Learn more about Search Results さまざまな要素 - Page 10

- You may be interested
- モバイルネットワーク上でのIoTの増加する...
- 『周期的な時間特徴のエンコード方法』
- 「3年間の経験から厳選された130の機械学...
- 「ベイズ推論を用いてデータセットとチャ...
- ベストAI画像生成器(2023年7月)
- 「LLaVAと一緒にあなたのビジョンチャット...
- 「仕事の未来を形作る:メタのアーピット...
- 2023年の機械学習研究におけるトップのデ...
- 「Javaプログラミングの未来:2023年に注...
- クラッチで登場:クラウドから最高のフレ...
- AI時代の運転:AIへの恐怖が命を奪う代償...
- メルティングポット:マルチエージェント...
- BentoML入門:統合AIアプリケーションフレ...
- Amazon SageMakerのマルチモデルエンドポ...
- 「アルゴリズムを使用して数千件の患者請...

事前学習済みの拡散モデルによる画像合成
「テキストから画像への拡散モデルは、自然言語の説明に基づいて写実的な画像を生成することで驚異的なパフォーマンスを達成していますオープンソースの事前学習済みモデルのリリースにより…」

ダッシュカムの映像が警察の展開地を明らかにする
科学者たちは、ニューヨーク市の警察が地域に展開する方法に関する示唆を、ディープラーニングモデルとライドシェアドライバーのダッシュカム画像のデータセットを用いて発見しました

「月に10000ドルを稼ぐために私が使用するAIツールとスキル—デタラメなことはありません」
そして、AIを活用して収益を最大化する方法を見つけてください

効果的にMLソリューションを比較する方法
「機械学習ソリューションを評価および比較する際には、おそらく最初に評価指標として予測力を使用することになるでしょう異なるモデルを1つの指標で比較するのは簡単であり、これが...」

CO2排出量と🤗ハブ:リーディング・ザ・チャージ
CO2排出量とは何であり、なぜ重要なのか? 気候変動は私たちが直面している最大の課題の一つであり、二酸化炭素(CO2)などの温室効果ガスの排出削減はこの問題に取り組む上で重要な役割を果たします。 機械学習モデルのトレーニングとデプロイメントには、コンピューティングインフラストラクチャのエネルギー使用によりCO2が排出されます。GPUからストレージまで、すべてが機能するためにエネルギーを必要とし、その過程でCO2を排出します。 写真:最近のTransformerモデルとそのCO2排出量 CO2の排出量は、実行時間、使用されるハードウェア、エネルギー源の炭素密度など、さまざまな要素に依存します。 以下に説明するツールを使用することで、自身の排出量を追跡および報告することができます(これは私たちのフィールド全体の透明性を向上させるために重要です!)また、モデルを選択する際にはそのCO2排出量に基づいて選択することができます。 Transformersを使用して自動的に自分のCO2排出量を計算する方法 始める前に、システムに最新バージョンのhuggingface_hubライブラリがインストールされていない場合は、以下を実行してください: pip install huggingface_hub -U Hugging Face Hubを使用して低炭素排出モデルを見つける方法 モデルがハブにアップロードされたことを考慮して、エコ意識を持ってハブ上のモデルを検索する方法はありますか?それには、huggingface_hubライブラリに新しい特別なパラメータemissions_thresholdがあります。最小または最大のグラム数を指定するだけで、その範囲内に含まれるすべてのモデルが検索されます。 たとえば、最大100グラムで作成されたすべてのモデルを検索できます: from huggingface_hub import HfApi api = HfApi()…

