Learn more about Search Results 限定的 - Page 10

- You may be interested
- リモートワーク時代における新しいデータ...
- AIによって発見された初めての超新星
- 「Amazon EC2 Inf1&Inf2インスタンス上の...
- 「14/8から20/8までの週のトップ重要なコ...
- 「Pandasを使用したSpark上のPythonの並列...
- ChatGPTカスタム指示の使用方法(6つのユ...
- 「月探査ツアーでのロボットチーム」
- 『Stack OverflowがOverflowをリリース:...
- 「数値処理者がクジラが奇妙な行動をして...
- 「Vianaiの新しいオープンソースのソリュ...
- 「Baichuan-13Bに会いましょう:中国のオ...
- 「ビジネスを拡大するための25のChatGPTプ...
- AIによるなりすましからの戦い
- データサイエンスの職名の進む道:データ...
- Googleの研究者たちは、AIによって生成さ...

「AudioGPTをご紹介します:ChatGPTとオーディオファウンデーションモデルを結ぶマルチモーダルAIシステム」
AIコミュニティは、大規模言語モデルの影響を受けており、ChatGPTとGPT-4の導入により、自然言語処理が進化しています。広範なウェブテキストデータと堅牢なアーキテクチャのおかげで、LLM(大規模言語モデル)は人間のように読み書きや会話ができます。テキスト処理や生成における成功事例がある一方、音声モダリティ(音楽、音声、トーキングヘッド)の成功は限定的です。以下の理由から、音声モダリティの成功は非常に有利でありながらも制約があります。1)現実のシナリオでは、人々は日常の会話で話される言語を使用してコミュニケーションを取り、生活をより便利にするために音声アシスタントを使用します。2)人工生成の成功を達成するためには、音声モダリティ情報の処理が必要です。 LLMがより高度なAIシステムに向けて進むための重要なステップは、声、音楽、音声、トーキングヘッドの理解と生成です。