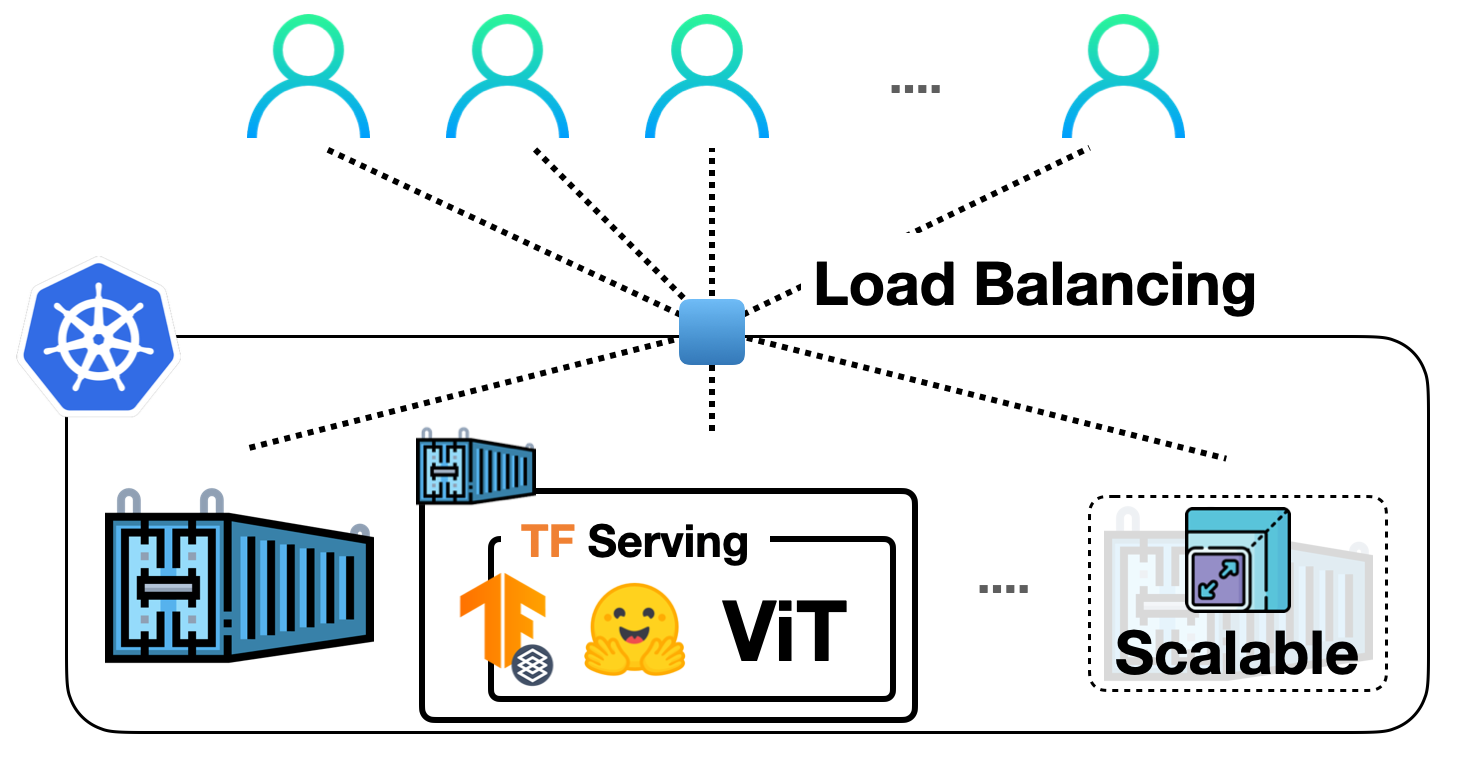
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…
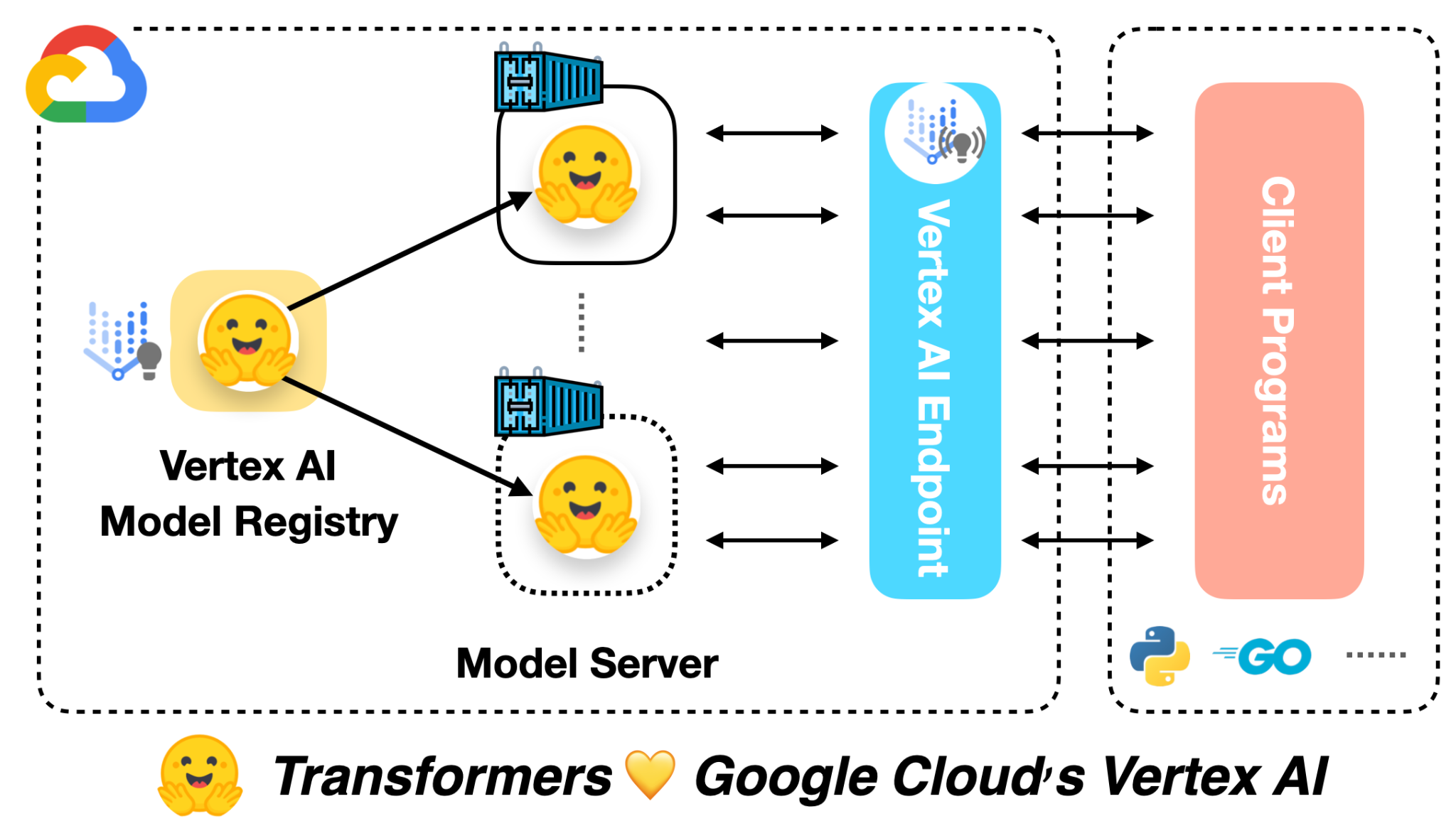
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.