Learn more about Search Results OPT - Page 109

- You may be interested
- 「なぜデータパイプラインには閉ループフ...
- 高パフォーマンスなリアルタイムデータモ...
- オープンAIのファンクションコーリング入門
- Pixis AIとは、コードを書かずにAIソリュ...
- 「Amazon SageMaker Feature Storeを使用...
- MIT-Pillar AI Collectiveが初めてのシー...
- Pythonプロジェクトのセットアップ:パートV
- 「2023年に試してみるべき20の中間旅行の...
- デジタルアイデンティティを保護する方法
- 「ROUGEメトリクス:大規模言語モデルにお...
- ディープラーニングを使用してファンタジ...
- 投影ヘッドを使用した自己監督学習
- 「信じられないほどの新しい中間補間機能...
- 「セルフサービスデータ分析はニーズの階...
- 施設分散問題:混合整数計画モデル

データアナリストからデータサイエンティストへのキャリアチェンジの方法は?
人々は常にデータを扱っており、データアナリストは専門知識を身につけた後、よりチャレンジングな役割を求めています。データサイエンティストは、最も収益性の高いキャリアオプションの1つとされています。スキルセットの拡大が必要ですが、いくつかの教育プラットフォームが変化に有益な洞察を提供しています。多くのデータアナリストが成功して転身していますし、あなたも次の転身者になることができます! 以下のステップは、データサイエンティストとしてのキャリアをスタートさせる際に、企業の成長に貢献し、専門知識を増やすのに役立ちます: スキルギャップの評価 データサイエンティストの役割に必要な基本的なスキルと知識 データサイエンティストはデータを実験する必要があるため、新しいアイデアや研究を開発するマインドセットが重要です。過去の実験のミスを分析する能力も同様に重要です。これに加えて、以下のような技術スキルと知識が求められます: 技術スキル: PythonやRなどのプログラミング言語やデータ言語 線形回帰やロジスティック回帰、ランダムフォレスト、決定木、SVM、KNNなどの機械学習アルゴリズム SAP HANA、MySQL、Microsoft SQL Server、Oracle Databaseなどのリレーショナルデータベース Natural Language Processing(NLP)、Optical Character Recognition(OCR)、Neural networks、computer vision、deep learningなどの特殊なスキル RShiny、ggplot、Plotly、Matplotlitなどのデータ可視化能力 Hadoop、MapReduce、Sparkなどの分散コンピューティング 分析スキル:…
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します
GEKKOを使用して、世界を確定的な方法でモデリングする
私たちの世界がますますデジタル化される中で、データ収集は急速に拡大していますこのデータによって、私たちはより正確なモデルを作成し、問題を解決し最適化するための手助けをしてきました...