音声モダリティの利点にもかかわらず、実際の世界での会話を含む実際の音声データを提供するソースは非常に少なく、人間によるラベル付き音声データの取得は費用と時間がかかります。さらに、広範なウェブテキストデータの対に多言語対話音声データが必要であり、データ量が限られています。また、スクラッチからマルチモーダルLLMをトレーニングするためには、計算リソースが要求され、時間がかかります。 この研究では、浙江大学、北京大学、カーネギーメロン大学、中国の北京大学の研究者らが「AudioGPT」というシステムを提案しています。このシステムは、音声対話における音声モダリティの理解と生成に優れた性能を持つように作られています。具体的には以下のような特徴があります。 マルチモーダルLLMをスクラッチからトレーニングする代わりに、さまざまな音声基盤モデルを使用して複雑な音声情報を処理します。 音声対話のための入出力インターフェースをLLMに接続して、音声言語モデルをトレーニングする代わりに使用します。 LLMを汎用インターフェースとして使用し、AudioGPTがさまざまな音声理解と生成のタスクを解決できるようにします。 音声基盤モデルは既に音声、音楽、音声、トーキングヘッドを理解し生成できるため、ゼロからトレーニングを開始することは無意味です。 入出力インターフェース、ChatGPT、音声言語を使用することで、LLMは音声をテキストに変換することでより効果的にコミュニケーションすることができます。ChatGPTは会話エンジンとプロンプトマネージャを使用して、音声データの処理時にユーザーの意図を判断します。AudioGPTのプロセスは、図1に示すように4つのパートに分かれます。 • モダリティの変換:入出力インターフェース、ChatGPT、音声言語を使用して、LLMは音声をテキストに変換することでより効果的にコミュニケーションすることができます。 • タスクの分析:ChatGPTは会話エンジンとプロンプトマネージャを使用して、音声データの処理時にユーザーの意図を判断します。 • モデルの割り当て:ChatGPTは、抑揚、音色、言語制御のための構造化引数を受け取った後、音声基盤モデルを理解と生成のために割り当てます。 • 応答の設計:音声基盤モデルの実行後、応答を生成し、ユーザーに最終的な回答を提供します。 