Learn more about Search Results OPT - Page 104

- You may be interested
- 「PowerBIでのデータ操作のためのPower Qu...
- 「Andrej Karpathy LLM Paper Reading Lis...
- 2023年のトップ10 AI QRコードジェネレーター
- 「データサイエンスを使って、トップのTwi...
- 「生成型AIのGPT-3.5からGPT-4への移行の...
- 変形ロボットが昆虫のように握り、登り、...
- ルシーンの内部 – 整数のエンコーデ...
- 「ChatGPTコードインタプリタを使用したデ...
- 『ScaleCrafterを知る:事前学習済みの拡...
- 「当社の独占的なマークダウンチートシー...
- なぜシリコンバレーは人工知能の拠点とな...
- あちこち行って… RAPIDSの物語
- 「Scikit-LLMを使用したゼロショットテキ...
- ChatGPTを使用したメール自動化の方法
- 科学者たちは、AIと迅速な応答EEGを用いて...

単一のGPUでChatgptのようなチャットボットをROCmで実行する
はじめに ChatGPTは、OpenAIの画期的な言語モデルであり、人工知能の領域で影響力のある存在となり、様々なセクターでAIアプリケーションの多様な活用を可能にしています。その驚異的な人間のようなテキストの理解力と生成力により、ChatGPTは顧客サポートから創造的な文章作成まで、さまざまな産業を変革し、貴重な研究ツールとしても使われています。 OPT、LLAMA、Alpaca、Vicunaなど、大規模な言語モデルのオープンソース化にはさまざまな取り組みが行われていますが、その中でもVicunaはAMD GPU上でROCmを使用してVicuna 13Bモデルを実行する方法を説明します。 Vicunaとは何ですか? Vicunaは、UCバークレー、CMU、スタンフォード、UCサンディエゴのチームによって開発された13兆パラメータを持つオープンソースのチャットボットです。Vicunaは、LLAMAベースモデルを使用して、ShareGPT.comからの約70,000件のユーザー共有会話を収集し、公開APIを介してファインチューニングしました。GPT-4を参照とした初期の評価では、Vicuna-13BはOpenAI ChatGPTと比較して90%以上の品質を実現しています。 それはわずか数週間前の4月11日にGithubでリリースされました。Vicunaのデータセット、トレーニングコード、評価メトリック、トレーニングコストはすべて公開されており、一般のユーザーにとって費用対効果の高いソリューションとなっています。 Vicunaの詳細については、https://vicuna.lmsys.org をご覧ください。 なぜ量子化されたGPTモデルが必要なのですか? Vicuna-13Bモデルをfp16で実行するには、約28GBのGPU RAMが必要です。メモリの使用量をさらに減らすためには、最適化技術が必要です。最近発表された研究論文「GPTQ」では、低ビット精度を持つGPTモデルの正確な事後トレーニング量子化が提案されています。以下の図に示すように、パラメータが10Bを超えるモデルの場合、4ビットまたは3ビットのGPTQはfp16と同等の精度を実現することができます。 さらに、これらのモデルの大きなパラメータは、GPTトークン生成が計算(TFLOPsまたはTOPs)そのものよりもメモリ帯域幅(GB/s)によって制約されるため、GPTのレイテンシに深刻な影響を与えます。そのため、メモリに制約のある状況下では、量子化モデルはトークン生成のレイテンシを低下させません。GPTQの量子化の論文とGitHubリポジトリを参照してください。 この技術を活用することで、Hugging Faceからいくつかの4ビット量子化されたVicunaモデルが利用可能です。 ROCmを使用してAMD GPUでVicuna 13Bモデルを実行する AMD GPUでVicuna 13Bモデルを実行するには、AMD GPUの高速化のためのオープンソースソフトウェアプラットフォームであるROCm(Radeon…

より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
