ファルコンはHugging Faceのエコシステムに着陸しました
Falcon has landed in the Hugging Face ecosystem.
イントロダクション
ファルコンは、アブダビのテクノロジーイノベーション研究所が作成し、Apache 2.0ライセンスの下で公開された最新の言語モデルの新しいファミリーです。 特筆すべきは、Falcon-40Bが多くの現在のクローズドソースモデルと同等の機能を持つ、初めての「真にオープンな」モデルであることです 。これは、開発者、愛好家、産業界にとって素晴らしいニュースであり、多くのエキサイティングなユースケースの扉を開くものです。
このブログでは、ファルコンモデルについて詳しく調査し、まずそれらがどのようにユニークであるかを説明し、その後、Hugging Faceのエコシステムのツールを使ってそれらの上に構築することがどれほど簡単かを紹介します。
目次
- ファルコンモデル
- デモ
- 推論
- 評価
- PEFTによるファインチューニング
- 結論
ファルコンモデル
ファルコンファミリーは、2つのベースモデルで構成されています:Falcon-40Bとその弟であるFalcon-7Bです。 40Bパラメータモデルは現在、Open LLM Leaderboardのトップを占めており、7Bモデルはそのクラスで最高のモデルです 。
Falcon-40BはGPUメモリを約90GB必要としますが、それでもLLaMA-65Bよりは少なく、Falconはそれを上回します。一方、Falcon-7Bは約15GBしか必要とせず、推論やファインチューニングは一般的なハードウェアでも利用可能です。 (このブログの後半では、より安価なGPUでもFalcon-40Bを利用できるように、量子化を活用する方法について説明します!)
- Hugging Face Hubへ、fastText をようこそお迎えください
- ギャラリー、図書館、アーカイブ、博物館向けのHugging Face Hub
- はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
TIIはまた、モデルのInstructバージョンであるFalcon-7B-InstructとFalcon-40B-Instructを提供しています。これらの実験的なバリアントは、命令と会話データに適応された調整が行われているため、人気のあるアシスタントスタイルのタスクに適しています。 モデルを素早く試してみたい場合は、これらが最適な選択肢です。 コミュニティによって構築された多くのデータセットに基づいて、独自のカスタムInstructバージョンを作成することも可能です。ステップバイステップのチュートリアルについては、読み続けてください!
Falcon-7BとFalcon-40Bは、それぞれ1兆5000億トークンと1兆トークンでトレーニングされており、推論を最適化するための現代のモデルに合わせています。 Falconモデルの高品質の主要な要素は、トレーニングデータであり、主にCommonCrawlに基づく新しい大規模なウェブデータセットであるRefinedWebに基づいています 。散在するキュレーションされたソースを収集する代わりに、TIIはWebデータのスケーリングと品質改善に焦点を当て、大規模な重複排除と厳格なフィルタリングを活用して、他のコーパスの品質に匹敵する品質にすることに注力しています。ファルコンモデルには、Redditの会話データなどの一部のキュレーションされたソースも含まれていますが、GPT-3やPaLMなどの最先端のLLMに一般的に見られるより少ない割合です。最高の部分は何でしょうか?TIIは、コミュニティが独自のLLMに使用するために、RefinedWebの6000億トークンの抜粋を公開しています!
ファルコンモデルのもう1つの興味深い特徴は、マルチクエリアテンションの使用です。通常のマルチヘッドアテンションスキームでは、各ヘッドごとに1つのクエリ、キー、値がありますが、マルチクエリはキーと値をすべてのヘッドで共有します。
このトリックは事前トレーニングには大きな影響を与えませんが、自己回帰デコーディング中に保持されるK、Vキャッシュは、大幅に小さくなります (アーキテクチャの具体的な要素に応じて10〜100倍)。これにより、メモリコストが削減され、状態保持などの新しい最適化が可能になります。
* ベースバージョンのスコアは利用できませんが、代わりにチューニングバージョンを報告します。
このスペースまたは以下に埋め込まれたプレイグラウンドで、簡単にBig Falcon Model(400億のパラメータ!)を試すことができます:
このプレイグラウンドでは、Hugging Faceのテキスト生成インファレンスを使用しています。これは、高速かつ効率的なテキスト生成のためのスケーラブルなRust、Python、gRPCサーバーです。これはHuggingChatにも使用されている同じ技術です。
また、7B InstructモデルのCore MLバージョンも作成しました。以下は、M1 MacBook Proでの動作例です:
ビデオ:Core MLで実行されるFalcon 7B Instruct、M1 MacBook Pro 上での動画。
このビデオでは、モデルのロード、トークン化、入力の準備、生成、デコードなどの重い作業を行うためのSwiftライブラリを活用した軽量アプリが示されています。私たちはこのライブラリを作成中で、開発者が車輪を再発明することなく強力なLLMをさまざまなアプリケーションに統合できるようにすることを目指しています。まだ少し荒いですが、お楽しみに。それまで、リポジトリからCore MLのウェイトをダウンロードして自分で探索することもできます!
