Learn more about Search Results Gin - Page 10

- You may be interested
- 「Python Pre-Commitフックを使用して、コ...
- 中国の研究者が提案する、新しい知識統合...
- 「日本のショーが救助活動の未来としてロ...
- データ分析の最適化:DatabricksにGitHub ...
- 「ジェーン・ザ・ディスカバラー:大規模...
- 「CMU研究者がニューラルネットワークの挙...
- ハリウッドにおけるディズニーの論争:AI...
- 🤗 Hubでのスーパーチャージド検索
- 「ニューラルネットワークとディープラー...
- 大型モデルがビッグデータと出会う:スパ...
- 「データパイプラインについての考え方が...
- 「研究者が深層学習と物理学を組み合わせ...
- 「FAANGまたはスタートアップでキャリアを...
- 大規模言語モデルにおける文脈の長さの拡張
- バイトダンスとUCSDの研究者は、与えられ...

Hugging FaceとAWSが協力し、AIをよりアクセスしやすくするためにパートナーシップを結成
AIをすべての人に開放し、アクセス可能にする時が来ました。それがHugging FaceとAmazon Web Services(AWS)の拡大した長期戦略的パートナーシップの目標です。両社は、次世代の機械学習モデルの利用可能性を加速させ、機械学習コミュニティがよりアクセスしやすくなり、開発者が最高のパフォーマンスを最低のコストで実現できるよう支援することを目指しています。 新しい世代のオープンでアクセス可能なAI 機械学習はすぐにすべてのアプリケーションに組み込まれつつあります。経済のあらゆるセクターに与える影響が明確になるにつれて、最新のモデルにアクセスし、評価できるようにすることは、これまで以上に重要になっています。AWSとのパートナーシップは、専用のツールを使用してクラウドで最新の機械学習モデルを構築、トレーニング、展開することをより迅速かつ容易にすることで、この未来への道を切り拓いています。 テキスト、音声、画像を処理および生成する新しいTransformerおよびDiffuserの機械学習モデルには、大幅な進歩がありました。しかし、これらの人気のある生成AIモデルのほとんどは公開されておらず、最大のテック企業と他のすべての企業との機械学習能力のギャップを広げています。この傾向に対抗するため、AWSとHugging Faceは協力して、次世代のモデルをグローバルなAIコミュニティに提供し、機械学習を民主化します。戦略的パートナーシップを通じて、Hugging FaceはAWSを優先的なクラウドプロバイダーとして活用し、Hugging Faceのコミュニティの開発者がAWSの最新のツール(Amazon SageMaker、AWS Trainium、AWS Inferentiaなど)にアクセスして、モデルをトレーニング、微調整、展開することができるようにします。これにより、開発者は特定のユースケースに対してモデルのパフォーマンスをさらに最適化し、コストを削減することができます。Hugging Faceは、Amazon SageMakerを使用して最新の革新的な研究成果を適用し、次世代のAIモデルを構築します。Hugging FaceとAWSは、機械学習の最新の進展をグローバルなAIコミュニティが利用できるようにし、生成AIアプリケーションの作成を加速させるためのギャップを埋めています。 