図1:AudioGPTの概要。モダリティの変換、タスクの分析、モデルの割り当て、応答の生成の4つのプロセスで構成されています。困難な音声のジョブを処理するために、ChatGPTに音声基盤モデルを提供します。また、音声コミュニケーションを可能にするためにモダリティ変換インターフェースに接続します。マルチモーダルLLMの一貫性、容量、堅牢性を評価するための設計ガイドラインを開発しました。 マルチモーダルLLMの効果を評価し、さまざまな基盤モデルの協調をオーケストレーションする能力は、ますます人気のある研究課題となっています。実験結果から、AudioGPTは異なるAIアプリケーションのために複雑な音声データをマルチラウンドの対話で処理することができます。この研究では、AudioGPTの一貫性、容量、堅牢性の設計コンセプトと評価手順について説明しています。 彼らは、高度な音声ジョブに対してChatGPTに音声基盤モデルを提供するAudioGPTを提案しています。これは論文の主要な貢献の1つです。音声コミュニケーションを可能にするために、モダリティ変換インターフェースをChatGPTと組み合わせました。この研究では、マルチモーダルLLMの一貫性、容量、堅牢性を評価し、AudioGPTの理解と生成が効果的に行われます。コードはGitHubでオープンソースとして公開されています。
アップリフトモデルの評価
業界での因果推論の最も広く利用されているアプリケーションの1つは、アップリフトモデリング、または条件付き平均治療効果の推定ですある処置の因果効果を推定する際には、

「人工知能と自由意志」
人工知能の非凡な能力は今や明白です例えば、チェスをプレイするような特定のことは、AIがどんな人間よりも優れて行えますし、多くのことにおいても、典型的な人間よりも優れた成果を収めることができます...

Jasper AI レビュー(2023年7月):最高のAIライティングジェネレーター?
「このJasper AIのレビューで最高のAIライティングジェネレーターを発見しましょう!このパワフルなツールで創造性と生産性を解き放ってください」

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…