独自のハードウェア上でモデルを実行するためには、おなじみのtransformers APIを使用できますが、以下の詳細に注意する必要があります:
- モデルは
bfloat16データ型を使用してトレーニングされているため、同じデータ型を使用することをおすすめします。これには最新バージョンのCUDAが必要で、最新のカードで最も効果的です。また、float16を使用して推論を実行することもできますが、モデルの評価はbfloat16を使用して行われたことを念頭に置いてください。 - リモートコードの実行を許可する必要があります。これは、モデルがまだ
transformersの一部ではない新しいアーキテクチャを使用しているためです。代わりに、モデルの作者がリポジトリで提供する必要なコードが使用されます。具体的には、リモート実行を許可する場合に使用されるファイルは次のとおりです(例としてfalcon-7b-instructを使用):configuration_RW.py、modeling_RW.py。
これらの考慮事項を踏まえて、次のようにtransformersのpipelineAPIを使用して7Bのinstructionモデルをロードできます:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)そして、次のようなコードを使用してテキスト生成を実行します:
sequences = pipeline(
"バレンシアについての詩を書いてください。",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"結果: {seq['generated_text']}")以下のような結果が得られるかもしれません:
太陽の都市、バレンシア
星のように光り輝く都市
千の色の都市
夜は星で照らされる都市
私の心の都市、バレンシア
過去が黄金の箱に保たれる都市Falcon 40Bの推論
40Bモデルの実行は、サイズのために困難です:80 GBのRAMを持つ単一のA100に収まりません。8ビットモードでロードすると、約45 GBのRAMで実行できますが、これはA6000(48 GB)には収まりますが、A100の40 GBバージョンには収まりません。以下に実行方法を示します:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)ただし、混合8ビット推論ではtorch.bfloat16の代わりにtorch.float16が使用されるため、結果を十分にテストすることを確認してください。
複数のカードとaccelerateがインストールされている場合、device_map="auto"を使用してモデルレイヤーを自動的に複数のカードに分散させることができます。必要に応じて一部のレイヤーをCPUにオフロードすることもできますが、これは推論速度に影響を与えます。
また、bitsandbytes、transformers、accelerateの最新バージョンを使用して4ビットのロードを行うことも可能です。この場合、40Bモデルは約27 GBのRAMを使用します。ただし、これは3090や4090などのカードの利用可能なメモリよりもわずかに多いですが、30 GBまたは40 GBのカードで実行するには十分です。
テキスト生成の推論
