Learn more about Search Results 勾配降下法 - Page 10

- You may be interested
- ドキュメントAIの加速
- 「信頼性の高い医療用AIツールの開発」
- 「注目のAI GitHubリポジトリ:2023年11月...
- 自動化されたアクセシビリティテストと手...
- 効率と最適性の習得:ダイクストラのアル...
- 「カスタムGPT-4チャットボットの作り方」
- AI カリキュラムの日が今こそ必要な時に会う
- 「LangChainとGPT-3を使用して、ドキュメ...
- 打ち上げ!最初のMLプロジェクトを始める...
- 「アメリカの機械学習エンジニアの給与」
- スケールにおけるトランスフォーマーの最...
- 信頼性のある世代をチェーンオブバーニケ...
- ODSC APAC 2023はオンデマンドで視聴可能...
- 「AIがバービーの画像を作成し、人種差別...
- 「Artificial Narrow Intelligence(ANI)...

「データサイエンスの役割に関するGoogleのトップ50のインタビュー質問」
イントロダクション Googleでのキャリアを手に入れるためのコードを解読することは、多くのデータサイエンティスト志望者にとっての夢です。しかし、厳しいデータサイエンスの面接プロセスをクリアするにはどうすればよいのでしょうか?面接で成功するために、機械学習、統計学、プロダクトセンス、行動面をカバーするトップ50のGoogleのインタビュー質問の包括的なリストを作成しました。これらの質問に慣れて、回答の練習をしてください。これにより、面接官に印象を与え、Googleでのポジションを確保する可能性が高まります。 データサイエンスのGoogle面接プロセス Googleのデータサイエンティストの面接を通過することは、あなたのスキルと能力を評価するエキサイティングな旅です。このプロセスには、データサイエンス、問題解決、コーディング、統計学、コミュニケーションなど、さまざまなラウンドが含まれています。以下は、あなたが期待できる内容の概要です: ステージ 説明 応募の提出 Googleのキャリアウェブサイトを通じて、採用プロセスを開始するために応募と履歴書を提出します。 テクニカルな電話スクリーン 選考された場合、コーディングスキル、統計学の知識、データ分析の経験を評価するためにテクニカルな電話スクリーンが行われます。 オンサイト面接 成功した候補者は、通常、データサイエンティストや技術的な専門家との複数のラウンドからなるオンサイト面接に進みます。これらの面接では、データ分析、アルゴリズム、統計学、機械学習の概念など、より深く掘り下げたトピックについて話し合います。 コーディングと分析の課題 プログラミングスキルを評価するためにコーディングの課題に取り組み、データから洞察を抽出する能力を評価するために分析の課題に直面します。 システム設計と行動面の面接 一部の面接ではシステム設計に焦点を当て、スケーラブルなデータ処理や分析システムの設計を期待されることがあります。また、行動面の面接では、チームワーク、コミュニケーション、問題解決のアプローチを評価します。 採用委員会の審査 面接のフィードバックは採用委員会によって審査され、最終的な採用の決定が行われます。 Googleデータサイエンティストになる方法についての詳細な応募と面接のプロセスについては、当社の記事をご覧ください! データサイエンスの役職に関するトップ50のGoogleインタビューの質問と回答をまとめました。 データサイエンスのためのトップ50のGoogleインタビュー質問 機械学習、統計学、コーディングなどをカバーするトップ50のインタビュー質問の包括的なリストで、Googleのデータサイエンスの面接に備えてください。これらの質問をマスターし、あなたの専門知識を示して、Googleでのポジションを確保しましょう。 Googleの機械学習とAIに関するインタビューの質問 1.…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…
.jpg)
好奇心だけで十分なのか? 好奇心による探索からの新たな振る舞いの有用性について
私たちは、単に好奇心を使って環境を探索したり特定のタスクのボーナス報酬として使用するだけでは、この技術の全ポテンシャルを引き出すことはできず、有用なスキルを見逃してしまいます代わりに、私たちは好奇心に基づく学習中に現れる行動を保持することに焦点を当てることを提案しますこれらの自己発見された行動は、関連するタスクを解決するためのエージェントのレパートリーとして有用なスキルを持っていると考えています

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています
ロジスティック回帰における行列とベクトルの演算
任意の人工ニューラルネットワーク(ANN)アルゴリズムの基礎となる数学は理解するのが困難かもしれませんさらに、フィードフォワードや...
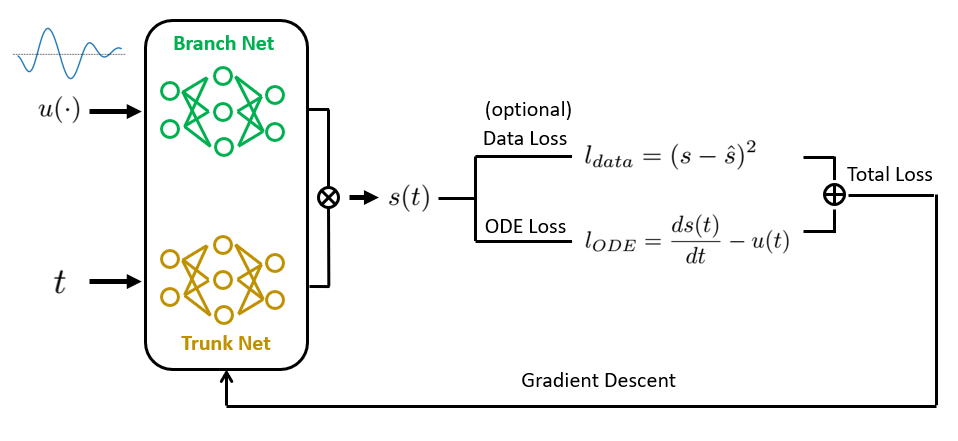
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...

機械学習を直感的に理解する
確かに、ChatGPTのようなモデルの実際の理論は認めるには非常に難しいですが、機械学習(ML)の根底にある直感は、まあ、直感的です!では、MLとは何でしょうか?しかし、これが...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.