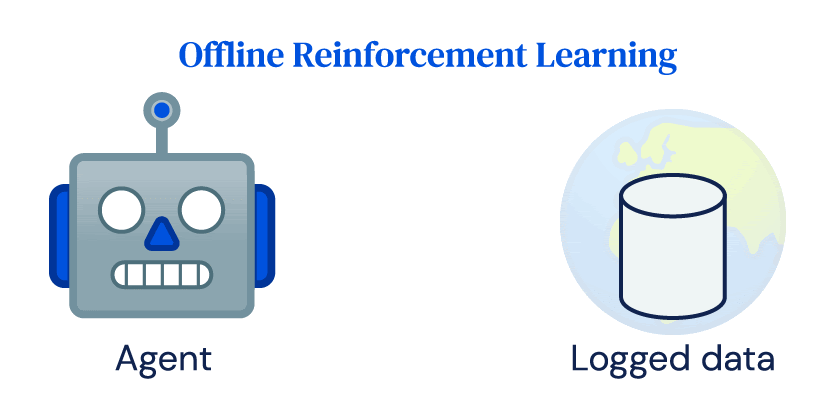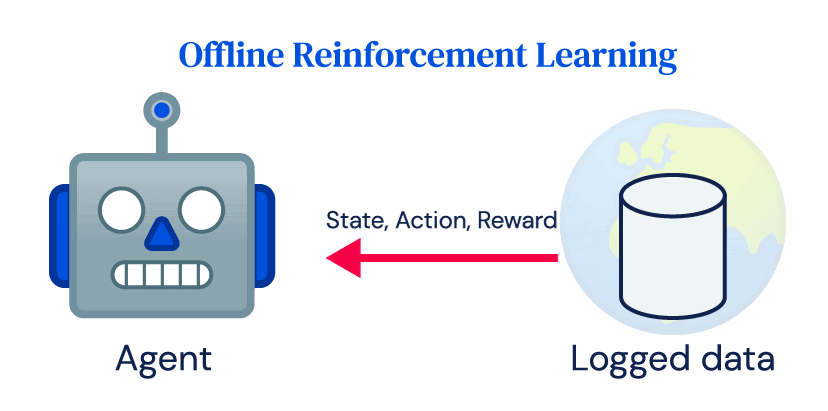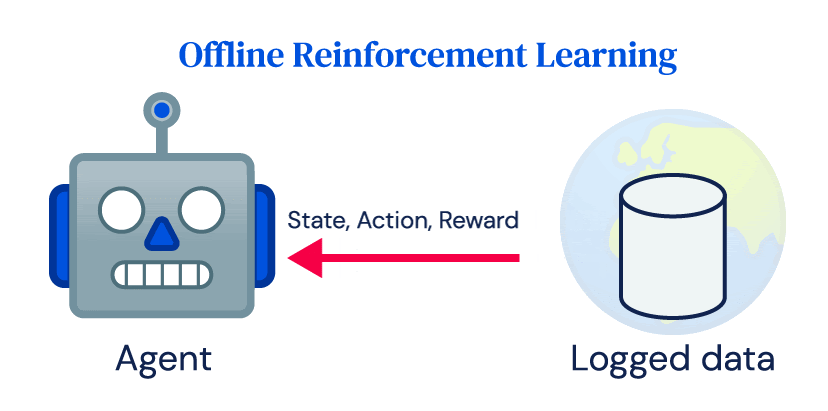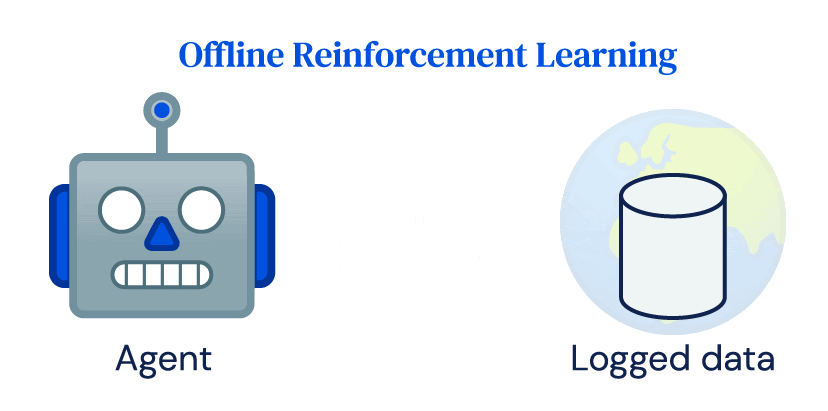
RLアンプラグド:オフライン強化学習のベンチマーク
私たちは、オフラインRL(強化学習)手法の評価と比較を行うためのベンチマークとして「RL Unplugged」というものを提案していますRL Unpluggedには、Atariベンチマークなどのゲームや、DM Control Suiteなどのシミュレートされたモーターコントロール問題など、さまざまなドメインのデータが含まれていますこれらのデータセットには、部分的または完全に観測可能なドメイン、連続または離散のアクションの使用、確率的または確定的なダイナミクスがあるドメインなどが含まれています
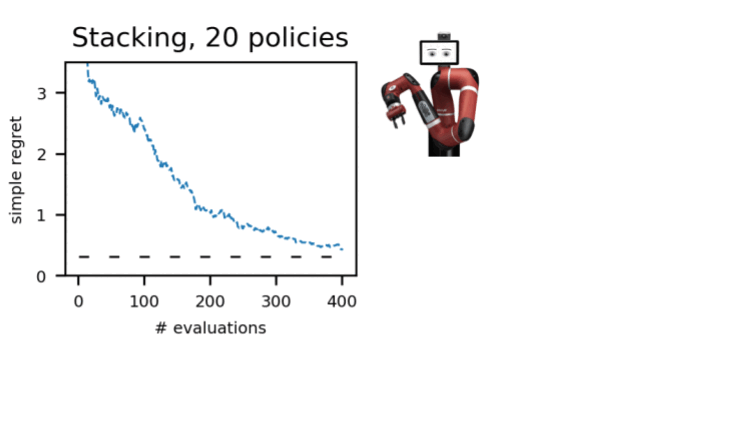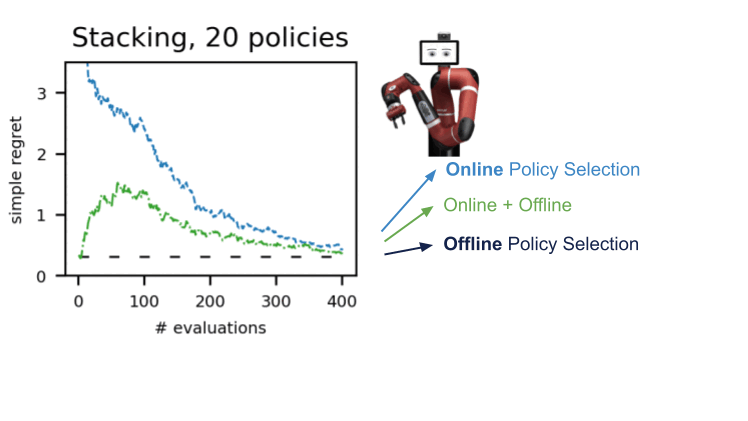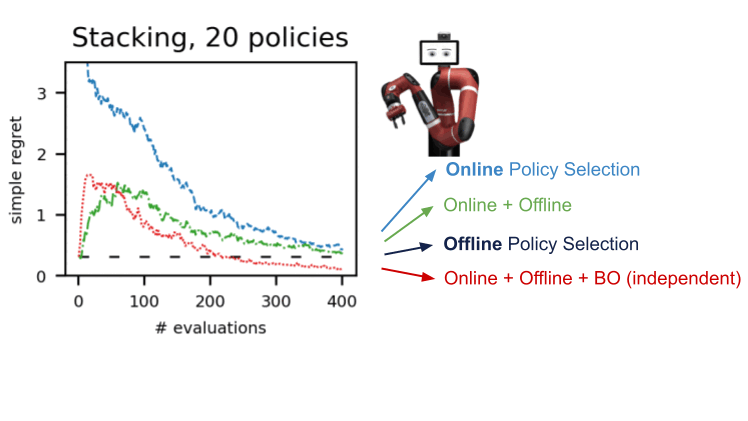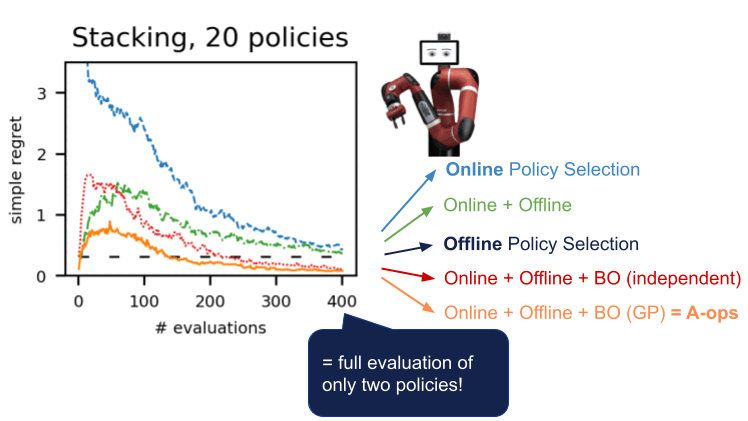
オフラインでのアクティブなポリシー選択
実際のロボット工学などの現実世界のアプリケーションに強化学習をより適用可能にするために、私たちは展開に適した方針を選択するための知的な評価手法、アクティブオフラインポリシー選択(A-OPS)を提案しますA-OPSでは、事前に録画されたデータセットを活用し、限定的な実環境との相互作用を許可することで、選択の品質を向上させます

発達心理学に触発された深層学習モデルによる直感的な物理学の学習
現在のAIシステムは、非常に若い子供に比べても直感的な物理学の理解において劣っています本研究では、このAIの問題に取り組み、具体的には発達心理学の分野に基づいています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.