テキスト生成の推論は、大規模言語モデルの簡単なデプロイメントを可能にするためにHugging Faceが開発した本番用の推論コンテナです。
主な特徴は次のとおりです:
- 連続バッチ処理
- Server-Sent Events(SSE)を使用したトークンストリーミング
- 複数のGPUでの高速な推論のためのテンソル並列処理
- カスタムCUDAカーネルを使用した最適化されたtransformersコード
- PrometheusとOpen Telemetryを使用した本番用のログ記録、モニタリング、トレース
バージョン0.8.2以降、テキスト生成推論は、Transformersの「リモートコードを信頼する」機能に依存せずに、Falcon 7bおよび40bモデルをネイティブでサポートしており、完全な展開とセキュリティ監査が可能です。また、Falconの実装には、エンドツーエンドのレイテンシを大幅に減少させるためのカスタムCUDAカーネルも含まれています。
テキスト生成推論は、現在Hugging Faceの推論エンドポイントに統合されています。Falconモデルを展開するには、モデルページに移動し、デプロイ->推論エンドポイントウィジェットをクリックします。
7Bモデルの場合、”GPU [VoAGI] – 1x Nvidia A10G”を選択することをお勧めします。
40Bモデルの場合、”GPU [xlarge] – 1x Nvidia A100″で展開し、量子化を有効にする必要があります。詳細な設定->サービングコンテナ->Int-8量子化。注意:[email protected]にメールでクォータのアップグレードをリクエストする必要がある場合があります。
評価
Falconモデルはどれくらい優れているのでしょうか?Falconの作者による詳細な評価は近日中に公開されますが、その間に、ベースモデルとインストラクトモデルの両方を私たちのオープンLLMベンチマークに実行しました。このベンチマークは、LLMの推論能力と以下のドメインでの真実の回答を提供する能力の両方を測定します:
- AI2 Reasoning Challenge (ARC):小学校の選択肢科学の問題。
- HellaSwag:日常のイベントに関する常識的な推論。
- MMLU:57の科目(専門的および学術的)の多肢選択問題。
- TruthfulQA:モデルが間違った文から事実を分離する能力をテストします。
結果は、40Bのベースモデルとインストラクトモデルが非常に強力であり、現在LLMリーダーボードで1位と2位にランクインしていることを示しています🏆!
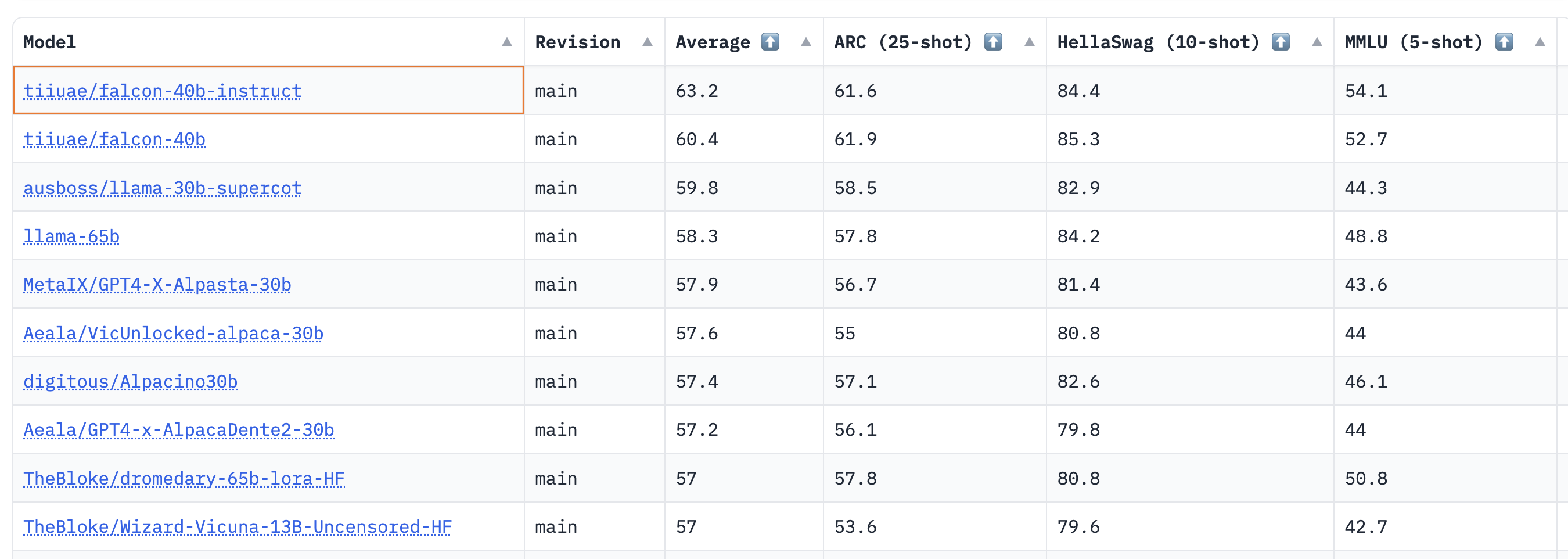
Thomas Wolfによると、ここで驚くべき洞察力の一つは、40BモデルがLLaMa 65Bの約半分の計算で事前学習されていること(2800 vs 6300ペタフロップデイ)であり、これはLLMの事前学習において「最適」とされる限界にまだ達していないことを示唆しています。
7Bモデルの場合、ベースモデルはよりも優れており、MosaicMLのを上回って、このスケールで現在の最高の事前学習LLMとなっています。リーダーボードからの人気モデルのショートリストを以下に再掲します:
オープンLLMリーダーボードはチャット機能を測定していないため(人間の評価がゴールドスタンダードです)、Falconモデルのこれらの予備的な結果は非常に励みになります!
