Learn more about Search Results OPT - Page 103

- You may be interested
- 「2023年にリモートジョブを見つけるため...
- 「InstagramがAIによって生成されたコンテ...
- 「Verbaに会ってください:自分自身のRAG...
- SSDを使用したリアルタイム物体検出:シン...
- Taplio LinkedInの成長に最適なAIツール
- CleanLabを使用してデータセットのラベル...
- ホームブリューや仮想マシンなしでMacBook...
- ショッピファイの従業員がAIによるレイオ...
- OpenAIは、ChatGPTで「Bingで閲覧する」機...
- この人工知能ベースのタンパク質言語モデ...
- 『RAG データとの会話の仕方』
- AIを活用した言語学習アプリの構築:2つの...
- 「GPUを使用してAmazon SageMakerのマルチ...
- ソースコード付きのトップ14のデータマイ...
- 「特殊ガラスの構造と開発における特定の...

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

UnityゲームをSpaceにホストする方法
UnityゲームをHugging Face Spaceでホストできることを知っていますか?いいえ?そうです、できます! Hugging Face Spacesは、デモを構築、ホスト、共有するための簡単な方法です。通常は機械学習のデモに使用されますが、プレイ可能なUnityゲームもホストできます。以下にいくつかの例を示します。 Huggy Farming Game Unity APIデモ 次に、Spaceで独自のUnityゲームをホストする方法を説明します。 ステップ1:静的HTMLテンプレートを使用してSpaceを作成する まず、Hugging Face Spacesに移動してスペースを作成します。 “Static HTML”テンプレートを選択し、スペースに名前を付けて作成します。 ステップ2:Gitを使用してスペースをクローンする Gitを使用して、新しく作成したスペースをローカルマシンにクローンします。ターミナルまたはコマンドプロンプトで次のコマンドを実行することでこれを行うことができます。 git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ステップ3:Unityプロジェクトを開く…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…
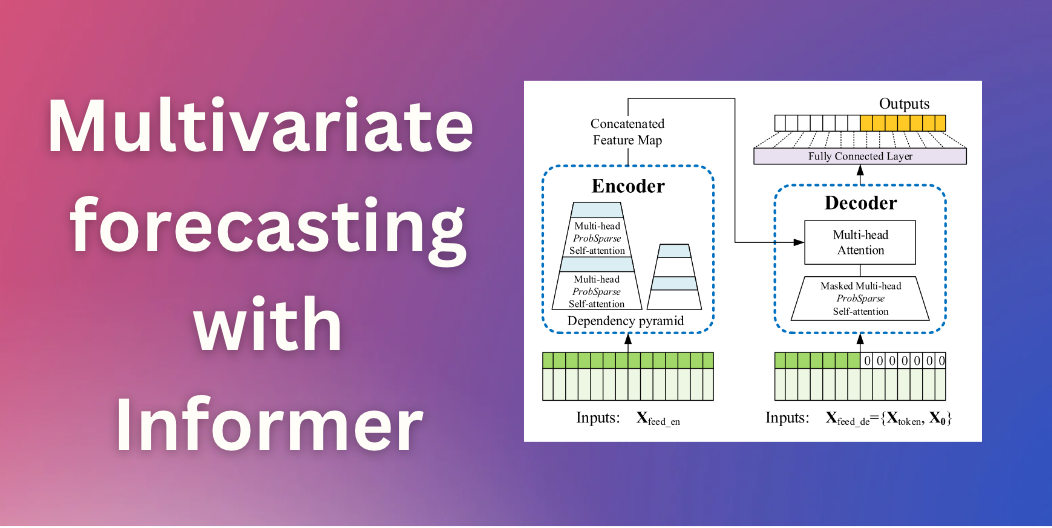
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…
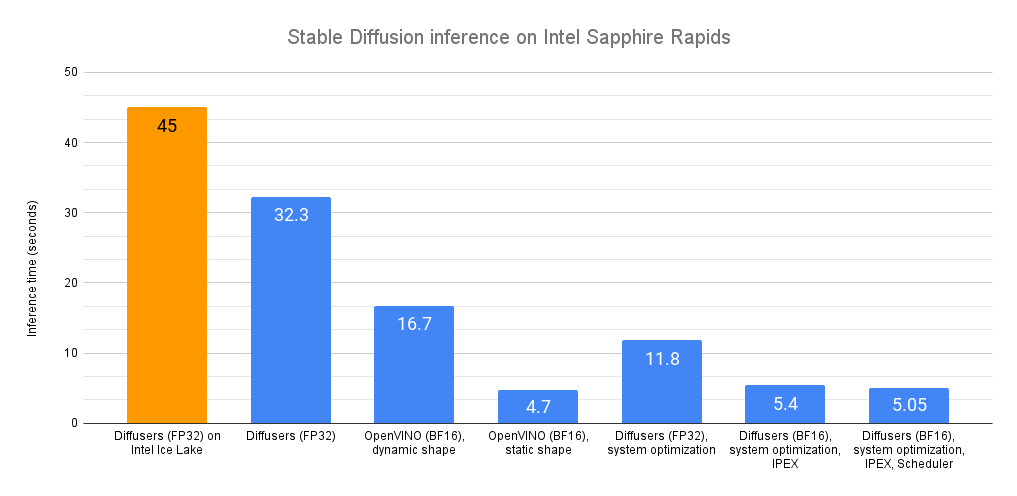
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。 RWKVプロジェクトの概要 RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。 公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html トランスフォーマーアーキテクチャとRNN RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。 RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。 トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。 トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。 推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。 RWKVアーキテクチャ RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。 RNNとトランスフォーマーの組み合わせとしてのRWKV…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.