「AIの未来はここにありますが、均等には分布していません」とHugging FaceのCEOであるClement Delangueは述べています。「アクセシビリティと透明性は、進歩を共有し、これらの新しい機能を賢明かつ責任を持って使用するためのツールを作成するための鍵です。Amazon SageMakerとAWS設計のチップは、私たちのチームとより大きな機械学習コミュニティが最新の研究をオープンに再現可能なモデルに変換できるようにします。誰でもそれを基礎に構築することができます」。 クラウドでAIを拡大するための協力 この拡大した戦略的パートナーシップにより、Hugging FaceとAWSは、Hugging Faceにホストされている最新のモデルをAmazon…

複雑なテキスト分類のユースケースにおいて、Hugging Faceを活用する
Hugging Faceエキスパートアクセラレーションプログラムとのウィティワークスの成功物語 MLソリューションの迅速な構築に興味がある場合は、エキスパートアクセラレーションプログラムのランディングページをご覧いただき、こちらからお問い合わせください! ビジネスコンテキスト ITが進化し、世界を変え続ける中、業界内でより多様で包括的な環境を作り上げることが重要です。ウィティワークスは、この課題に取り組むために2018年に設立されました。最初は多様性を高めるための組織へのコンサルティング企業としてスタートし、ウィティワークスはまず、包括的な言語を使用した求人広告の作成において彼らを支援しました。この取り組みを拡大するため、2019年には英語、フランス語、ドイツ語で包括的な求人広告の作成を支援するWebアプリを開発しました。そして、その後、ブラウザ拡張機能として機能するライティングアシスタントを追加し、メール、LinkedInの投稿、求人広告などで潜在的なバイアスを自動的に修正し、説明するようにしました。目的は、ハイライトされた単語やフレーズの潜在的なバイアスを説明するマイクロラーニングの手法を提供することで、内部および外部のコミュニケーションにおける文化的変革を促進することでした。 ライティングアシスタントによる提案の例 最初の実験 ウィティワークスは最初に、アシスタントをゼロから構築するために基本的な機械学習アプローチを選びました。事前学習済みのspaCyモデルを使用した転移学習を行い、アシスタントは次のことができました: テキストを分析し、単語をレンマに変換する 言語分析を実行する テキストから言語的な特徴を抽出する(複数形と単数形、性別)、品詞タグ(代名詞、動詞、名詞、形容詞など)、単語の依存関係ラベル、名前付きエンティティの認識など 言語的な特徴に基づいて単語を検出・フィルタリングし、アシスタントは非包括的な単語をリアルタイムでハイライトし、代替案を提案することができました。 課題 語彙には約2300の非包括的な単語やイディオムがあり、それに対して基本的なアプローチは語彙の85%に対してうまく機能しましたが、文脈に依存する単語には失敗しました。そのため、課題は文脈に依存した非包括的な単語の分類器を構築することでした。このような課題(言語的な特徴を認識するのではなく、文脈を理解すること)は、Hugging Face transformersの使用につながりました。 文脈に依存した非包括的な単語の例: 化石燃料は再生可能な資源ではありません。Vs 彼は古い化石です。 柔軟なスケジュールを持っています。Vs スケジュールを柔軟に保つ必要があります。 Hugging Faceエキスパートが提供するソリューション 適切なMLアプローチを決定するためのガイダンスを受ける。…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…
