Learn more about Search Results AMPL - Page 100

- You may be interested
- GPUマシンの構築 vs GPUクラウドの利用
- 「AIセキュリティへの6つのステップ」
- スタンフォード大学の研究者が「局所的に...
- 『検索増強生成(RAG)の評価に向けた3ス...
- CDPとAIの交差点:人工知能が顧客データプ...
- 「ChatGPTコードインタプリタは、すべての...
- Ludwig – より「フレンドリーな」デ...
- 「今日使用されているAIoTの応用」
- AI研究でα-CLIPが公開されました ターゲテ...
- 「2023年の機械学習のアンラーニング:現...
- SEER:セルフスーパーバイズドコンピュー...
- 「ゲーミングからAIへ:NvidiaのAI革命に...
- 見えない現実の暴露:アルバータ州におけ...
- 「生成AIにおけるLLMエージェントのデコー...
- LLM SaaSのためのFastAPIテンプレート パ...
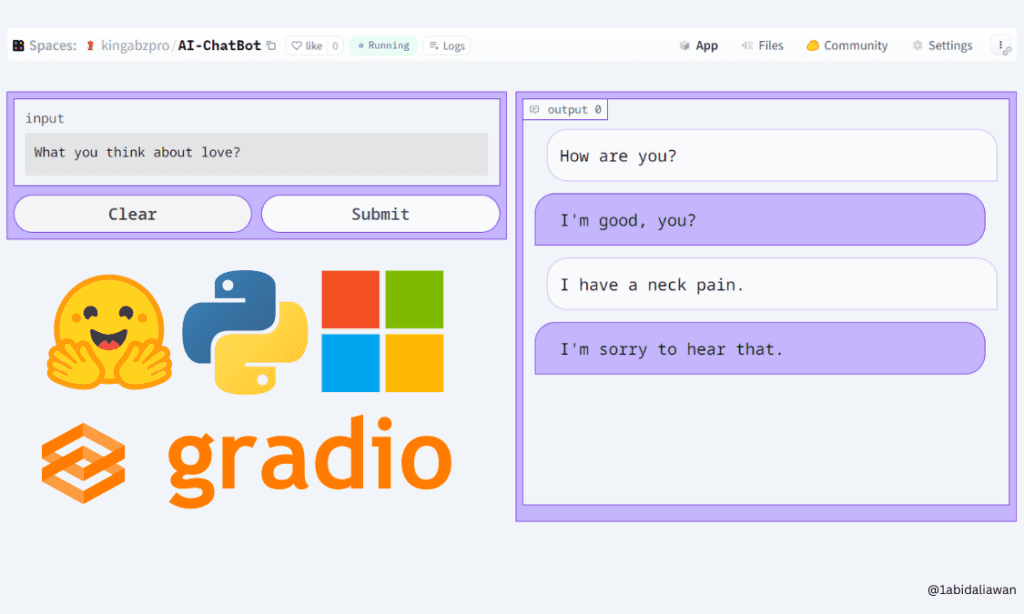
Hugging FaceとGradioを使用して、5分でAIチャットボットを構築する
この簡単なチュートリアルを使って、ブラウザ上で低コード技術を使ってGradioチャットボットを作成する方法を学びましょう
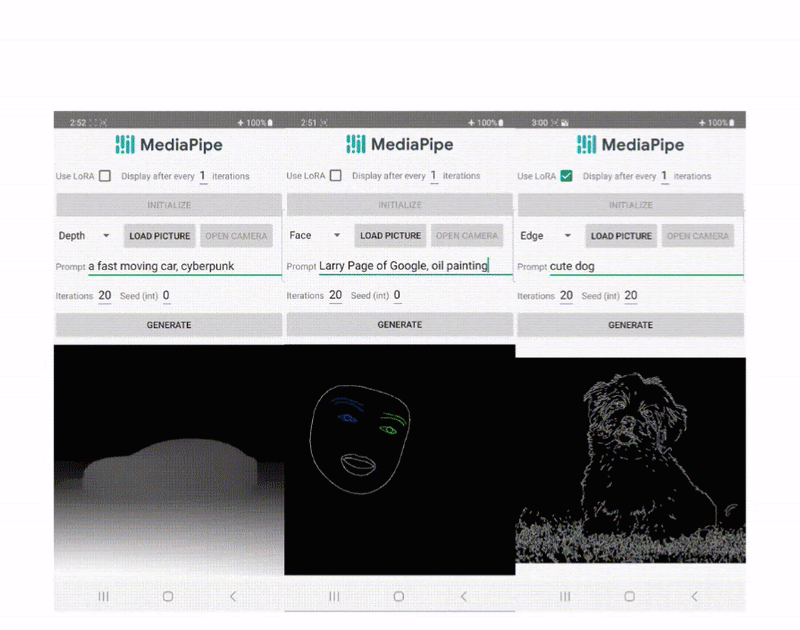
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…
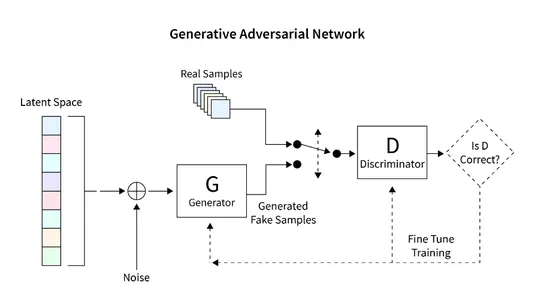
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…

QLoRAを使用して、Amazon SageMaker StudioノートブックでFalcon-40Bと他のLLMsをインタラクティブにチューニングしてください
大規模な言語モデル(LLM)の微調整により、オープンソースの基礎モデルを調整して、特定のドメインタスクでのパフォーマンスを向上させることができますこの記事では、Amazon SageMakerノートブックを使用して、最新のオープンソースモデルを微調整する利点について説明します私たちは、Hugging Faceのパラメータ効率の良い微調整(PEFT)ライブラリと、bitsandbytesを介した量子化技術を利用して、インタラクティブな微調整をサポートしています
デノイザーの夜明け:表形式のデータ補完のためのマルチ出力MLモデル
表形式のデータにおける欠損値の扱いは、データサイエンスにおける基本的な問題ですこの記事では、デノイジングに関する文献から着想を得た洗練された手法を紹介し、表形式のデータ補完においてマルチアウトプットの機械学習モデルを活用する方法を提案します
Hugging Face Datasets での作業
AIプラットフォームであるHugging Faceは、最先端のオープンソースの機械学習モデルの構築、トレーニング、展開を行いますこれらのトレーニング済みモデルをホスティングするだけでなく、Hugging Faceはデータセットもホスティングしています...

生成AIモデル:マーチャンダイジング分析のユーザーエクスペリエンス向上
私たちのデータプラットフォームで利用可能なデータについて、ビジネスユーザーが何でも尋ねることができるように、生成型AIを使用して分析体験を向上させる
機械学習システムにおけるデータ品質の維持
機械学習(ML)の眩しい世界では、洗練されたアルゴリズム、魅力的な視覚化、印象的な予測を考案する魅力に夢中になることは非常に容易です

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…
レコメンダーシステムにおけるPrecision@NとRecall@Nの解説
Accuracy Metrics(正解率指標)は、機械学習の全体的なパフォーマンスを評価するための有用な指標であり、データセット内の正しく分類されたインスタンスの割合を示します評価指標では…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.