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...
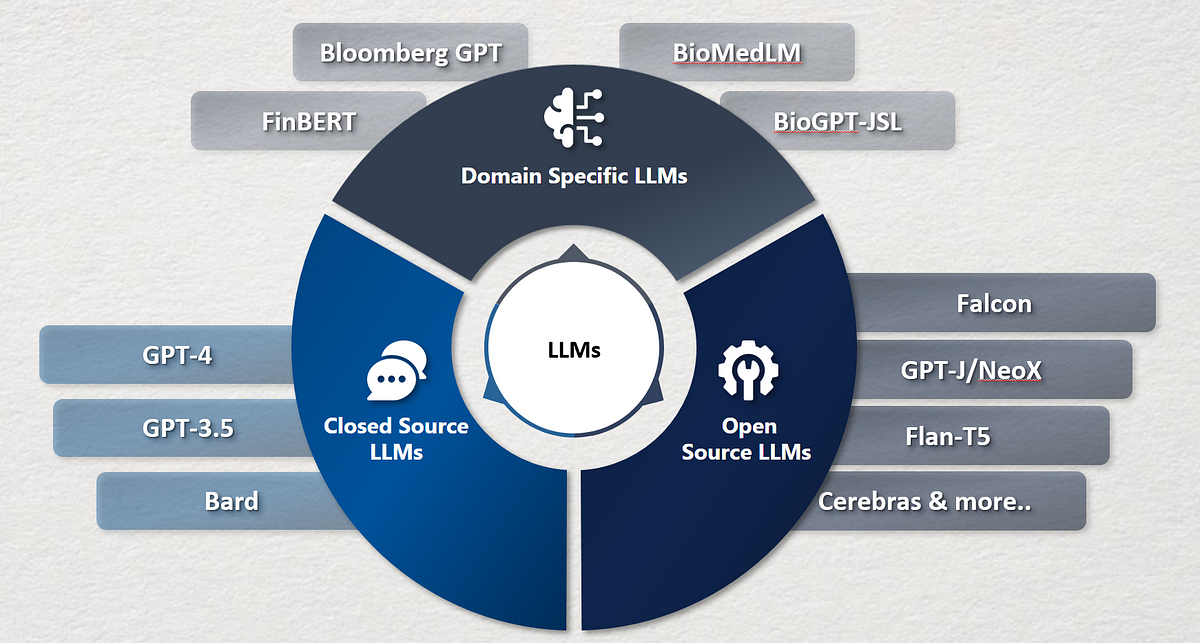
企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
最近の数年間で、言語モデルは大きな注目を集め、自然言語処理、コンテンツ生成、仮想アシスタントなど、さまざまな分野を革新しました最も注目されているのは、