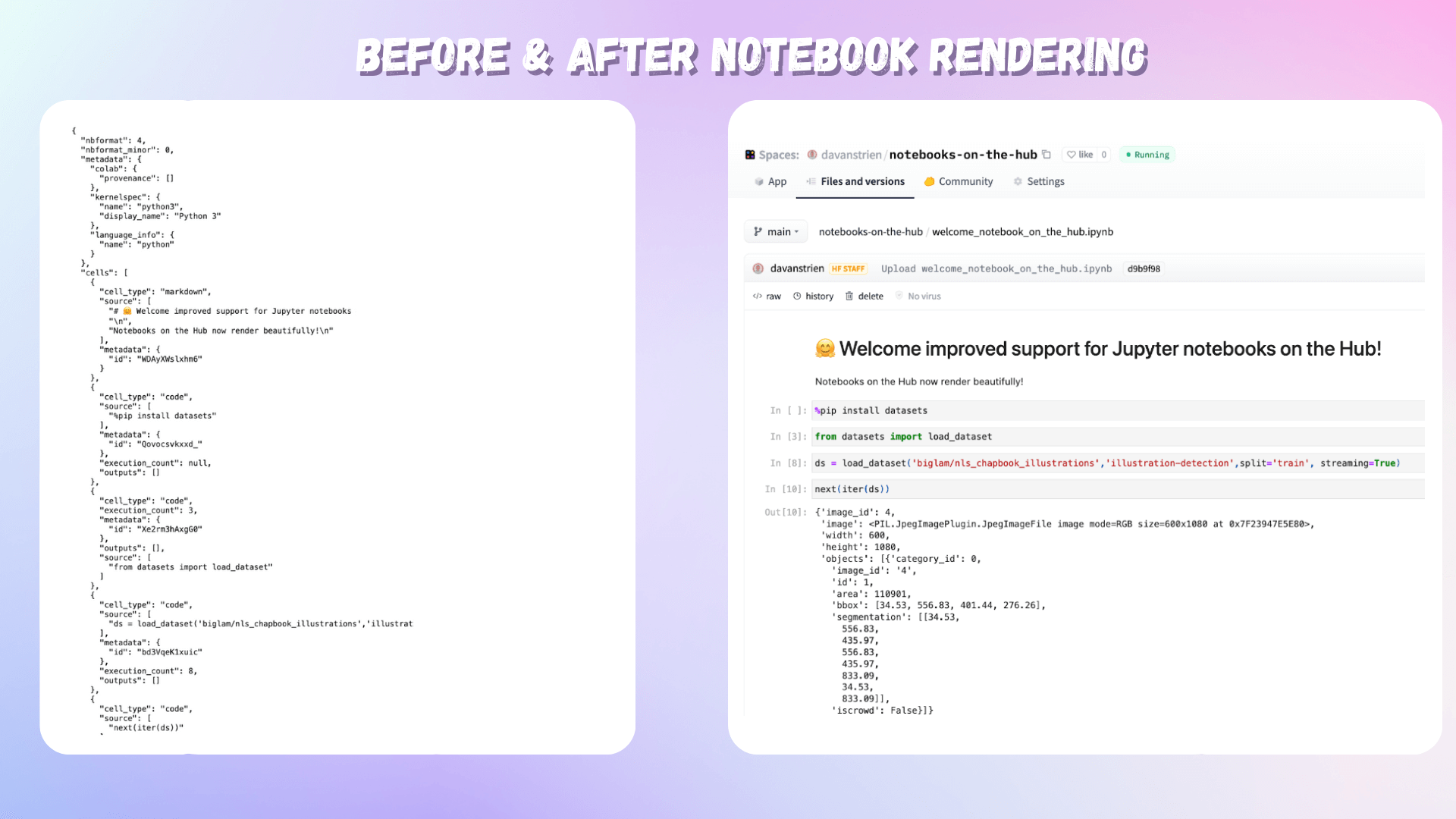
Jupyter × Hugging Face
私たちは、Hugging Face HubでホストされているJupyterノートブックへのサポートを改善したことをお知らせします! Jupyterノートブックは、学習のための重要なリソースとしてだけでなく、モデル開発に使用される主要なツールとして、機械学習のさまざまな分野で重要な要素となっています。ノートブックのインタラクティブでビジュアルな性質により、モデル、データセット、デモを開発する際に素早くフィードバックを受けることができます。多くの人にとって、機械学習モデルのトレーニングへの最初の接触はJupyterノートブックを通じて行われ、多くの実践者はノートブックを自分の作業を開発し、共有するための重要なツールとして使用しています。 Hugging Faceは、共同作業型の機械学習プラットフォームであり、コミュニティは15万以上のモデル、2万5000以上のデータセット、3万以上のMLアプリを共有しています。Hubにはモデルやデータセットのバージョニングツールがあり、モデルカードやクライアントサイドのライブラリを使用してバージョニングプロセスを自動化することができます。ただし、ハイパーパラメータとモデルカードを含めるだけでは、最良の再現性を提供するには十分ではありません。これがノートブックが役立つ場所です。これらのモデル、データセット、デモと共に、Hubには7000以上のノートブックがホストされています。これらのノートブックは、モデルやデータセットの開発プロセスを文書化し、他の人がこれらのリソースをどのように使用できるかを示すガイダンスやチュートリアルを提供することがよくあります。そのため、Hubでのノートブックのホスティングに対する私たちの改善されたサポートには、興奮しています。 何を変更しましたか? Jupyterノートブックファイル(通常はipynb拡張子で共有される)は、JSONファイルです。これらのファイルを直接表示することは可能ですが、人間が読むことを意図した形式ではありません。私たちは、Hubでホストされているノートブックのレンダリングサポートを追加しました。これにより、ノートブックは人間が読みやすい形式で表示されるようになりました。 Hubでホストされているノートブックのレンダリング前後の比較画像 なぜ私たちはHub上でより多くのノートブックをホストすることに興奮しているのでしょうか? ノートブックは、他の人があなたが作成し、共有したリソースを使用する方法を文書化するのに役立ちます。モデルやデータセットと同じ場所でノートブックを共有することで、他の人が作成したリソースを簡単に使用できるようになります。 多くの人々がHubを使用して機械学習のポートフォリオを開発しています。これにより、Jupyterノートブックを使用してこのポートフォリオを補完することができます。 HubでホストされているノートブックをGoogle Colabでワンクリックで直接開くサポートが追加されました。今後の発表にご期待ください!