エンタープライズAIとは何ですか?
エンタープライズAIの紹介 時間は重要であり、自動化が答えです。退屈で単調なタスク、人間によるミス、競争の混乱、そして最終的には曖昧な意思決定の苦闘の中で、エンタープライズAIは企業が機械と協力してより効率的に働くことを可能にしています。さもなければ、Netflixでお気に入りの番組を見つけたり、Amazonで必要なアクセサリーを見つけて購入する方法はどうやって見つけるのでしょうか?自動車のWaymoからマーケティングでの迅速な分析まで、人工知能はすでに私たちに十分な理由を提供しています。しかし、それが組織をどのように助けているのでしょうか?また、組織はそれをどのように使用しているのでしょうか?答えはエンタープライズAIです。 こんにちは! Analytics Vidhya Blogの熱心な読者として、私たちはあなたに素晴らしい機会を提供したいと思います。データサイエンスとAIの愛好家の皆さん、ぜひ私たちと一緒に非常に期待されているDataHack Summit 2023に参加してください。8月2日から5日まで、バンガロールの名門NIMHANSコンベンションセンターで行われます。このイベントは、実践的な学習、貴重な業界の洞察、そして無敵のネットワーキングの機会で満たされた、爆発的なものになるでしょう。これらのトピックに興味があり、これらのコンセプトが現実になることをもっと学びたい場合は、こちらのDataHack Summit 2023の情報をチェックしてください。 エンタープライズAIの定義 エンタープライズAIは、大規模な組織内で人工知能技術と技法を応用して、さまざまな機能を改善することを指します。これらの機能には、データの収集と分析、自動化、顧客サービス、リスク管理などが含まれます。エンタープライズAIは、AIアルゴリズム、機械学習(ML)、自然言語処理(NLP)、コンピュータビジョンなどのツールを使用して、複雑なビジネスの問題を解決し、プロセスを自動化し、大量のデータから洞察を得ることを目指しています。 エンタープライズAIは、サプライチェーン管理、ファイナンス、マーケティング、顧客サービス、人事、サイバーセキュリティなど、さまざまな領域に実装することができます。これにより、組織はデータに基づいた意思決定を行い、効率を向上させ、ワークフローを最適化し、顧客体験を向上させ、市場で競争力を持つことができます。 出典:Publicis Sapient エンタープライズAIの主な特徴 エンタープライズAIは、データ分析から自動化まで、組織のさまざまな側面に貢献します。それは異なる技術や技法、そして方法の産物であり、それは各業界やビジネスによって異なるかもしれません。以下にその仕組みを示します。 エンタープライズアプリケーション向けのAI技術の組み合わせ エンタープライズAI企業は、機械学習、自然言語処理、エッジコンピューティング、ディープラーニング、コンピュータビジョンなどの技術の組み合わせを活用することができます。これらの技術は、予測分析、画像認識などのタスクを通じて、ビジネスを支援するための強力な機能を提供します。Netflixのパーソナライズされた推奨機能は、ディープラーニングなどの技術を使用した、その一例です。 組織のニーズに合わせてカスタマイズされ設計された エンタープライズAIは、さまざまな技術の組み合わせです。組織がシステム内でどのようにアプローチするか、どの技法を採用するかは、ビジネスの要件によるものです。なぜなら、サプライチェーン管理に適した方法が、eコマースの場合に必要なわけではないからです。 たとえば、ヘルスケアのエンタープライズAI企業は、画像解析、患者モニタリングなどの技法を採用して、医療業務の効率を向上させています。エネルギー業界では、予測保守、再生可能エネルギーの統合などの技術と技法を使用して、エネルギーの発電と消費を最適化しています。その活用方法の違いにより、組織は人工知能のさまざまな分野を航海しています。 エンタープライズAIの利点と応用 以下はエンタープライズAIの主な利点です:…

テキストブック品質の合成データを使用して言語モデルをトレーニングする
マイクロソフトリサーチは、データの役割についての現在進行中の議論に新たな燃料を加える論文を発表しました具体的には、データの品質と合成データの役割に触れています
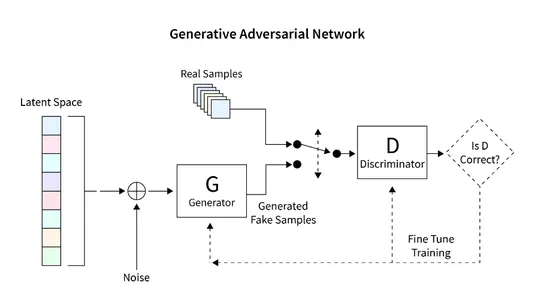
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…
Hugging Face Datasets での作業
AIプラットフォームであるHugging Faceは、最先端のオープンソースの機械学習モデルの構築、トレーニング、展開を行いますこれらのトレーニング済みモデルをホスティングするだけでなく、Hugging Faceはデータセットもホスティングしています...