大規模言語モデル(LLM)は、機械学習の世界を席巻しています。Transformerアーキテクチャのおかげで、LLMはテキスト、画像、ビデオ、オーディオなどの大量の非構造化データから学習する驚異的な能力を持っています。テキスト分類のような抽出型のタスクや、テキスト要約、テキストから画像生成などの生成型のタスクでも非常に優れたパフォーマンスを発揮します。 その名前からもわかるように、LLMは一般的に100億パラメータを超える大規模なモデルです。BLOOMモデルのように1000億パラメータ以上のものもあります。LLMは、検索や対話型アプリケーションなどの低遅延のユースケースで十分に高速な予測を行うために、高性能なGPUに典型的に見られる大量の計算能力を必要とします。残念ながら、多くの組織にとっては関連するコストが高く、最先端のLLMをアプリケーションに使用することが困難になります。 この記事では、Intel CPU上で効率的に実行するために、LLMのサイズと推論レイテンシを減らす最適化技術について説明します。 量子化の基礎 通常、LLMは16ビットの浮動小数点パラメータ(FP16/BF16)でトレーニングされます。したがって、単一の重みまたはアクティベーション値の値を保存するためには2バイトのメモリが必要です。さらに、浮動小数点の演算は整数の演算よりも複雑で遅く、追加の計算能力が必要です。 量子化は、モデルパラメータが取ることができるユニークな値の範囲を縮小することで、両方の問題を解決するモデルの圧縮技術です。たとえば、モデルを8ビット整数(INT8)のような低精度に量子化して、モデルを縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。 要するに、量子化はモデルパラメータをより小さな値範囲に再スケーリングします。成功すると、モデルのサイズが少なくとも2倍に縮小され、モデルの精度には影響しません。 量子化は、通常、トレーニング中に適用することができます。これを量子化対応トレーニング(QAT)と呼びますが、一般的に最良の結果が得られます。既存のモデルを量子化する場合は、非常に少ない計算能力を必要とする高速なテクニックであるポストトレーニング量子化(PTQ)を適用することもできます。 さまざまな量子化ツールが利用可能です。たとえば、PyTorchには量子化の組み込みサポートがあります。また、QATおよびPTQのための開発者向けのAPIを備えたHugging Face Optimum Intelライブラリを使用することもできます。 LLMの量子化 最近の研究[1][2]によると、現在の量子化技術はLLMとはうまく機能しません。特に、LLMはすべてのレイヤーとトークンで特定のアクティベーションチャネルに大きな値の外れ値を示します。以下はOPT-13Bモデルの例です。すべてのトークンで、アクティベーションの1つのチャネルが他のすべてのチャネルよりもはるかに大きな値を持っていることがわかります。この現象はモデルのすべてのTransformerレイヤーで見られます。 *出典: SmoothQuant* 現在の最良の量子化技術は、トークン単位でアクティベーションを量子化し、切り捨てられた外れ値または低いマグニチュードのアクティベーションを引き起こします。いずれの解決策もモデルの品質に大きな影響を与えます。さらに、量子化対応トレーニングには追加のモデルトレーニングが必要であり、計算リソースとデータの不足のため、ほとんどの場合には実用的ではありません。 SmoothQuant[3][4]は、この問題を解決する新しい量子化技術です。それは重みとアクティベーションに共同の数学的変換を適用し、アクティベーションの外れ値と非外れ値の比率を減らすことで、Transformerのレイヤーを「量子化に適した」状態にします。これにより、モデルの品質に影響を与えずに8ビットの量子化が可能となります。その結果、SmoothQuantはIntel CPUプラットフォーム上で優れたパフォーマンスを発揮する、より小さく、高速なモデルを生成します。 *出典: SmoothQuant* それでは、SmoothQuantを人気のあるLLMに適用した場合の動作を見てみましょう。 SmoothQuantを使用したLLMの量子化…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…
ビジネス戦略において機械学習を使用する時と使用しない時の選択
それは明らかな質問ではありません初心者のデータサイエンティストにとっては、すぐに機械学習モデルを推進することは間違いです実際には、よりシンプルなルールベースのソリューションの方が効率的で実装が容易です...

Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
言語モデル、大規模な言語モデル、または基盤モデル、トランスフォーマーは、事前学習、微調整、および推論において大量の計算を必要とします。Hugging Faceは、開発者や組織が最大のパフォーマンスを得るために、ハードウェア企業と協力して、各チップのアクセラレーション機能を活用してきました。 本日、私たちはAMDが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。私たちのCEOであるClement Delangueが、サンフランシスコで行われたAMDのデータセンターおよびAIテクノロジープレミアで基調講演を行い、このエキサイティングな新しい協力関係を発表しました。 AMDとHugging Faceは、AMDのCPUおよびGPU上で最先端のトランスフォーマーパフォーマンスを提供するために協力しています。このパートナーシップは、Hugging Faceコミュニティ全体にとって非常に良いニュースであり、近々、最新のAMDプラットフォームをトレーニングおよび推論に活用することができるようになります。 長年にわたり、ディープラーニングハードウェアの選択肢は限られており、価格と供給は懸念事項となっています。この新しいパートナーシップは、競争に対抗するだけでなく、市場の動向を緩和するのに役立ちます。さらに、新しいコストパフォーマンスの基準を設定することも期待されます。 サポートされるハードウェアプラットフォーム GPU側では、AMDとHugging Faceはまず、エンタープライズグレードのInstinct MI2xxおよびMI3xxファミリー、次に、カスタマーグレードのRadeon Navi3xファミリーで協力します。AMDの最近のテストでは、MI250が直接競合他社よりもBERT-Largeを1.2倍、GPT2-Largeを1.4倍高速にトレーニングすることを報告しています。 CPU側では、両社はクライアントRyzenおよびサーバーEPYC CPUの推論の最適化に取り組みます。いくつかの以前の投稿で議論したように、CPUはトランスフォーマーの推論において優れたオプションになり得ます。特に、量子化などのモデル圧縮技術と組み合わせた場合です。 最後に、この協力関係には、低い電力要件で驚異的なパフォーマンスを発揮するAlveo V70 AIアクセラレータも含まれます。 サポートされるモデルアーキテクチャとフレームワーク 私たちは、自然言語処理、コンピュータビジョン、音声などの最先端のトランスフォーマーアーキテクチャ(BERT、DistilBERT、ROBERTA、Vision Transformer、CLIP、Wav2Vec2など)をサポートする予定です。もちろん、生成型AIモデル(GPT2、GPT-NeoX、T5、OPT、LLaMAなど)、私たち自身のBLOOMおよびStarCoderモデルも利用可能です。