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…

倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
ミッション:オープンで良い機械学習 私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。 MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。 ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。 私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。 倫理的なカテゴリ 私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。 ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています: 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。 コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。 詳細はhttps://huggingface.co/ethicsをご覧ください。 これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます! セーフガード オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。 私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています: コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。 ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

中国語話者向けのHuggingFaceブログをご紹介します:中国のAIコミュニティとの協力の促進
この記事は、中国語の 简体中文 でもご覧いただけます。 中国語話者向けのブログへようこそ! Hugging Faceの新しい中国語話者向けブログ hf.co/blog/zh をご紹介いたします!献身的なボランティアのグループが、ブログ投稿やトランスフォーマー、ディフュージョン、強化学習に関する包括的なコースなど、私たちの貴重なリソースを翻訳することで、この可能性を実現しました。この取り組みは、急速に成長する中国のAIコミュニティに私たちのコンテンツを利用しやすくすることを目的としており、相互の学習と協力を促進します。 中国のAIコミュニティの成果を認識する 私たちは、優れた才能と革新を示した中国のAIコミュニティの驚異的な成果と貢献を強調したいと考えています。HuggingGPT、ChatGLM、RWKV、ChatYuan、ModelScopeのテキストからビデオへのモデル、さらにはIDEA CCNLとBAAIの貢献など、画期的な進展は、コミュニティ内にある信じられないほどの可能性を示しています。 さらに、中国のAIコミュニティは、Chuanhu GPTやGPT Academyなどのトレンディなスペースの創造にも積極的に取り組んでおり、その熱意と創造性を示しています。 私たちは、PaddlePaddleなどの組織と協力して、Hugging Faceとのシームレスな統合を実現し、機械学習の領域でのより多くの共同作業を可能にしています。 協力関係と将来のイベントの強化 私たちは、中国の協力者との協力の歴史に誇りを持ち、知識の交換と協力を可能にするさまざまなイベントで一緒に働いてきました。私たちの協力の一部には、次のものがあります: DataWhaleとのオンラインChatGPTコース(進行中) JAX/Diffusersコミュニティスプリントのための北京での初めてのオフラインミートアップ Baixing AIとのPromptエンジニアリングハッカソンの主催 PaddlePaddleとのLoraモデルの微調整 HeyWhaleのイベントでの安定したディフュージョンモデルの微調整…
Hugging Face Unity APIのインストールと使用方法
Hugging Face Unity APIは、Hugging Face Inference APIの簡単に使用できる統合です。これにより、開発者はUnityプロジェクトでHugging Face AIモデルにアクセスして使用することができます。このブログ投稿では、Hugging Face Unity APIのインストールと使用方法について説明します。 インストール Unityプロジェクトを開きます Window -> Package Managerに移動します +をクリックし、Add Package from git URLを選択します https://github.com/huggingface/unity-api.gitを入力します…