Explainable AI(説明可能なAI)とInterpretable AI(解釈可能なAI)の理解
最近の機械学習(ML)の技術革新の結果、MLモデルは人間の労働を不要にするために、さまざまな分野で使用されています。これらの分野は、著者や詩人が執筆スタイルを洗練させるのを手助けするだけでなく、タンパク質構造の予測などのように複雑なものもあります。さらに、MLモデルが医療診断、クレジットカード詐欺検出などの重要な産業で人気を集めるにつれて、エラーに対する許容範囲は非常に低くなります。そのため、人間がこれらのアルゴリズムをより深く理解する必要があります。なぜなら、学術界がより堅牢なモデルを設計し、バイアスやその他の懸念事項に関する現行モデルの欠陥を修復するためには、MLモデルが予測を行う方法のより大きな知識を得ることが重要です。 ここで、解釈可能な(IAI)および説明可能な(XAI)人工知能技術が重要になり、その違いを理解する必要性がより明確になります。これらの2つの違いは、学者にさえ常に明確ではなく、解釈性と説明性という用語は、MLアプローチを指す際に時々同義的に使用されます。MLフィールドでの人気が高まるにつれて、IAIとXAIモデルの区別をすることは重要です。これにより、組織が使用ケースに最適な戦略を選択するための支援が可能になります。 要するに、解釈可能なAIモデルは、モデルの要約とパラメータを見るだけで人間が簡単に理解できるものです。つまり、IAIモデルは独自の説明を提供します。一方、説明可能なAIモデルは、人間が追加の方法なしでは理解することができない非常に複雑な深層学習モデルです。これが、説明可能なAIモデルがなぜ特定の決定が下されたかを明確に示すことができるが、その決定に至るまでの手順はわからない理由です。この記事の残りでは、解釈性と説明性の概念についてより詳しく説明し、例を使って理解します。 1. 解釈可能な機械学習 私たちは、何かの意味を理解することが可能であれば、それは解釈可能であると主張します。つまり、その原因と結果を明確に特定することができます。例えば、誰かが夕食後にチョコレートをたくさん食べると、いつも眠れなくなります。このような状況は解釈することができます。MLの領域では、モデルのパラメータに基づいて人々が自分自身で理解できる場合、モデルは解釈可能と言われます。解釈可能なAIモデルでは、人間はモデルが特定の解を導き出す方法を簡単に理解することができますが、その結果に至るための基準が合理的であるかどうかはわかりません。意思決定木や線形回帰は、解釈可能なモデルの例です。以下の例を使って解釈性をより良く説明しましょう。 貸付申請の承認を決定するために訓練された決定木モデルを使用する銀行を考えてみましょう。申請者の年齢、月収、未払いの他のローンなどが決定に考慮されます。特定の決定がなされた理由を理解するために、木のノードを簡単にたどることができ、決定基準に基づいて最終結果がどうなったかを理解することができます。例えば、決定基準が、学生ではない人の月収が$3000未満の場合、ローン申請は承認されないと指定することができます。しかし、これらのモデルを使用して決定基準を選択する背後の理論は理解できません。例えば、このシナリオでは、非学生の申請者に対して$3000以上の最低収入要件が適用される理由は、モデルが説明できません。 モデルが予測を生成する方法を理解するためには、重み、特徴などを含むさまざまな要素を解釈することが必要です。ただし、これはモデルがかなりシンプルな場合にのみ可能です。線形回帰モデルや決定木は、パラメータの数が少ないです。モデルが複雑になるにつれて、この方法では理解することができなくなります。 2. 説明可能な機械学習 説明可能なAIモデルは、内部の仕組みが人間にとって理解することができないほど複雑なものです。モデルの特徴を入力とし、最終的に生成される予測を出力とするブラックボックスモデルも、MLアルゴリズムの別名です。人間は、これらの「ブラックボックス」システムを理解するために追加の手法が必要です。そのようなモデルの例としては、多数の決定木からなるランダムフォレスト分類器があります。このモデルでは、最終予測を決定する際に各ツリーの予測が考慮されます。LogoNetなどのニューラルネットワークベースのモデルを考慮すると、この複雑さはさらに増します。このようなモデルの複雑さが増すにつれて、モデルの重みを見るだけではモデルを理解することは不可能です。 先述のように、人間は洗練されたアルゴリズムがどのように予測を生成するかを理解するために追加の手法が必要です。研究者は、入力データとモデルが生成する予測との間の関連性を見つけるためにさまざまな手法を利用しており、これによってMLモデルの振る舞いを理解するのに役立ちます。このようなモデルに依存しない手法(モデルの種類に依存しない手法)には、部分依存プロット、SHapley加法的説明(SHAP)依存プロット、代替モデルなどが含まれます。さらに、異なる特徴の重要性を強調するいくつかのアプローチも採用されています。これらの戦略は、各属性がターゲット変数を予測するためにどのように利用されるかを評価します。スコアが高いほど、その特徴はモデルにとってより重要であり、予測に大きな影響を与えます。 しかし、まだ残る疑問は、なぜMLモデルの解釈性と説明可能性を区別する必要があるのかということです。上記の議論から明らかなように、いくつかのモデルは他のモデルよりも解釈しやすいです。単純に言えば、あるモデルが他のモデルよりも予測の仕組みが人間に理解しやすい場合、そのモデルはより解釈しやすいと言えます。また、一般的には、ニューラルネットワークを含むより複雑なモデルは、より解釈しやすいですが、精度が低くなる傾向があります。したがって、高い解釈性は通常、低い精度の代償となります。例えば、画像認識にロジスティック回帰を使用すると、劣った結果になります。一方、モデルの説明可能性は、高いパフォーマンスを達成したいがモデルの振る舞いを理解する必要がある場合により重要な役割を果たします。 したがって、企業は新しいMLプロジェクトを開始する前に、解釈性が必要かどうかを考慮する必要があります。データセットが大きく、データが画像やテキストの形式である場合、ニューラルネットワークは高いパフォーマンスで顧客の目標を達成することができます。このような場合、パフォーマンスを最大化するために複雑な手法が必要な場合、データサイエンティストは解釈性よりもモデルの説明可能性に重点を置きます。このため、モデルの説明可能性と解釈性の違いを理解し、どちらを優先するかを知ることが重要です。