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…

2023年にフォローすべきトップ10のAIインフルエンサー
イントロダクション 先端技術と驚くべき可能性によって駆動される世界で、AIの絶えず進化する領域に遅れをとらないことは、スリリングで不可欠なものです。2023年という有望な年に足を踏み入れると、最も影響力のあるビジョナリーなAIの草分けたちの心の中を巡るエキサイティングな旅に出る時がきました。準備を整えて、2023年にフォローすべきAIのトップ10インフルエンサーと出会う準備をしましょう。彼らはAIの景色を形作り、可能性の限界を押し広げている前衛的な思想家や創造者です。 画期的な研究から魅惑的な洞察まで、これらのAIインフルエンサーは、人工知能のエキサイティングな世界を照らす指針となる存在です。仮想のノートパッドを手に取り、シートベルトを締めてください。なぜなら、私たちは時代を超えてAIの未来を再定義するビジョンを明らかにするための、最も優れたAIの脳の探求に乗り出すからです。2023年以降のAIの未来を再定義するビジョンを明らかにするための、最も優れたAIの脳の探求に乗り出すからです。 しかし、このトップ10リストに飛び込む前に、私たちはあなたに素晴らしい機会をご紹介したいと思います。データサイエンスとAI愛好家の皆さんに、大いに期待されるDataHack Summit 2023への独占的な招待状をお届けします。8月2日から5日まで、バンガロールの名門NIMHANSコンベンションセンターで開催されます。このイベントは、実践的な学習、貴重な業界の洞察、抜群のネットワーキングの機会が満載で、楽しい時間を過ごせること間違いありません。DataHack Summit 2023の詳細については、こちらでご確認ください。データ革命に参加してください。 AIインフルエンサーの定義 AIインフルエンサーとは、その専門知識、思想リーダーシップ、貢献を通じて、人工知能(AI)の分野で認識と影響力を得た個人のことです。彼らはAIコミュニティと積極的に関わり、ソーシャルメディアプラットフォームを活用しています。 AIインフルエンサーは単一のソーシャルメディアプラットフォームに限定されるものではありません。Instagramに加えて、彼らはTwitter、YouTube、LinkedIn、ブログなど、さまざまなプラットフォームで強力な存在感を持っており、AIに関連する洞察、研究結果、業界のトレンド、思考を刺激するコンテンツを共有しています。これらのインフルエンサーは多くのフォロワーを持ち、自身の観衆と関わりながら、ディスカッションを促進し、ガイダンスを提供し、AI分野での革新を促し、インスピレーションを与えています。ハッカソンの開催からライブコーディングセッションの実施まで、これらのインフルエンサーは自身の専門知識を披露し、大きな人気と視聴数を獲得しています。彼らのインタラクティブなセッションとイベントは、価値ある学習の機会を提供し、AIのスキルを向上させ、最新の進歩に遅れずにいることを奨励しています。 人工知能の分野におけるAIインフルエンサーの重要性 人工知能の分野におけるAIインフルエンサーの重要性は過小評価できません。彼らはいくつかの側面で重要な役割を果たしています: 知識の普及 AIインフルエンサーは、広範な観衆に対して知識、洞察、業界の最新情報を普及させます。彼らは複雑なAIの概念を簡単に説明し、AIの専門家志望者、愛好家、一般の人々にもアクセスしやすくします。 トレンドセッターや意見リーダー AIインフルエンサーは、最新のAIのトレンド、ブレークスルー、技術の最前線に常に接しています。彼らの意見と推奨事項は重要であり、AIの研究、応用、業界の実践に影響を与えることができます。 ネットワーキングとコラボレーション AIインフルエンサーは、AIコミュニティ内でのネットワーキングとコラボレーションの場を提供します。彼らはプロフェッショナル、研究者、組織をつなぎ、革新を促進し、AI技術の開発を推進する協力的な環境を育成します。 フォローすべきトップAIインフルエンサー 1. Andrew Ng Twitterで210万人以上のフォロワーを持つAndrew…
トップ3のデータアーキテクチャのトレンド(およびLLMsがそれらに与える影響)
データアーキテクチャの次の時代への取り組み:トップ3のトレンドとLLMの影響力を明らかにする
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.