最後に、ResNetやResNextのようなより伝統的なコンピュータビジョンモデル、そして深層学習の推薦モデルにも初めて対応します。 これらのモデルをPyTorch、TensorFlow、およびONNX Runtime向けに上記のプラットフォームでテストおよび検証するために最善を尽くします。すべてのモデルが、すべてのフレームワークまたはすべてのハードウェアプラットフォームでトレーニングおよび推論に利用可能であるわけではないことを覚えておいてください。 今後の展望…

iPhone、iPad、およびMacでのCore MLによる高速で安定した拡散
先週、WWDC’23(Apple Worldwide Developers Conference)が開催されました。キーノート中のVision Proの発表に焦点が当てられましたが、それだけではありません。毎年のように、WWDC週はAppleのオペレーティングシステムとフレームワークの新機能について深く掘り下げる200以上の技術セッションが詰まっています。今年は特に、圧縮と最適化のためのCore MLの変更に興奮しています。これらの変更により、Stable Diffusionなどのモデルの実行が高速化され、メモリ使用量も少なくなります!一例として、12月にiPhone 13で実行したテストと現在の6ビットパレット化を使用した速度の比較を考えてみましょう: 12月のiPhoneでのStable Diffusionと現在の6ビットパレット化 目次 新しいCore MLの最適化 量子化および最適化されたStable Diffusionモデルの使用 カスタムモデルの変換と最適化 6ビット未満の使用 結論 新しいCore MLの最適化 Core MLは、Appleのデバイス内で効率的に機械学習モデルを実行するための成熟したフレームワークであり、CPU、GPU、およびMLタスクに特化したニューラルエンジンなど、Appleデバイスのすべてのコンピューティングハードウェアを活用します。デバイス上での実行は、Stable Diffusionや大規模な言語モデルの人気によって引き起こされた非常に興味深い時期を迎えています。多くの人々がこれらのモデルをさまざまな理由でハードウェア上で実行したいと考えており、利便性やプライバシー、APIのコスト削減などがその理由です。自然に、多くの開発者がデバイス上でこれらのモデルを効率的に実行する方法を探求し、新しいアプリやユースケースを作成しています。この目標を達成するためのCore MLの改善は、コミュニティにとって大きなニュースです!…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…
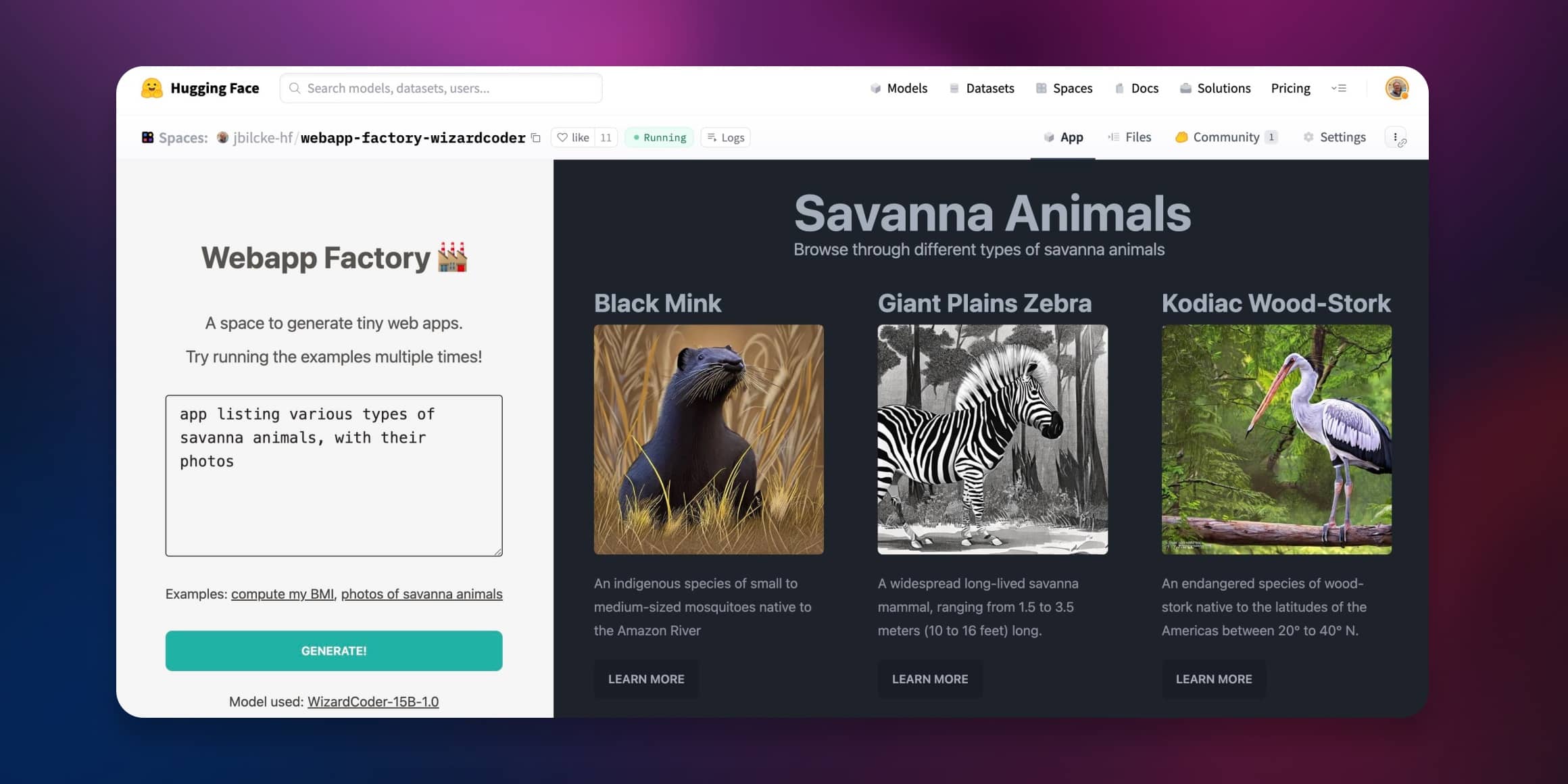
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.