Metaphy LabsのAIエバンジェリストに会いましょう
紹介 常に変化するテックの風景の中で、魅力的な現象が浮かび上がってきました。それがメタバースです。この領域をリードするのは、ビジョナリーな共同創業者であるヴァルン・シャルマ氏です。彼のAIへの情熱が、仮想領域を再構築するための旅を推進しています。ヴァルンに会ってください。彼はメタバースとAIの力を利用して、非凡な人間の相互作用、創造性、起業家精神を実現しています。彼のビジョンは物理的な制約を超え、没入型の体験を構築し、デジタルのフロンティアを開拓することを推進しています。 会話を始めましょう! AV: メタフィラボの共同創業者兼最高メタバースオフィサーとしての道のりについて教えていただけますか?何があなたをこの道に進ませたのですか? ヴァルン氏 : メタフィラボの共同創業者兼最高メタバースオフィサーとしての私の道のりは、挑戦的で充実した経験でした。私は常に技術への情熱を持ち、それが世界を変える可能性を感じていました。アクセス可能な没入型の体験や仮想世界を作り出すアイデアは、私を魅了し、この道で私をインスパイアし続けています。 さらに、人間を特別な存在にしているのは、言葉を超えてつながる能力です。しかし、技術は常に感情的なつながりの不足と結び付けられてきました。私たちはそれを変えたかったのです。私たちの独自の技術を通じて、感情的に優れた本当にパーソナルな体験を作り出しています。 AV: あなたの仕事で最も困難な側面は何ですか?それらをどのように克服していますか? ヴァルン氏 : 革新的なディープテック企業として、技術の最先端に立ち、イノベーションの先頭に立つことは、私が情熱をもって受け入れるスリリングな挑戦です。この新興のフィールドでは、認知度を高め、採用を促進することがハードルとなることもあります。しかし、クライアントに卓越した価値を提供することで、私たちはどんな障害も乗り越えることができます。 データサイエンスを用いてビジネス問題を解決する AV: 過去に取り組んだ特に興味深いプロジェクトを共有していただけますか?データサイエンスをどのように活用してビジネス問題を解決しましたか? ヴァルン氏 : データサイエンスは常に革新と私のテックの旅の核となってきました。私はデータサイエンティストでありAIエバンジェリストとしてのキャリアをスタートしました。幸運なことに、複数の可能性を秘めた人生を変えるプロジェクトに取り組む機会を得ました。 過去のプロジェクトでは、カスタムの機械学習アルゴリズムを活用してユーザーの行動を予測し、ソーシャルメディアプラットフォームのユーザーエクスペリエンスを向上させました。ユーザーデータと行動パターンを分析し、改善の余地がある領域を特定し、ターゲットを絞ったソリューションを実装しました。これにより、ユーザーのエンゲージメント、リテンション、収益の増加が大幅に実現しました。 AV: 仕事以外での趣味や興味がありますか?個人的な時間と仕事をどのようにバランスさせていますか? ヴァルン氏…

大規模な言語モデルにおけるコンテキストに基づく学習アプローチ
言語モデリング(LM)は、単語のシーケンスの生成的な尤度をモデル化することを目指し、将来の(または欠損している)トークンの確率を予測します言語モデルは自然言語処理の世界を革新しました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.