さあ、自分自身のFalconモデルをファインチューニングする方法を見てみましょう – おそらくあなたのモデルのうちの1つがリーダーボードのトップになるかもしれません🤗。
PEFTでのファインチューニング
10B+サイズのモデルのトレーニングは技術的にも計算的にも困難です。このセクションでは、Hugging Faceエコシステムで利用可能なツールを見て、単一のNVIDIA T4(16GB – Google Colab)上で非常に大きなモデルを効率的にトレーニングする方法を示します。
まずは、Guanacoデータセット上でFalconをトレーニングしてみましょう。これはOpen Assistantデータセットの高品質なサブセットで、約10,000の対話からなります。PEFTライブラリを使用して、凍結された4ビットモデルの上に配置されたアダプタをファインチューニングするための最近のQLoRAアプローチを使用することができます。4ビット量子化モデルの統合については、このブログポストで詳しく説明しています。
Low Rank Adapters(LoRA)を使用する場合、学習可能なパラメーターの数とトレーニングされたアーティファクトのサイズは劇的に削減されます。以下のスクリーンショットに示すように、保存されたモデルは7Bパラメーターモデルの場合、わずか65MBしかありません(float16では15GBです)。
具体的には、適応対象のモジュールを選択した後(実際にはアテンションモジュールのクエリ/キーレイヤー)、これらのモジュールに近い位置に小さな学習可能な線形層を付け加えます(以下の図で示されています)。アダプタによって生成された隠れ状態は、最終的な隠れ状態を得るために元の状態に追加されます。
トレーニングが完了したら、ベースモデルを保存する必要はありません。また、出力される隠れ状態がアダプタからの隠れ状態と同じdtypeにキャストされる限り(int8、fp4、fp16など)、モデルを任意のdtype(int8、fp4、fp16など)で保持することも可能です。これはbitsandbytesモジュール(Linear8bitLtおよびLinear4bit)の場合であり、これらのモジュールは元の未量子化モジュールと同じdtypeの隠れ状態を返します。
私たちは、GuanacoデータセットでFalconモデルの2つのバリアント(7Bおよび40B)を微調整しました。7Bモデルは単一のNVIDIA-T4 16GBで、40Bモデルは単一のNVIDIA A100 80GBで微調整しました。4ビット量子化されたベースモデルとQLoRAメソッド、そしてTRLライブラリからの最新のSFTTrainerも使用しました。
PEFTを使用して実験を再現するための完全なスクリプトはこちらで入手できますが、SFTTrainerを簡単に実行するためにはわずか数行のコードのみが必要です(PEFTなし):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()訓練済みモデルの評価に関する詳細は、オリジナルのqloraリポジトリを参照してください。
ファインチューニングのリソース
- Colabノートブック:4ビットとPEFTを使用してGuanacoデータセットでFalcon-7Bをファインチューニングする
- トレーニングコード
- 40Bモデルのアダプター(ログ)
- 7Bモデルのアダプター(ログ)
結論
Falconは商業アプリケーションに使用できる興味深い新しい大規模言語モデルです。このブログポストでは、その機能、自分の環境での実行方法、およびHugging Faceエコシステム内でのカスタムデータのファインチューニングの容易さを紹介しました。コミュニティがそれを活用して何を構築するかを楽しみにしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