Hugging FaceとIBMは、AIビルダー向けの次世代エンタープライズスタジオであるwatsonx.aiにおいてパートナーシップを結成しました
すべてのハイプを置いておくと、AIが社会とビジネスに与える深い影響を否定するのは難しいです。スタートアップから企業まで、公共部門まで、私たちが話すすべての顧客は、大規模な言語モデルと生成的AIを実験し、最も有望なユースケースを特定し、徐々に本番環境に導入することに忙しいと言っています。 顧客から最もよくいただくコメントは、1つのモデルがすべてを支配するわけではないということです。彼らは、各ユースケースに最適なモデルを構築し、企業データに最大の関連性を持たせながら、計算予算を最適化する価値を理解しています。もちろん、プライバシーと知的財産も最優先の関心事であり、顧客は完全な制御を確保したいと考えています。 AIがすべての部門やビジネスユニットに浸透するにつれて、顧客は多くの異なるモデルのトレーニングと展開の必要性も認識しています。大規模な多国籍組織では、いつでも何百、何千ものモデルを実行することがあります。AIの革新のペースに応じて、より新しいパフォーマンスの高いモデルアーキテクチャは、顧客が予想よりも早くモデルを置き換えることになります。そのため、新しいモデルを迅速かつシームレスに本番環境にトレーニングおよび展開する必要性が強まります。 これは、標準化と自動化のみで実現できます。組織は、新規プロジェクトのためにモデル、ツール、およびインフラをゼロから構築する余裕はありません。幸いなことに、ここ数年間ではいくつかの非常にポジティブな進展がありました: モデルの標準化:Transformerアーキテクチャは、自然言語処理、コンピュータビジョン、音声、音響などのDeep Learningアプリケーションにおいて事実上の標準となりました。今では、多くのユースケースで優れたパフォーマンスを発揮するツールやワークフローを構築することが容易になりました。 事前学習済みモデル:何十万もの事前学習済みモデルがすぐに利用可能です。Hugging Face上で直接発見し、テストでき、プロジェクトに向けてすぐに有望なモデルを選定することができます。 オープンソースライブラリ:Hugging Faceのライブラリを使用すると、1行のコードで事前学習済みモデルをダウンロードし、数分でデータを試すことができます。トレーニングから展開、ハードウェアの最適化まで、顧客はコミュニティ主導の一貫したツールセットに頼ることができます。これらのツールは、彼らのノートパソコンから本番環境まで、どこでも同じように動作します。 さらに、私たちのクラウドパートナーシップにより、顧客はHugging Faceのモデルとライブラリをインフラストラクチャのプロビジョニングや技術環境の構築に心配することなく、任意のスケールで使用することができます。これにより、高品質なモデルを迅速に提供することが容易になり、車輪の再発明をする必要がありません。 AWSとのAmazon SageMaker、およびMicrosoftとのAzure Machine Learningとのコラボレーションに続いて、私たちはIBMとも協力して、彼らの新しいAIスタジオ、watsonx.aiでの作業に興奮しています。watsonx.aiは、従来のMLと新しい生成的AIの能力の両方をトレーニング、検証、チューニング、および展開するための次世代のエンタープライズスタジオです。これらの能力は、ファウンデーションモデルによって強化されます。 IBMは、watsonx.aiのコアにオープンソースを採用することを決定しました。私たちも同じ意見です!watsonx.aiは、RedHat OpenShift上に構築され、クラウドとオンプレミスの両方で利用できます。これは、厳格なコンプライアンスルールによりクラウドを使用できない顧客や、機密データをインフラストラクチャ上で扱うことにより快適な顧客にとって、素晴らしいニュースです。これまで、これらの顧客はしばしば社内で独自のMLプラットフォームを構築する必要がありました。しかし、彼らは今や、標準のDevOpsツールを使用して展開および管理されるオープンソースの代替品を手に入れることができます。 watsonx.aiの内部では、transformers(10万以上のGitHubスター!)、accelerate、peft、およびText Generation Inferenceサーバーなど、Hugging Faceのオープンソースライブラリが多数統合されています。私たちはIBMと協力し、watsonx AIおよびデータプラットフォームに取り組んでいます。これにより、Hugging Faceの顧客は、Hugging…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.